
- 0
- 0
- 0
分享
- 微软论文一张截图,曝出GPT-3.5仅有200亿参数?AI圈巨震,网友大呼太离谱!
-
2023-10-31

新智元报道
新智元报道
【新智元导读】微软最近一篇论文爆料,GPT-3.5的参数量只有20B,远远小于之前GPT-3公布175B。网友表示,ChatGPT能力似乎「配得上」这个体量?
GPT-3.5只有200亿参数?
今天,大模型圈都被微软论文中的一纸截图刷爆了,究竟是怎么回事?
就在前几天,微软发表了篇论文并挂在了arXiv上,该论文提出了一个参数量只有75M的小规模扩散模型——CodeFusion。
性能方面,7500万参数的CodeFusion在top-1准确率指标上,可以与最先进的350M-175B模型相媲美。

论文地址:https://arxiv.org/abs/2310.17680
这篇论文的工作很有意义,但引起大家格外注意的却是——
作者在对比ChatGPT(gpt-3.5-turbo)时,标称的参数量竟然只有20B!
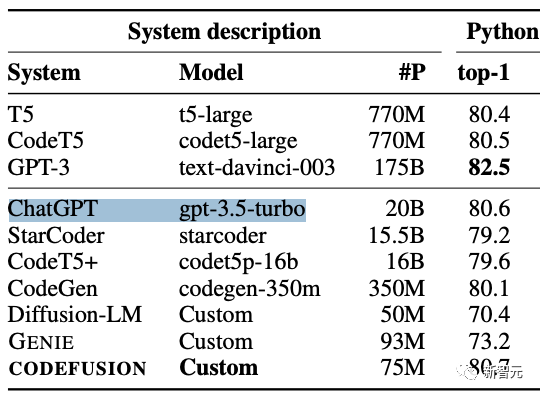
在此之前,大家针对GPT-3.5参数量的猜测都是1750亿,这相当于是缩减了差不多十倍!

根据这篇论文的爆料,网友还去维基百科上更新了GPT-3.5的介绍,直接把参数大小改成了20B。


是「乌龙」还是「事实」?
目前,已经有超过68万人前来围观。
这位老哥表示,论文的几位作者也都在用推特,估计过不了多久就会亲自下场解释。

而对于这个神秘的「20B」,网友们也是众说纷纭。

有人猜测,这很可能是作者手误打错了。比如原本是120B,或者200B。

结合现实中的各项评测来看,确实有很多小模型能够取得和ChatGPT差不多的成绩,比如Mistral-7B。

也许,这也是侧面证实了GPT-3.5体量真的不大。
很多网友也认为20B的参数可能是准确的,纷纷发出感叹:
「这也太难以想象了!Falcon-180B和Llama2-70B,竟然都无法击败这款20B的模型。」

也有网友认为,gpt-3.5-turbo是精炼版的gpt-3.5。
而这次参数的「泄露」,正好从侧面印证了那些关于gpt-3.5-turbo表现不如旧版gpt-3.5的传言。

不过,根据OpenAI的官方文档,除了已经不再使用的text-davinci和code-davinci,GPT-3.5家族全员都是基于gpt-3.5-turbo构成的。



微软发布CodeFusion
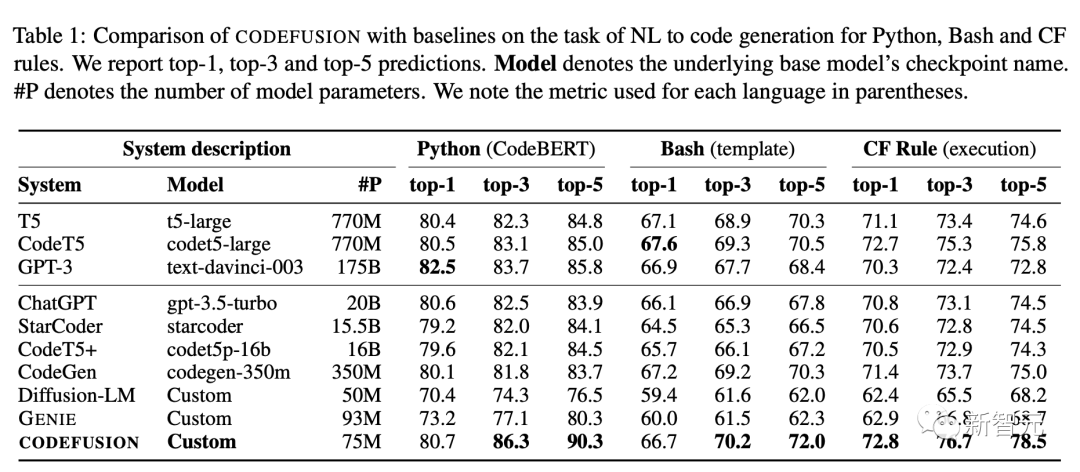
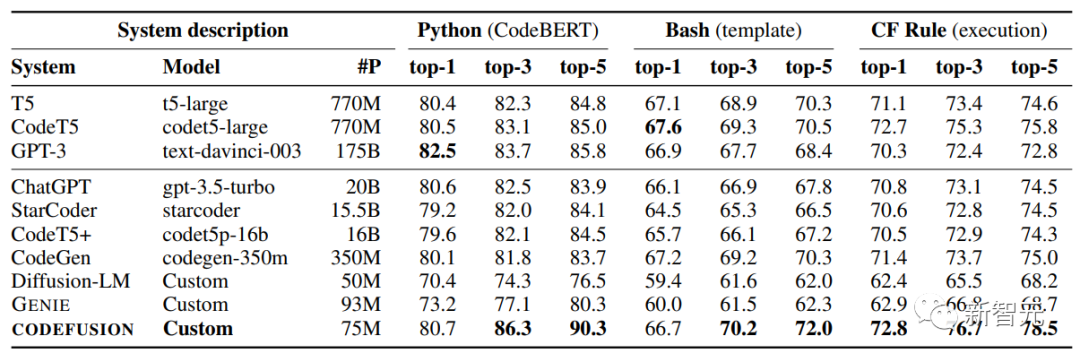
研究人员针对Bash、Python和Microsoft Excel条件格式(CF)规则的自然语言生成代码的任务来评估这个模型——CodeFusion。
实验表明,CodeFusion(只有75M参数)在top-1精度方面与最先进的LLM(350M-175B参数)相当,并且在top-3和top-5精度方面性能和参数比非常优秀。
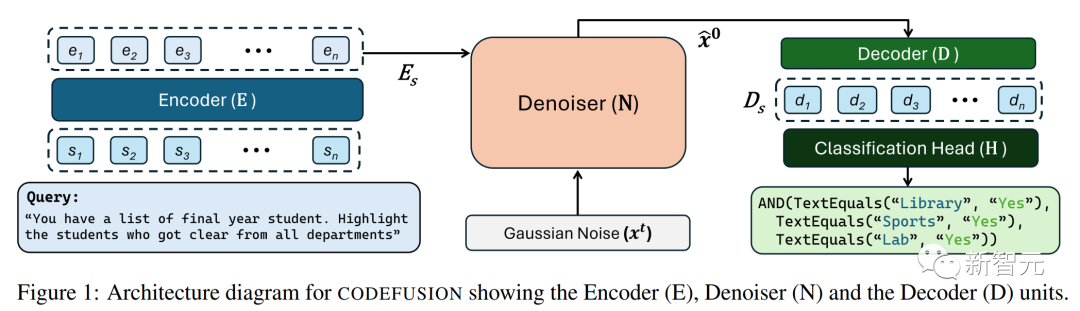
在第一阶段,CODEFUSION使用未标记的代码片段来训练降噪器和解码器。它还使用可训练的嵌入层L,将代码片段嵌入到连续空间中。
在第二阶段,CODEFUSION进行有监督的微调,使用来自文本-代码对数据。在这个阶段,编码器、降噪器和解码器都会得到调整,以更好地执行任务。
此外,CODEFUSION还借鉴了之前有关文本扩散的研究成果,将来自解码器的隐藏表示D融合到模型中。这是为了改进模型的性能。在训练过程中,在不同step中,模型引入一些噪声,然后计算损失函数,以确保生成的代码片段更符合预期的标准。
总之,CODEFUSION是一个执行代码生成工作的小模型,通过两个阶段的训练和噪声引入来不断提升其性能。这个模型的灵感来自于文本扩散的研究,并通过融合解码器的隐藏表示来改进损失函数,以更好地生成高质量的代码片段。
评估结果
在top-1中,CODEFUSION的性能与自回归模型相媲美,甚至在某些情况下表现更出色,尤其是在Python任务中,只有GPT-3(175B)的性能稍微优于CODEFUSION(75M)。然而,在top-3和top-5方面,CODEFUSION明显优于所有基线模型。
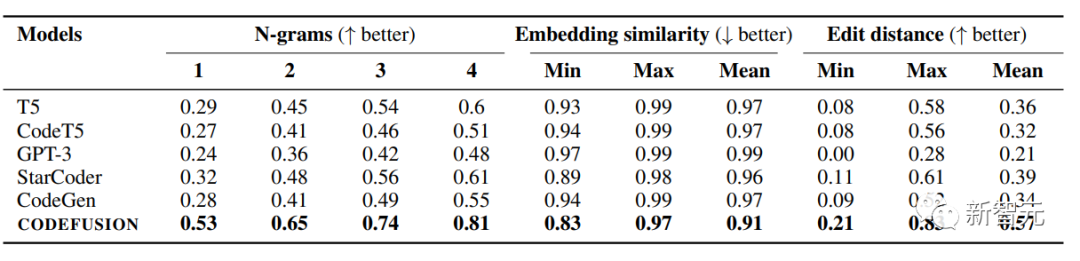
表下表展示了CODEFUSION和自回归模型(包括T5、CodeT5、StarCoder、CodeGen、GPT-3)在各项基准任务上的平均多样性结果,考察了每个模型的前5代生成结果。
相对于自回归模型,CODEFUSION生成更加多样化的结果,表现更出色。
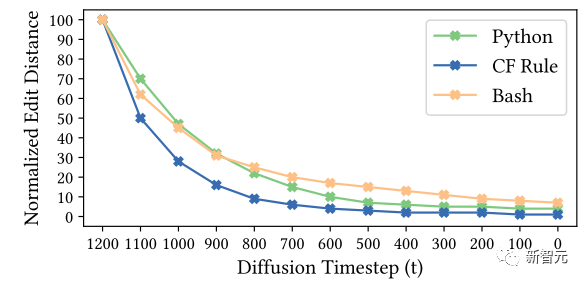
在消融实验中,作者停止了去噪过程,并生成了在时间步t∈[0, T]范围内的当前状态的代码片段。利用归一化字符串编辑距离来衡量每个时间步长(每100步为一个增量)所获得的结果。
这一方法有助于总结和展示CODEFUSION模型的逐步进展,如下图所示。
说了这么多,GPT-3.5的参数量到底是多少?GPT-4与GPT-3.5在技术和其他方面有着什么样的联系?
GPT-3.5是一个个小专家模型的集成还是一个通才模型?是通过更大模型的蒸馏还是更大数据训练?
这些问题的答案只能等到真正开源的时候才能揭晓了。
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号新智元 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
-

-
北京
甲方 · 媒体平台
未认证的机构号
recently released
-
2023-12-14
-
2023-11-03











