
- 0
- 0
- 0
分享
- 上下文学习=对比学习?人大揭示ICL推理背后的隐式更新机理:梯度更新了吗?「如更」
-
2023-11-03

新智元报道
新智元报道
【新智元导读】人民大学最新研究,首次从「对比学习」的角度来理解上下文学习,或可提供自注意力机制的改进思路。

研究人员先利用核方法在常用的softmax注意力下建立了梯度下降和自注意机制之间的关系,而非线性注意力;
然后在无负样本对比学习的角度上,对ICL中的梯度下降过程进行分析,并讨论了可能的改进方式,即对自注意力层做进一步修改;
最后通过设计实验来支持文中提出的观点。
研究团队表示,这项工作是首次从对比学习的角度来理解ICL,可以通过参考对比学习的相关工作来促进模型的未来设计思路。
背景与动机
相较于有监督学习下的微调,大模型在ICL推理过程中并不需要显式的梯度更新,即可学习到示例样本中的信息并输出对于查询问题的答案,基于Transformer的大模型是如何实现这一点的呢?
方法
作者首先假设模型输入的token由若干示例样本的token以及最后的查询token组成,每个token由 {问题, 标签} 的embedding拼接而成,其中,查询token的标签部分设置为0,即
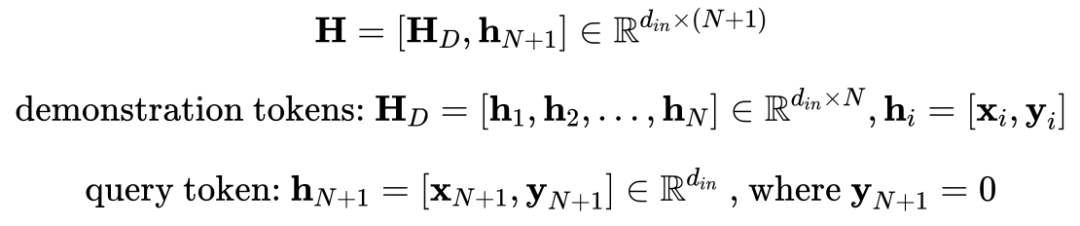

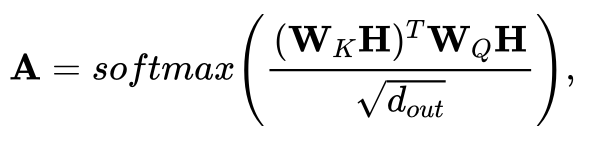
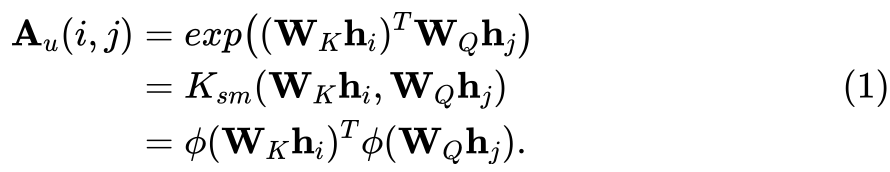
作者指出参考模型的该输出会与注意力机制下的推理输出严格等价,即参考模型在对应数据集以及余弦相似损失上进行一步随机梯度下降后,得到的测试输出会与注意力机制下得到的输出是严格相等的。
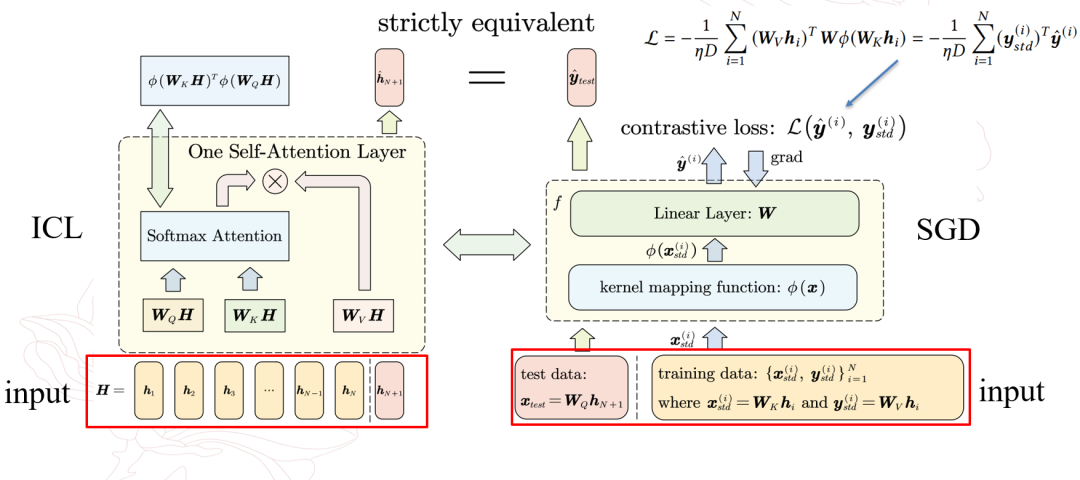
而参考模型则是相当于需要学习潜在表征的encoder,其将映射后的K向量先投影到高维空间学习深层表征,然后再映射回原来的空间与V向量进行对比损失的计算,以使得两者的尽可能的相似。
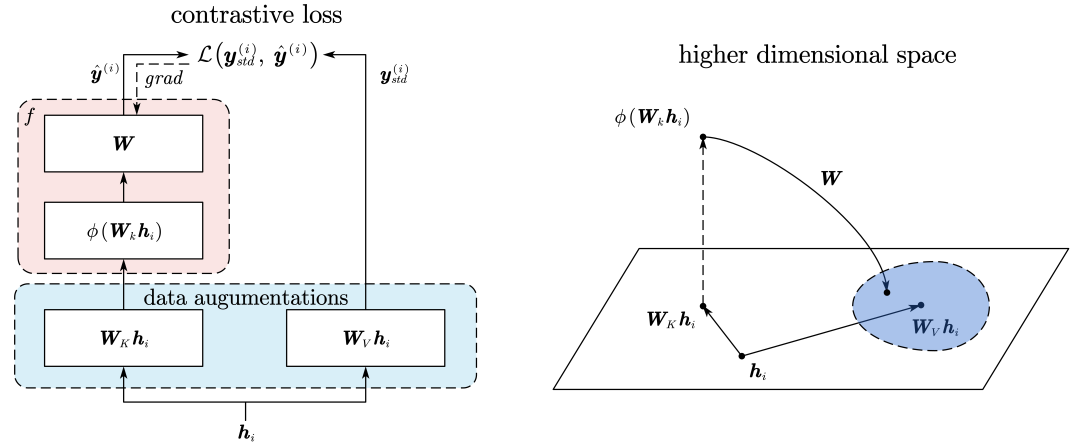
正则化的损失函数
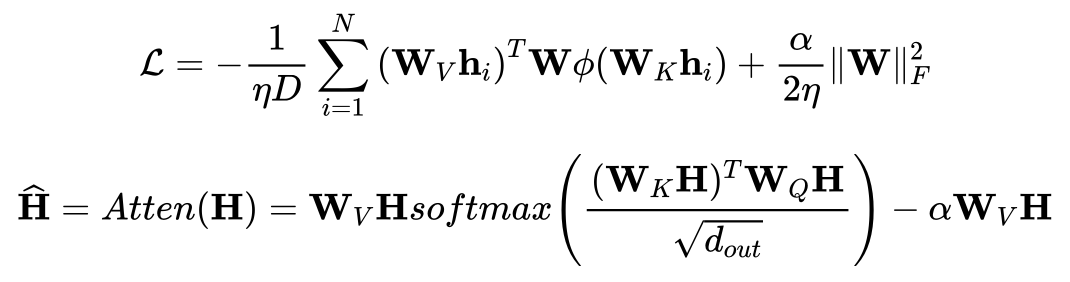
数据增强
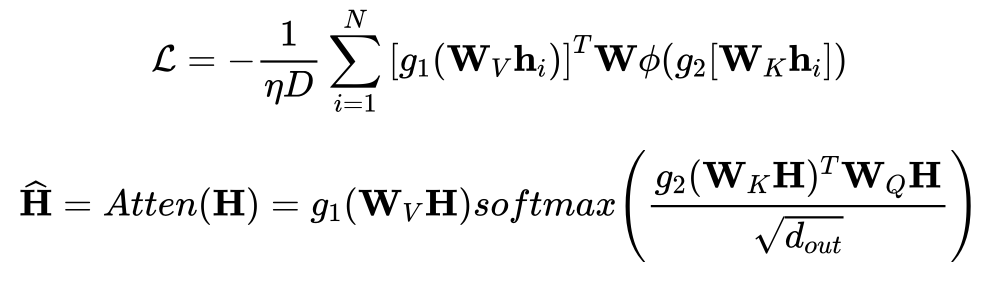
增加负样本
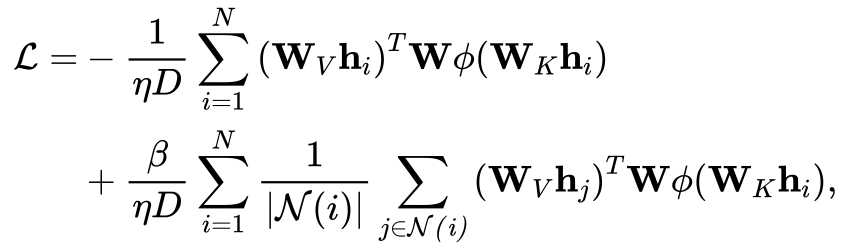
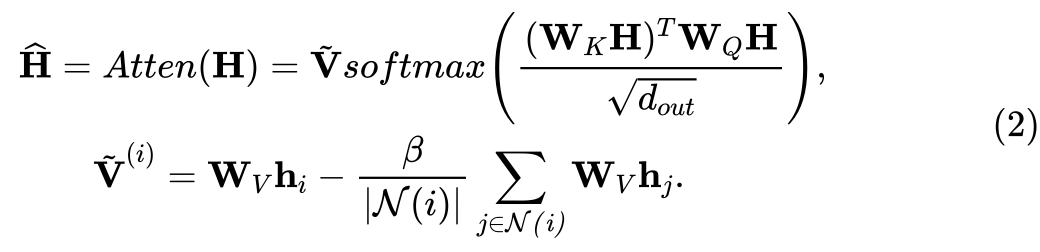
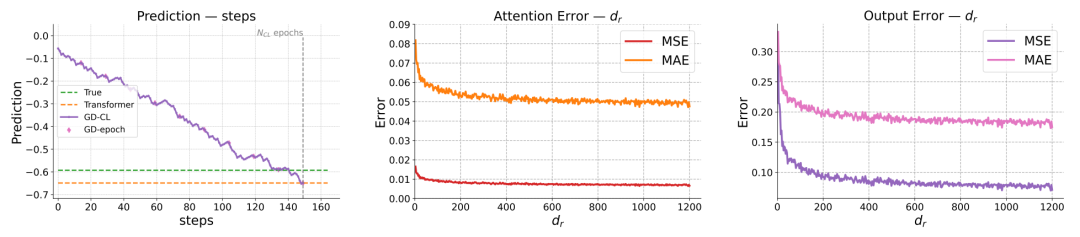
实验
实验部分中,作者在线性回归任务上设计了仿真实验,说明了注意力机制下的推理过程与参考模型上进行梯度下降过程的等价性,即单层注意力机制下得到的推理结果,严格等价于参考模型在对比损失loss上进行一步梯度下降后的测试输出。
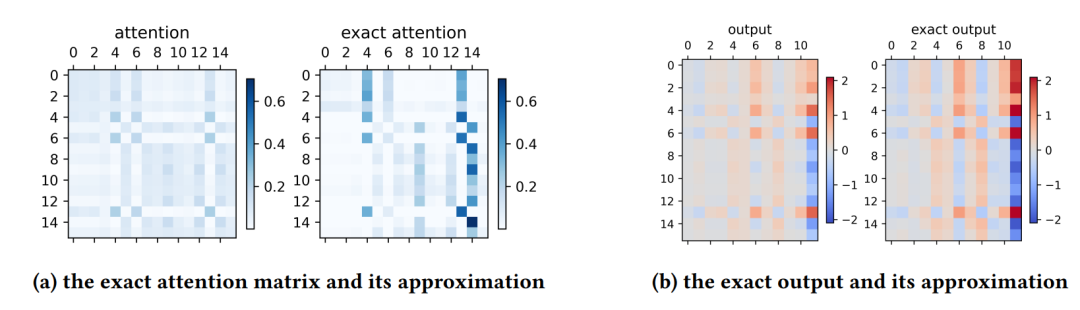
实验图2
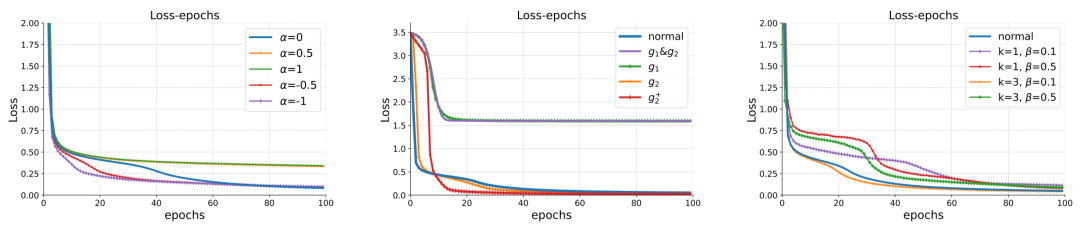
实验图3
总结与未来展望
作者在不依赖于线性注意力假设以及权重构造的方法下,探究了ICL的隐式更新机理,建立了softmax注意力机制推理过程与梯度下降的等价关系,并进一步提出了从对比学习的视角下看待注意力机制推理过程的新框架。
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号新智元 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接:https://www.d-arts.cn/article/article_info/key/MTIwNjY5OTIwNTeEqYFmr4a0cw.html 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
-

-
北京
甲方 · 媒体平台
未认证的机构号
recently released
-
2023-12-14
-
2023-11-03











