
- 0
- 0
- 0
分享
- 开源本地化部署的「妙鸭相机」,真的要革了「海马体」们的命了?|手把手教你搭建「妙鸭相机」
-
2023-09-19

新智元报道
新智元报道
【新智元导读】EasyPhoto作为妙鸭相机平替,有着不输妙鸭相机的生成质量,还有更好的定制化空间和本地部署的优势。
年初由ChatGPT引发的AI浪潮奔涌至今,除了OpenAI推出的当红炸子鸡之外,中文互联网内热度最高的产品,非前段时间霸屏的「妙鸭相机」莫属了。
只要上传20张自己的自拍照,就可以拥有一个专属的数字分身。用户只用挑选自己喜爱的写真模板,就可以得到一张张专业质感的写真。(9块9的体验售价)

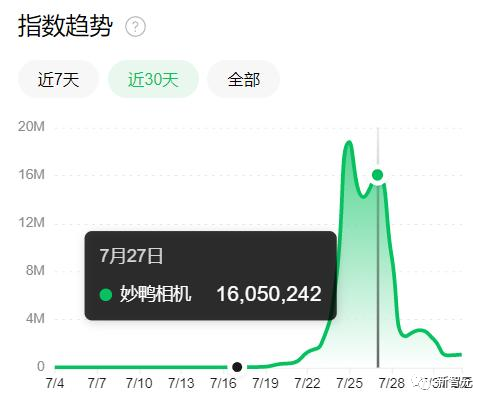
最高峰的时候,用户交了钱之后需要等接近10个小时才能获得自己的数字分身和写真。网传一个月流水超过1000万人民币。
但从上边的「妙鸭相机」搜索趋势图也能看出来,网红产品的宿命,很难逃开「火速蹿红」+「极速陨落」。
因为用户协议中关于用户数据极为离谱的「霸王条款」,加上傲慢的「不予退款」政策,爆火之后的妙鸭相机很快就被负面舆论反噬,热度也迅速下滑。
而如果用户能在本地部署一个「妙鸭相机」,就能完全不用忍受高峰期长达数个小时的「排队取照」,也完全不用担心自己的照片和用户数据被开发者滥用。
由国内一个团队推出的EasyPhoto,就瞄准了这个痛点,在Github上开源了一个由Stable Diffusion作为基础,开源且支持本地化部署的「妙鸭相机」。

同样也是通过5-20张自己照片的训练,本地部署的模型就能通过EasyPhoto推理出堪比「妙鸭相机」的写真风照片。

而且相比于妙鸭相机,它还支持生成多人的照片。同时,用户还可以自己选择除了SD之外的其他模型来生成写真照片。
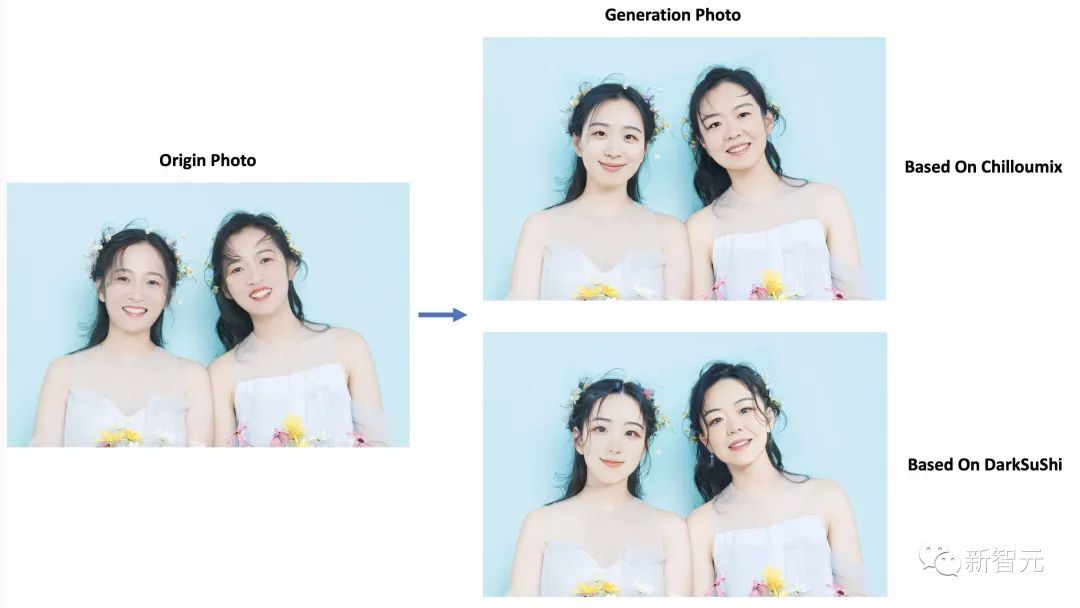
对于那些动手能力强的用户,EasyPhoto相当于一个加强版且免费的妙鸭相机。
甚至,只要自己有足够的算力资源,这个通用的「AI写真生成框架」可以直接向其他用户提供和妙鸭相机类似的AIGC服务。
使用指南
模型训练
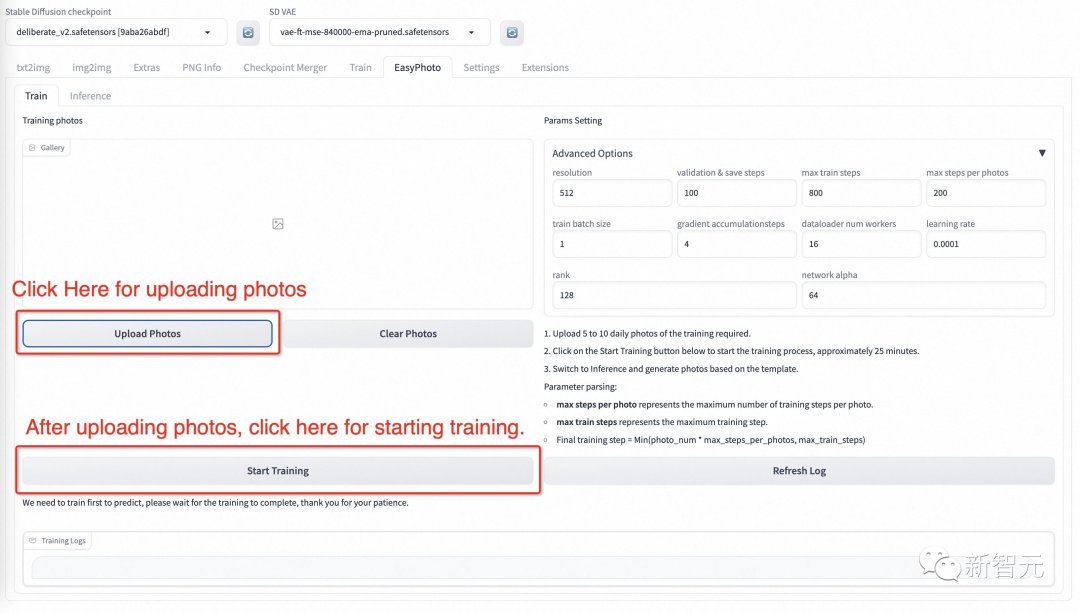
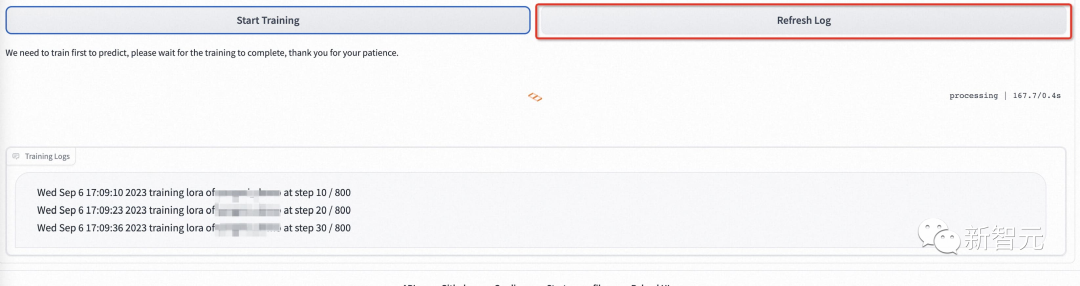
左边是训练图像,只需点击上传照片即可上传图片,点击清除照片即可删除上传的图片; 右边是训练参数,不能为第一次训练进行调整。
点击上传照片后,用户就可以开始上传图像这里最好上传5到20张图像,包括不同的角度和光照。最好有一些不包括眼镜的图像。如果所有图片都包含眼镜眼镜,则生成的结果可以容易地生成眼镜。
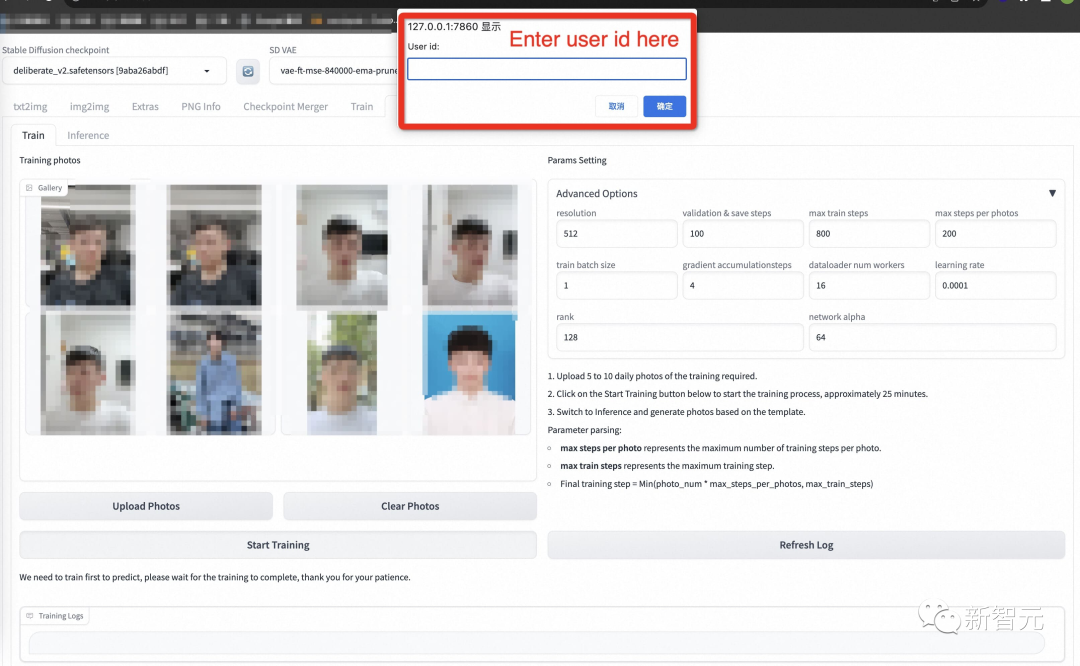
然后点击下面的「开始训练」,此时,需要填写上面的用户ID,例如用户名,才能开始培训。
模型开始训练后,webui会自动刷新训练日志。如果没有刷新,请单击「Refresh Log」按钮。
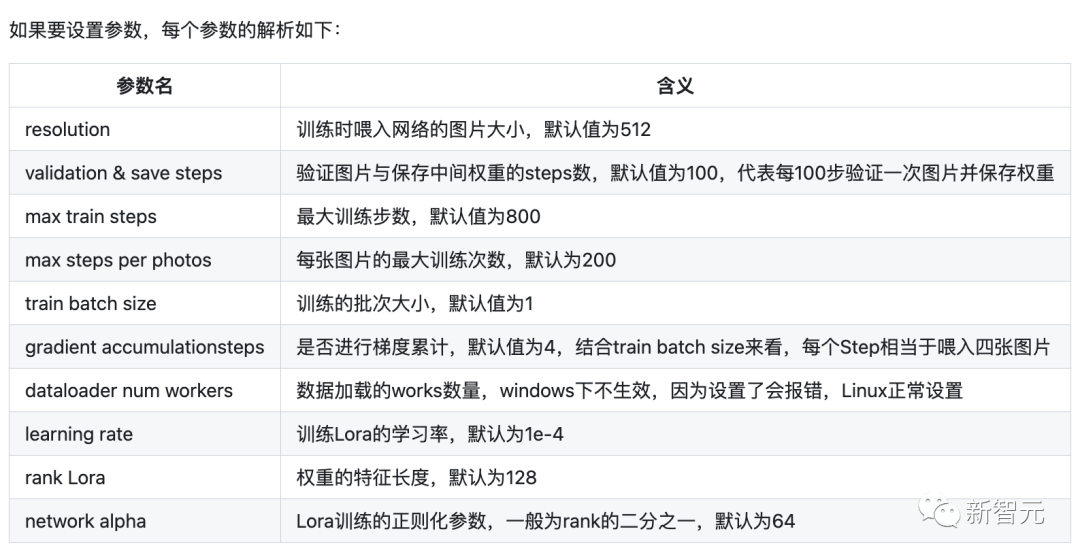
如果要设置参数,每个参数的解析如下:
2.人物生成
a.单人模版
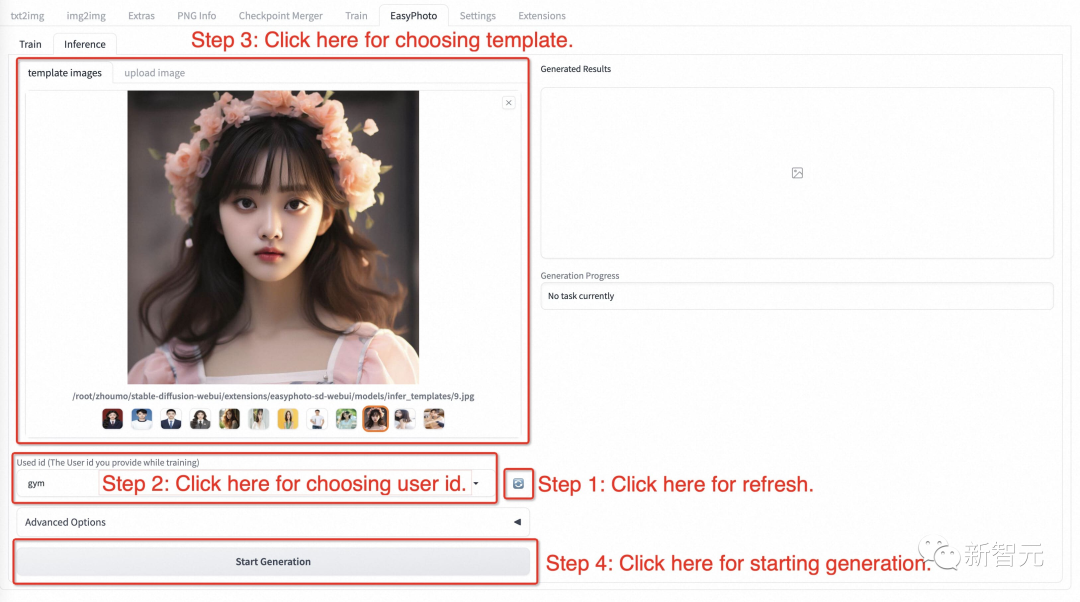
步骤1:点击刷新按钮,查询训练后的用户ID对应的模型。 步骤2:选择用户ID。 步骤3:选择需要生成的模板。 步骤4:单击「生成」按钮生成结果。
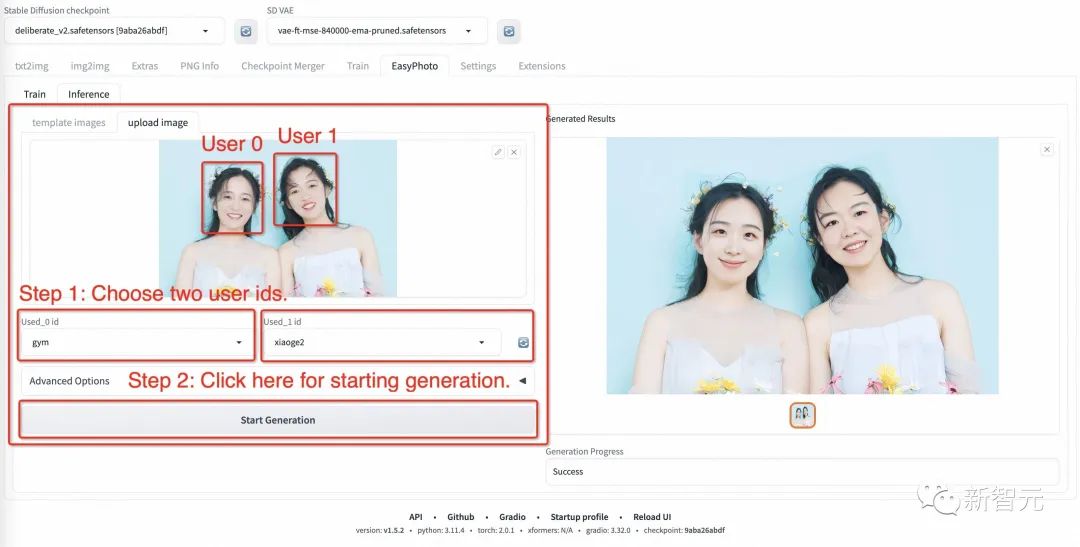
b.多人模板
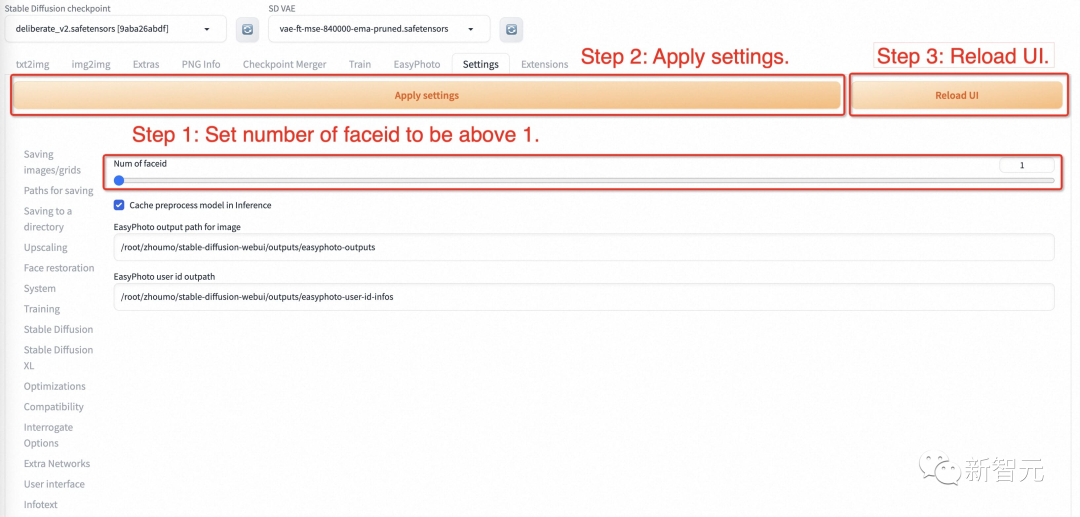
步骤1:转到EasyPhoto的设置页面,设置num_of_Faceid大于1。
步骤2:应用设置。 步骤3:重新启动webui的ui界面。 步骤4:返回EasyPhoto并上传多人模板。 步骤5:选择两个人的用户ID。 步骤6:单击「生成」按钮。执行图像生成。
算法详细信息
架构概述
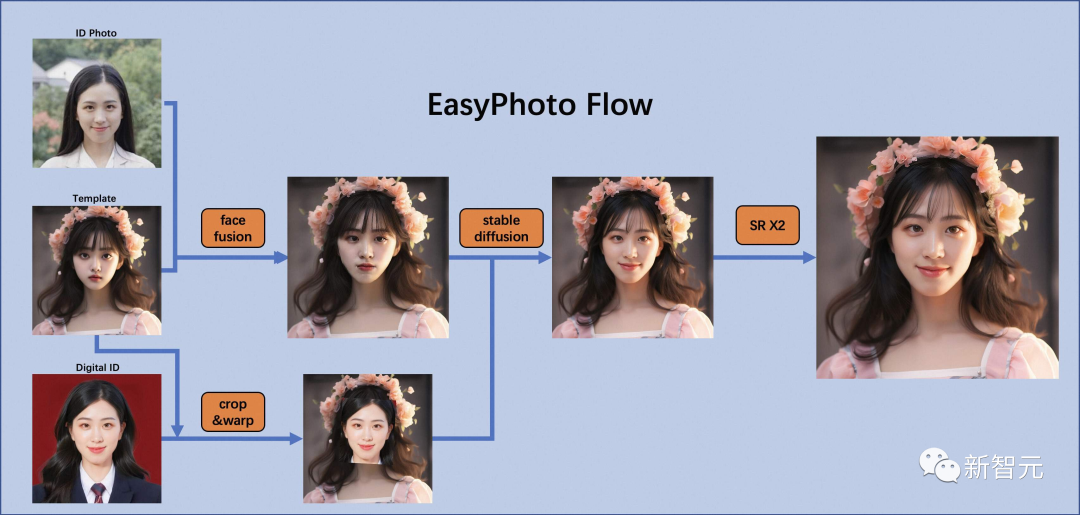
训练细节
在训练过程中,会利用模板图像进行实时验证,在训练结束后,项目团队会计算验证图像与用户图像之间的人脸ID差距,从而实现Lora融合,确保项目团队的Lora是用户的完美数字二重身。
此外,项目团队将选择验证中与用户最相似的图像作为face_id图像,用于推理。
推理细节
a.第一次扩散:
b.第二次扩散:
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号新智元 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接:https://www.d-arts.cn/article/article_info/key/MTIwNjMxMTA5NzGEqX1osKzGcw.html 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
-

-
北京
甲方 · 媒体平台
未认证的机构号
recently released
-
2023-12-14
-
2023-11-03











