
- 0
- 0
- 0
分享
- 北大硕士RLHF实践,基于DeepSpeed-Chat成功训练上自己的模型
-
2023-08-30

新智元报道
新智元报道
【新智元导读】本文关于基于人类反馈的强化学习(RLHF)进行了分析,结合DeepSpeed-Chat框架进行了成功的实践,同时也对实践过程中遇到的bug以及尝试trick进行了分享。
最近两月倒腾了一波RLHF,从ColossalAI到TRLX以及DeepSpeed-Chat,最后基于DeepSpeed-Chat成功训练上了自己的模型,最后效果也是肉眼可见的提升。对这一部分进行下总结,包括原理,代码以及踩坑与解决方案。
基本概念
首先还是解释一下一些概念,从NLP的角度举一些例子。
首先是RL中的Policy,State,Action。

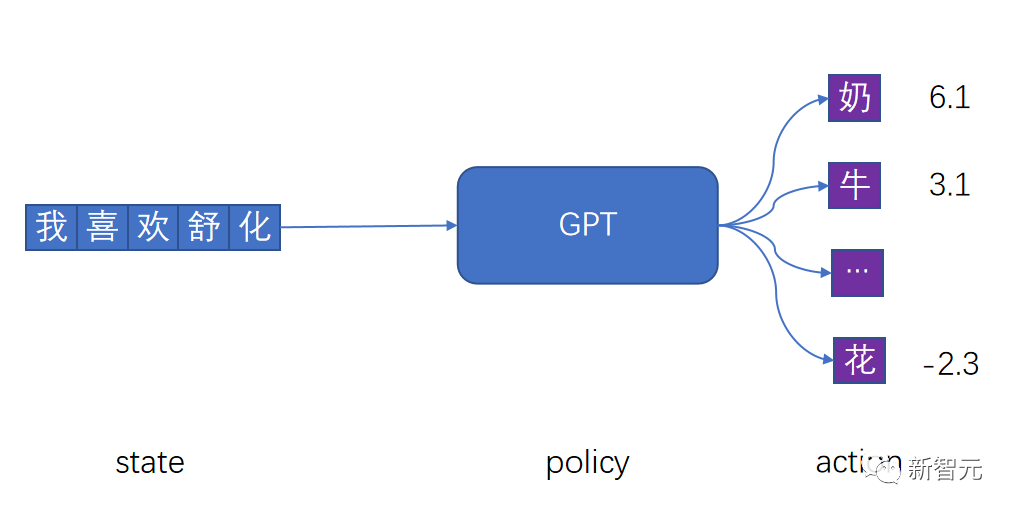 RL概念图
RL概念图
接下来介绍Reward,Return,Q,V。

PS:这里要注意区分价值和奖励:价值是未来累计奖励的期望。奖励是我们做出该动作后立即获取的收益。
RLHF过程
整个过程主要是分为三步:SFT,Training Reward Model,RLHF。
这里主要介绍一下Training Reward Model和RLHF。
Step2:Training Reward Model
数据
首先是这一部分数据的构成,每一条数据由query,chosen response, rejected response构成,chosen response相较于rejected response质量更高。我使用的数据来自Cohere/miracl-zh-queries-22-12,里面对于每条query包含了positive_passages和negative_passages两个部分,positive部分可以视为chosen,negative部分视为rejected,就可以采样构建我们训练Reward Model的数据了:
{
"query": "联合国总部在哪里?",
"chosen": "联合国总部大楼(亦称联合国大厦)是联合国总部的所在地,位于美国纽约市曼哈顿东侧,属于国际领土,因此只要是会员国国民持有护照就可以进入,包括与美国无邦交的联合国会员国。联合国总部大楼位于纽约市,其西侧边界为第一大道、南侧边界为东42街、北侧边界为东48街、东侧边界为东河,从联合国总部大楼可以俯瞰东河。此大楼于1949年和1950年间兴建,土地购自于当时的纽约房地产家,面积阔达17英亩(约6.87973公顷)。在此之前,洛克斐勒家族有意提供其在纽约州威斯特彻斯特郡洛克菲勒庄园的土地,但因距离曼哈顿遥远而作罢;之后,纳尔逊·洛克菲勒便协助新的土地的购买,其父小约翰·戴维森·洛克菲勒则捐助了850万美元协助兴建大楼。",
"rejected": "联合国的15个专门机构(如教科文组织)都没有设在总部。然而,有一些“自治附属机构”(如联合国儿童基金会)的总部设在联合国总部。"
}
模型结构
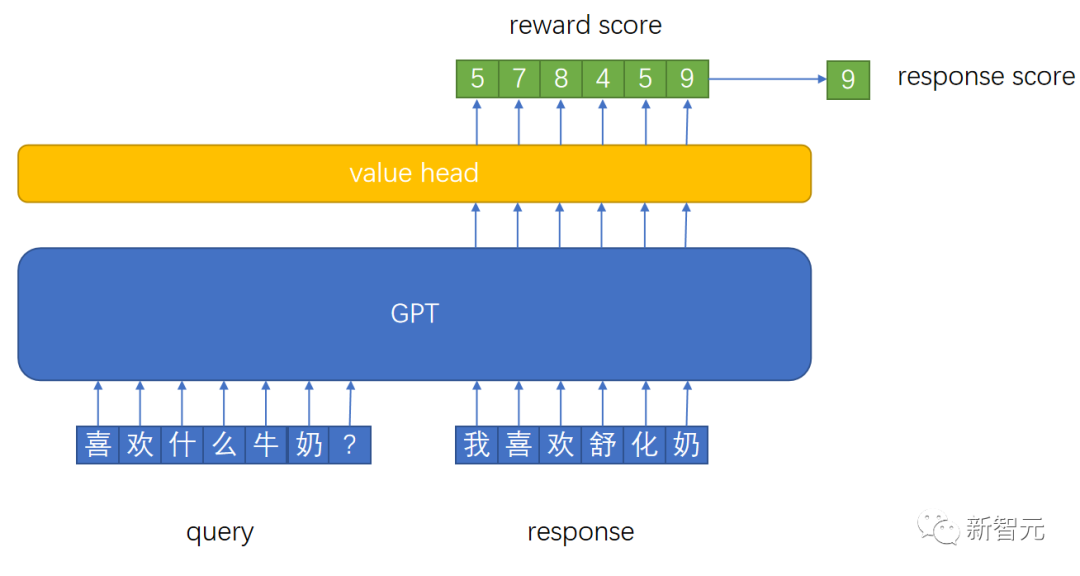 Reward Model
Reward Model
训练目标
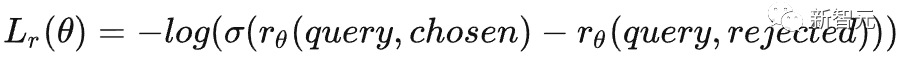
Step3:RLHF
整体结构
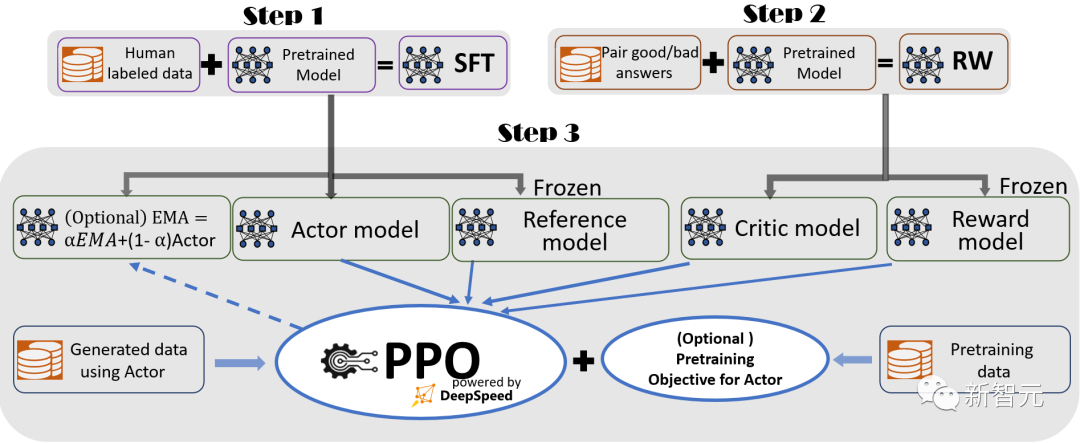 DeepSpeed-Chat RLHF
DeepSpeed-Chat RLHF
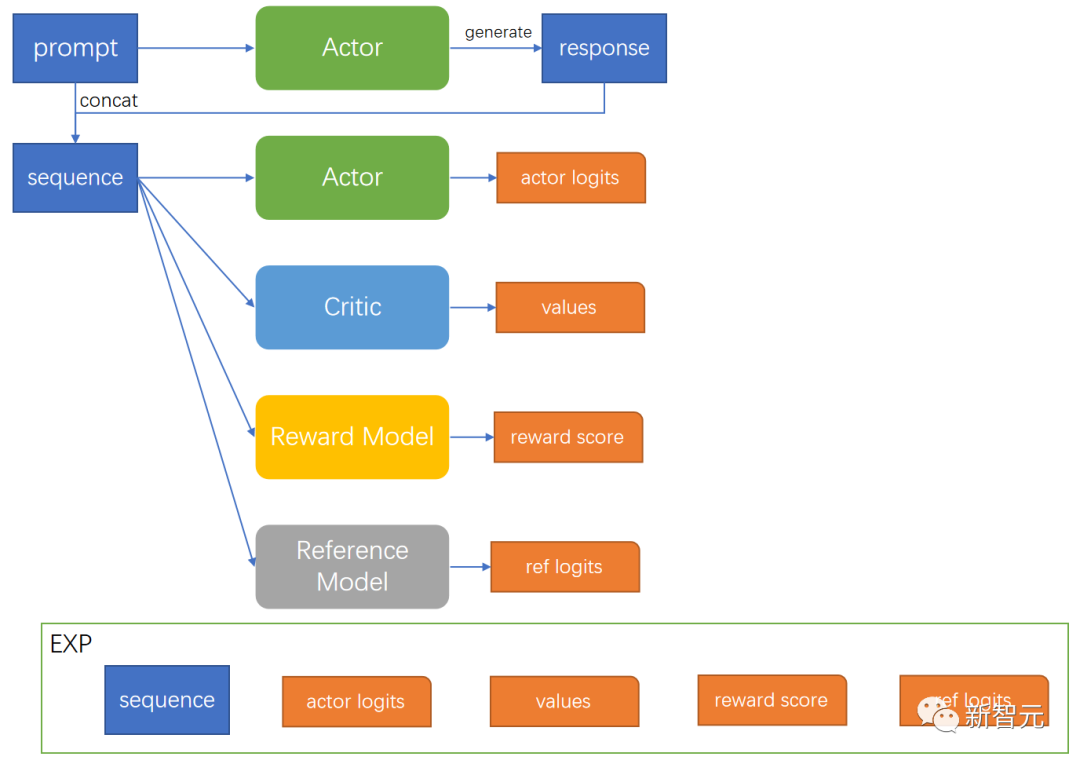
Actor Model:由SFT之后的模型初始化而来。作为策略(policy)模型,用于接收上文,做出动作,预测下一个字符。学习完毕之后,我们最终使用的就是这个模型。 Reference Model:和Actor Model同样初始化自SFT Model,训练过程中冻结参数,用于和Actor Model做对比,保证模型不要偏离原始SFT Model太多。 Reward Model:作为环境(env),训练过程中冻结参数,针对每一个状态,给出奖励分数。 Critic Model:由Reward Model初始化而来,用于近似价值函数,输入为状态s,估计当前状态的价值V。
训练过程
actor_logits:由Actor Model产生,包含对答案所有词的概率分布。 reference_logits:由Reference Model产生,包含对答案所有词语的概率分布,用于和actor logits进行对比,防止actor model偏离SFT Model太远。 reward_score: 由Reward Model产生,为当前句子状态下,立即获取的收益分数。 values:由Critic Model产生,估计当前句子状态下,到完成生成,可以获取的回报。
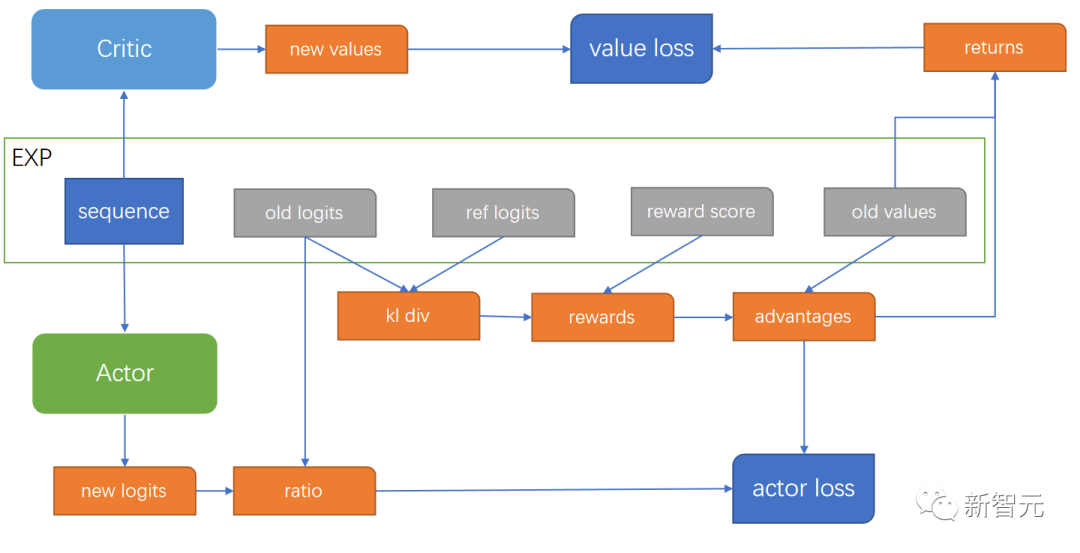
Critic Loss

Actor Loss


DeepSpeed-Chat实践与踩坑
Step2 Training Reward Model
***** Evaluating reward, Epoch 1/1 *****
step: 499/2287, chosen_last_scores (higher is better) : 5.074454307556152,reject_last_scores (lower is better) : 0.5599770545959473, acc (higher is better) : 0.812000036239624
step: 999/2287, chosen_last_scores (higher is better) : 5.084388732910156,reject_last_scores (lower is better) : 0.7938708662986755, acc (higher is better) : 0.7940000295639038
step: 1499/2287, chosen_last_scores (higher is better) : 5.106724262237549,reject_last_scores (lower is better) : 0.7971451878547668, acc (higher is better) : 0.7986666560173035
step: 1999/2287, chosen_last_scores (higher is better) : 5.0183587074279785,reject_last_scores (lower is better) : 0.672178328037262, acc (higher is better) : 0.7955000400543213
chosen_last_scores (higher is better) : 5.028912544250488,reject_last_scores (lower is better) : 0.7077188491821289, acc (higher is better) : 0.7936161160469055
Step3 RLHF
在这个步骤中,从跑通到收敛还是有不少麻烦,分享一些比较重要的点:
训练过程中发现make experience的时候,model.generate()产生的答案全是重复的无意义字。这里就很奇怪了,最后发现是开启了DeepSpeed Hybrid Engine所导致的,查看了issue之后,也发现了有类似的问题。
不过目前DeepSpeed-Chat也没有解决,需要关闭Hybrid Engine进行训练。
DeepSpeed-Chat还有一个很严重的问题就是,在make experience的时候,强制Actor Model生成到最大长度(设置max_length=min_length=max_min_length),这样子导致模型生成偏差很大。对于一个简单的问题,模型可能本来生成简单的一句话就可以完美回答了,但是却必须强制生成到最大长度,这样训练的模型和我们实际用起来的模型是有区别的。
对于这个问题,可以通过修改generate中的参数eos_token_id来解决。设置一个虚假的结束符,然后模型就可能生成正常的结束符。然后我们在构建attention_mask来遮蔽掉结束符后面的回答。例如:
seq = [0,0,0,0, prompt, answer, eos_token, other_word]
mask = [0,0,0,0,1(prompt),1(answer),1(eos_token),0(other_word)]
通过以上两步基本就可以跑通流程了,但是训练过程中还遇到了一个比较大的问题,就是Critic Loss并不收敛,越来越大。
具体的原因是:训练后期,随着模型输出答案越来越好,我们的reward值也会越来越高,导致我们最终累计回报return的区间也会越来越大。而前面说过,我们Critic Loss是一个MSE损失,因此训练后期,随着return的估计范围越来越大,Critic Model就越难估计。在我训练的过程中,一开始return的范围是在3-4左右,训练后期涨到了18-20,因此我们需要想点办法来约束一下我们的return。
首先的超参的调节,γ参数为折扣回报率,DeepSpeed-Chat中初始设置为1,可以将其调小一些来缓解。其次的话,使用reward scale这一trick帮助也非常大。
通过以上这些步骤,基本上我们正常训练了,模型最后也能看到一些效果,但是需要取得更好的效果,我们就需要引入一些trick了。
Trick
trick方面主要参考了The 37 Implementation Details of Proximal Policy Optimization以及影响PPO算法性能的10个关键技巧(附PPO算法简洁Pytorch实现)。对于部分trick,进行了尝试。
Normalization of Advantages
将Advantage进行归一化:adv=(adv-mean)/std
在mini-batch上进行
没有指标的量化,从我个人看结果而言,感觉提升不大
Overall Loss and Entropy Bonus
为了提高算法的探索能力,在actor的loss中增加一项策略熵,并乘以一个系数entropy_coef,使得在优化actor_loss的同时,让策略的熵尽可能大。一般我们设置entropy_coef=0.01
总体损失变为:loss = policy_loss - entropy * entropy_coefficient + value_loss * value_coefficient
没有指标的量化,从我个人看结果而言,感觉没有太多提升
Reward Scale
对reward进行缩放,将reward除以标准差
从训练log来看,对稳定critic loss效果很好,毕竟将reward 进行缩放之后,降低了return的估计区间。
没有指标的量化,从我个人看结果而言,提升很大,推荐使用。
关于其他的一些trick,如学习率衰减、梯度裁剪、Value Clipping等,本身框架就包含了,就不进行特别说明了。当然,这些trick在不同的数据或者模型上都会有不同的效果,需要自己进行探索。
通过以上这些方法,最后也顺利的完成了训练,希望对大家能有所帮助,也希望大家能分享自己有用的经验与理解,关于RL自己了解的也很少,还需要更多的学习。
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号新智元 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
-

-
北京
甲方 · 媒体平台
未认证的机构号
recently released
-
2023-12-14
-
2023-11-03











