
- 0
- 0
- 0
分享
- 图灵测试已死!ChatGPT通过人类考试也不算,超强AI评估新秀「逻辑谜题」
-
2023-08-31

新智元报道
新智元报道
【新智元导读】如何给大模型一个真正公平评价标准呢?
世界最强AI——ChatGPT可以通过各种考试,甚至输出回答让人难以辨别真假。
然而,它也有力所不及之处,那便是解决简单的视觉逻辑难题。
在一项由屏幕上排列的一系列色彩鲜艳的块组成的测试中,大多数人都能找出连接的图案。

但是,根据研究人员今年 5 月的一份报告,GPT-4在一类图案的测试中正确率仅为1/3,而在另一类图案中正确率仅为3%。

论文地址:https://arxiv.org/pdf/2305.07141.pdf
这项研究背后的团队,旨在为了测试AI系统的能力提供一个更好的基准,并帮助解决GPT-4等大型语言模型的难题。
论文作者Melanie Mitchell表示,人工智能领域的人们正在为如何评估这些系统而苦苦挣扎。
AI评估如何有效?
在过去的两三年里,LLM 在完成多项任务的能力上已经超越了以前的人工智能系统。
它们的工作原理很简单,就是根据数十亿在线句子中单词之间的统计相关性,在输入文本时生成可信的下一个单词。
对于基于LLM构建的聊天机器人来说,还有一个额外的元素:人类训练员提供了大量反馈,以调整机器人的反应。
令人惊叹的是,这种类似于自动完成的算法是在大量人类语言存储的基础上训练出来的,其能力的广度令人叹为观止。
其他人工智能系统可能会在某项任务中击败 LLM,但它们必须在与特定问题相关的数据上进行训练,无法从一项任务推广到另一项任务。

哈佛大学的认知科学家Tomer Ullman表示,从广义上讲,对于LLM背后发生的事情,两个阵营的研究人员持有截然相反的观点。一些人将算法的成就归因于推理或理解的闪光点。其他人(包括他自己和Mitchell等人)则要谨慎得多。
讨论双方的研究人员表示,像逻辑谜题这样揭示人类与AI系统能力差异的测试,是朝着正确方向迈出的一步。
纽约大学认知计算科学家Brenden Lake说,这种基准测试有助于揭示当今机器学习系统的不足之处,并理清了人类智能的要素。
关于如何最好地测试LLM,以及这些测试意义的研究也很实用。
Mitchell说,如果要将LLM应用于现实世界的各个领域,比如医学、法律。那么了解它们的能力极限就非常重要。
图灵测试死了吗?
长期以来,机器智能最著名的测试一直是图灵测试。
图灵测试是英国数学家和计算大师艾伦·图灵在1950年提出,当时计算机还处于起步阶段。
图灵提出了一个评估,他称之为「模仿游戏」。
在这个场景中,「人类法官」与一台计算机、和一个看不见的人进行简短的、基于文本的对话。
这个人类能可靠地检测出哪台是计算机吗?图灵表示,这是一个相当于「机器能否思考」的问题。

Mitchell指出,图灵并没有具体说明场景的许多细节,因此没有确切的标准可循。
其他研究人员认为,GPT-4和其他LLM现在很可能通过了「图灵测试」,因为它们可以骗过很多人,至少是在短对话中。
5月,AI21实验室的研究人员报告说,超过150万人玩过他们基于图灵测试的在线游戏。
玩家正确识别机器人的比例仅为60%,这并不比偶然性好多少。
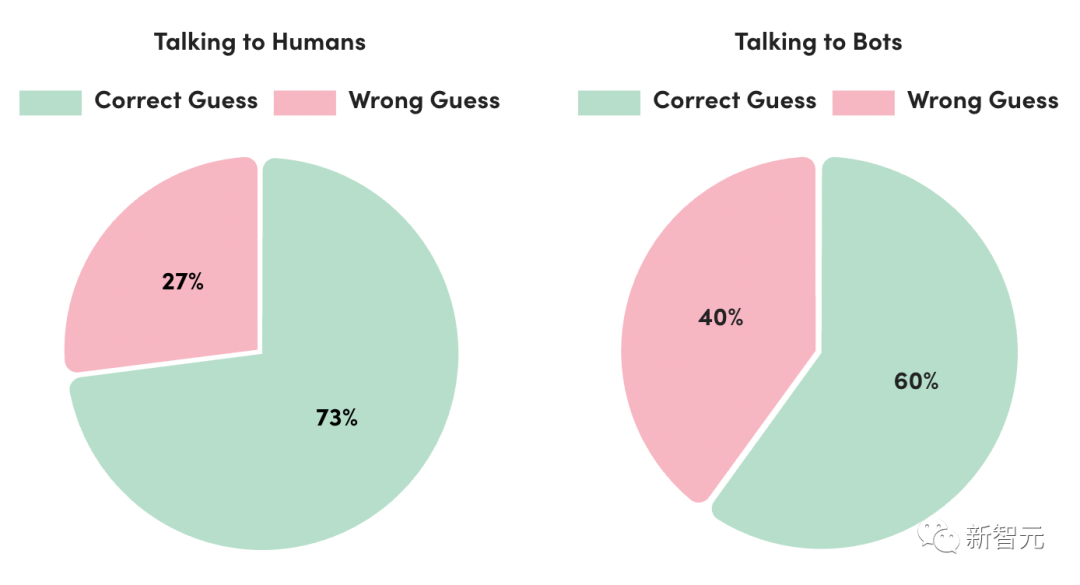
然而,在这种游戏中,熟悉LLM的研究人员可能仍然会获胜。通过利用AI系统的已知弱点,就会很容易发现LLM。
关键是要让LLM走出自己的「舒适区」。
谷歌软件工程师François Chollet建议,向LLM演示一些场景,这些场景是LLM在其训练数据中经常看到的场景的变体。在许多情况下,LLM的回答方式是,吐出最有可能与训练数据中的原始问题相关联的单词,而不是针对新情景给出的正确答案。
然而,Chollet和其他人对,把以欺骗为中心的测试作为计算机科学的目标持怀疑态度。
基准测试有危险
相反,研究人员在评估人工智能系统时,通常不采用图灵测试,而是使用旨在评估特定能力(如语言能力、常识推理和数学能力)表现的基准。
越来越多的研究团队也开始转向,为人类设计的学术和专业考试。
GPT-4发布时,OpenAI在一系列专为机器设计的基准测试中测试了其性能,包括阅读理解、数学和编码。
根据技术报告,GPT-4在其中大部分测试中都取得了优异成绩。
此外,GPT-4还参加了30项考试,GRE、评估美国医生临床知识现状的考试、为美国高中生设计的各种特定科目的考试等等。
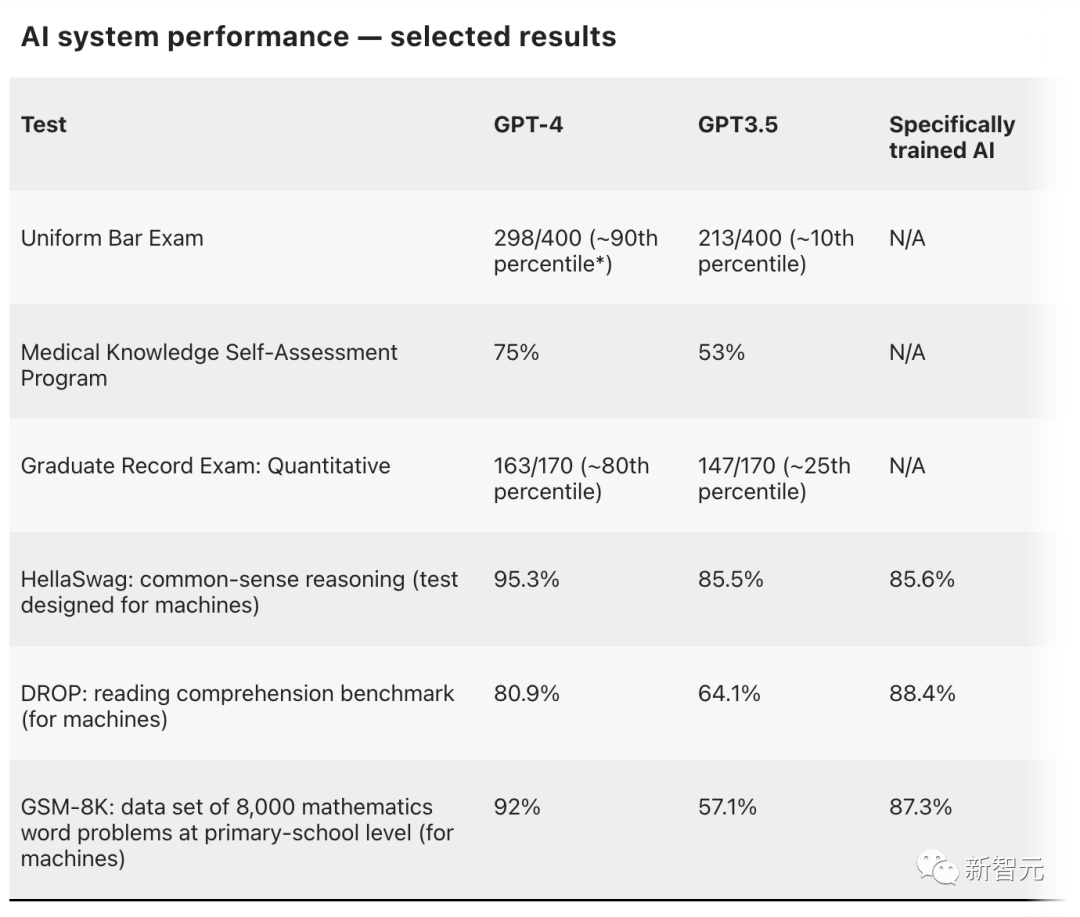
后来,有研究人员提到的一个挑战是,模型是在大量文本中训练出来的,它们可能已经在训练数据中看到过类似的问题,因此实际上可能是在寻找答案。这个问题其实被「污染」了。
研究人员还指出,LLM在考试问题上的成功可能一击就破,可能无法转化为在现实世界中所需的强大能力。
在解释这些基准的含义时,还有一个更深层次的问题。
一个在考试中表现出色的人,一般可以被认为在其他认知测试中表现出色,并且掌握了某些抽象概念。
然而,LLM工作方式与人类截然不同。因此,用我们评判人类方式,来推断人工智能系统,并不总是有效的。
这可能是因为LLM只能从语言中学习。如果没有在物理世界中,它们无法像人那样体验语言与物体、属性和情感的联系。
很明显,他们理解单词的方式与人类不同。
另一方面,LLM 也拥有人类所不具备的能力,比如,它们知道人类写过的几乎每一个单词之间的联系。
OpenAI的研究员Nick Ryder也认为,一项测试的表现可能,不会像获得相同分数的人那样具有普遍性。
他表示,我认为,我们不应该从对人类和大型语言模型的评估中得出任何等价的结论。OpenAI 的分数 "并不代表人类的能力或推理能力。它的目的是说明模型在该任务中的表现如何。
人工智能研究人员表示,为了找出LLM的优势和劣势,需要更广泛和严格的审查。丰富多彩的逻辑谜题可能是其中的一个候选者。
逻辑谜题登场
2019年,在LLM爆发之前,Chollet在网上发布了,自己创建的一种新的人工智能系统逻辑测试,称为抽象和推理语料库(ARC) 。
解题者要看几个方格变为另一种图案的可视化演示,并通过指出下一个方格将如何变换来表明他们已经掌握了变化的基本规则。
Chollet表示,ARC 捕捉到了「人类智慧的标志」。从日常知识中进行抽象,并将其应用于以前从未见过的问题的能力。
当前,几个研究团队现在已经使用ARC来测试LLM的能力,没有一个能实现接近人类的表现。
Mitchell和她的同事制作了一系列新的谜题——被称为ConceptARC——它们的灵感来自ARC,但在两个关键方面有所不同。
ConceptARC测试更容易。Mitchell的团队希望确保基准测试,不会错过机器能力的进步,哪怕是很小的进步。另一个区别是,团队选择特定的概念进行测试,然后为每个主题的变体概念创建一系列谜题。
性能差意味着什么
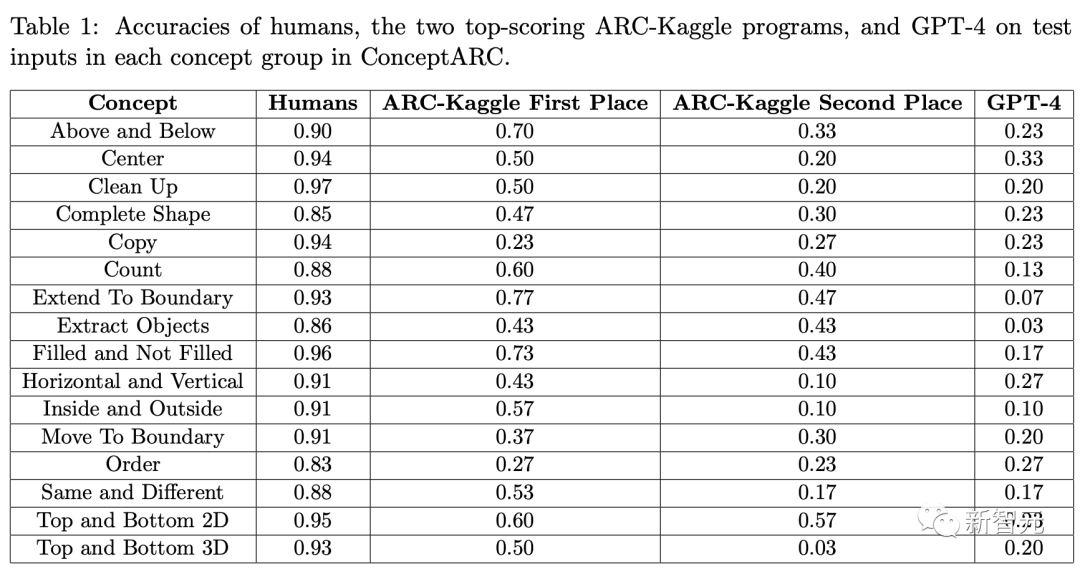
研究人员将ConceptARC任务分配给GPT-4和400名在线应征者。
人类在所有概念组中的平均得分率为 91%(其中一组为 97%);GPT-在一组中的得分率为33%,在所有其他组中得分不到30%。
研究人员证明,AI仍然无法接近人类的水平。然而令人惊讶的是,它能解决一些从未被训练过的问题。
研究小组还测试了Chollet竞赛中的领先聊天机器人。
总的来说,他们比GPT-4做得更好,但表现比人类差,在一个类别中得分最高,为77%,但在大多数类别中得分不到60%。
不过,Bowman表示,GPT-4在ConceptARC考试中的失利并不能证明它缺乏基本的抽象推理能力。
其实,ConceptARC对GPT-4有些不利,其中一个原因是它是一项视觉测试。
目前,GPT-4仅能接受文本作为输,因此研究人员给GPT-4提供了代表图像的数字数组。相比之下,人类参与者看到了图像。
推理论证
Bowman指出,与其他实验综合起来表明,LLM至少已经获得了对抽象概念进行推理的基本能力。
但LLM的推理能力总体上是「参差不齐的」,比人类的推理能力更有限。不过,随着LLM的参数规模扩大,推理能力相应地也会提高。
许多研究人员一致认为,测试LLM抽象推理能力和其他智力迹象的最佳方法,仍然是一个开放的、未解决的问题。
https://www.nature.com/articles/d41586-023-02361-7
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号新智元 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
-

-
北京
甲方 · 媒体平台
未认证的机构号
recently released
-
2023-12-14
-
2023-11-03











