
- 0
- 0
- 0
分享
- GPT-4推理提升1750%!普林斯顿清华姚班校友提出全新「思维树ToT」框架,让LLM反复思考
-
2023-05-22

新智元报道
新智元报道
【新智元导读】由普林斯顿和谷歌DeepMind联合提出的全新「思维树」框架,让GPT-4可以自己提案、评估和决策,推理能力最高可提升1750%。

论文地址:https://arxiv.org/abs/2305.10601
让LLM「反复思考」

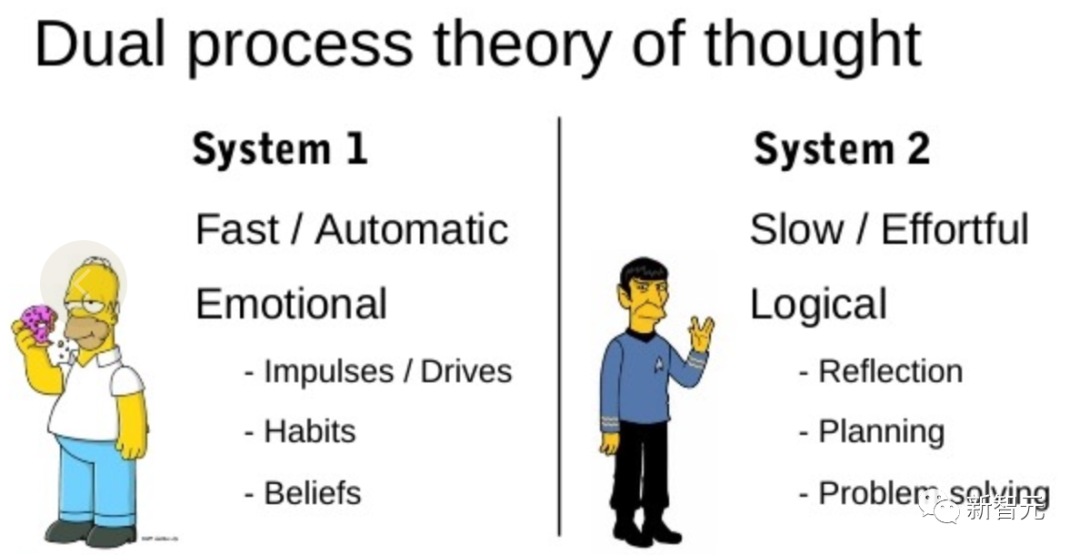

一个真正的问题解决过程包括重复使用现有信息来探索,反过来,这将发现更多的信息,直到最终找到解决方法。

ToT四步法
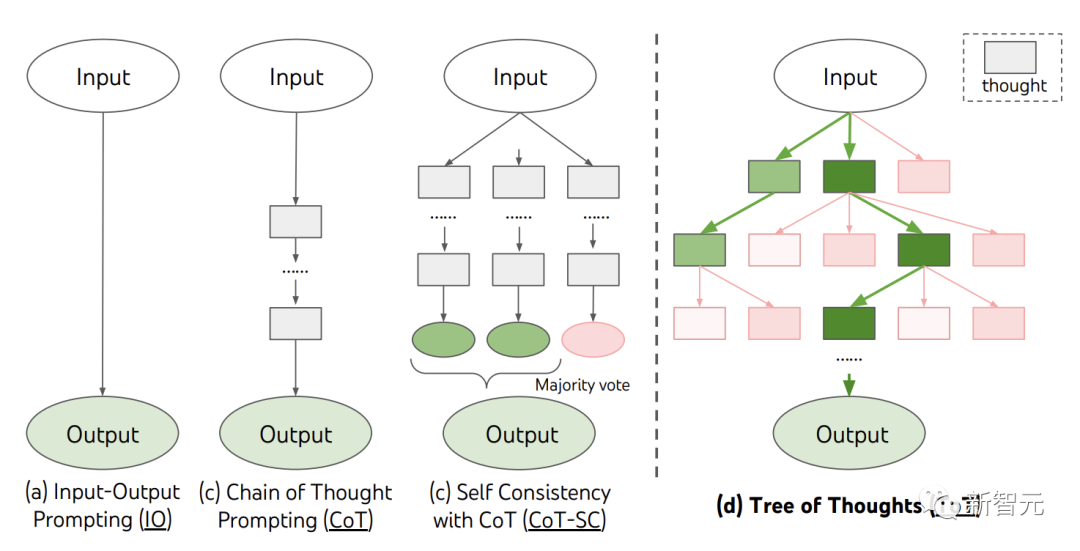
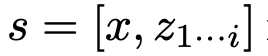 ,表示到目前为止输入和思维序列的部分解。
,表示到目前为止输入和思维序列的部分解。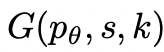
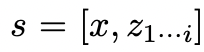 ,通过2种策略来为下一个思维步骤生成k个候选者。
,通过2种策略来为下一个思维步骤生成k个候选者。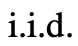 思维:
思维: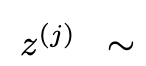
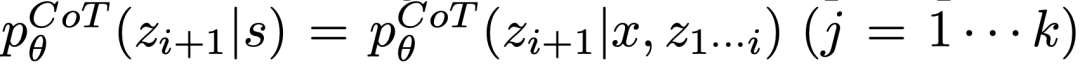 导致多样性时,效果更好。
导致多样性时,效果更好。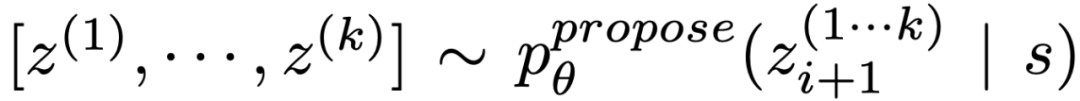 。这在思维空间受限制(比如每个思维只是一个词或一行)时效果更好,因此在同一上下文中提出不同的想法可以避免重复。
。这在思维空间受限制(比如每个思维只是一个词或一行)时效果更好,因此在同一上下文中提出不同的想法可以避免重复。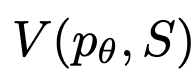
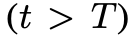 ,或者状态评估器认为不可能从当前的
,或者状态评估器认为不可能从当前的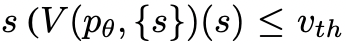 为阈值
为阈值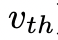 解决问题。在这两种情况下,DFS都会回溯到s的父状态以继续探索。
解决问题。在这两种情况下,DFS都会回溯到s的父状态以继续探索。
实验

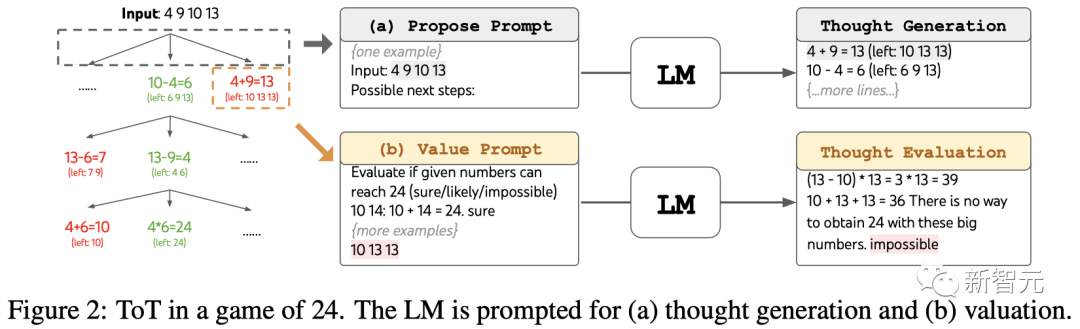
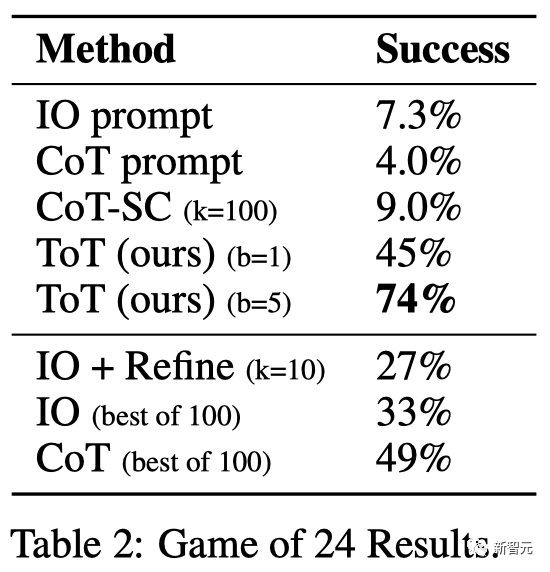
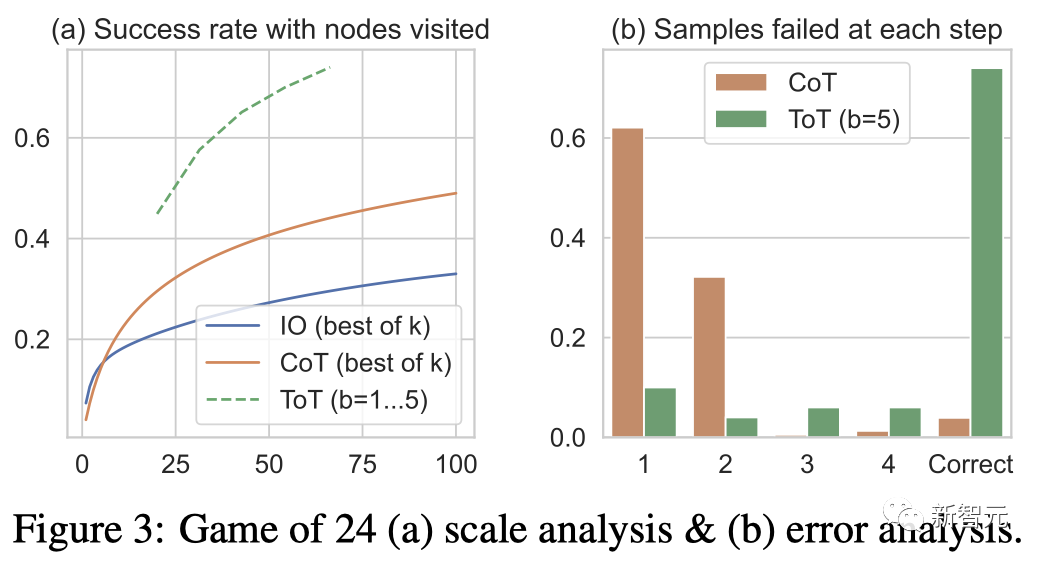
24点(Game of 24)
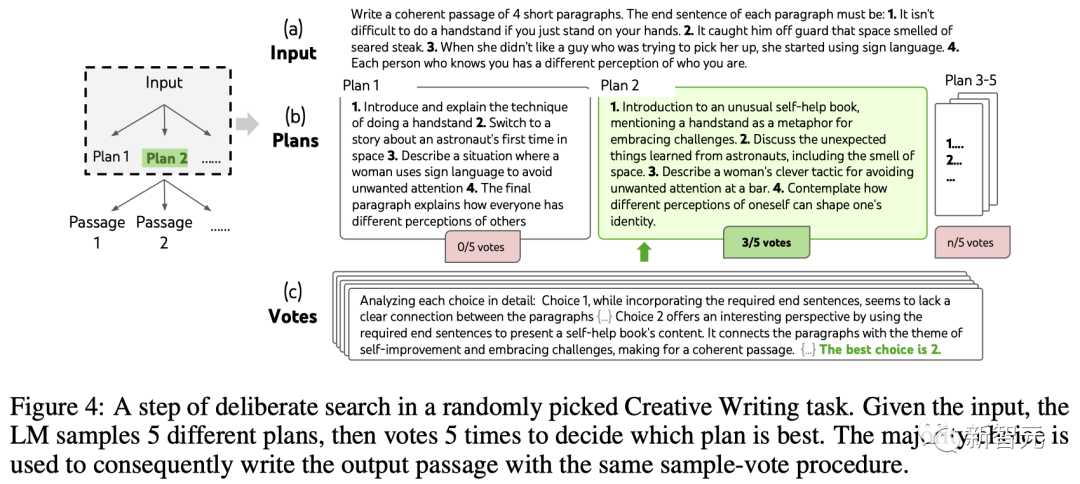
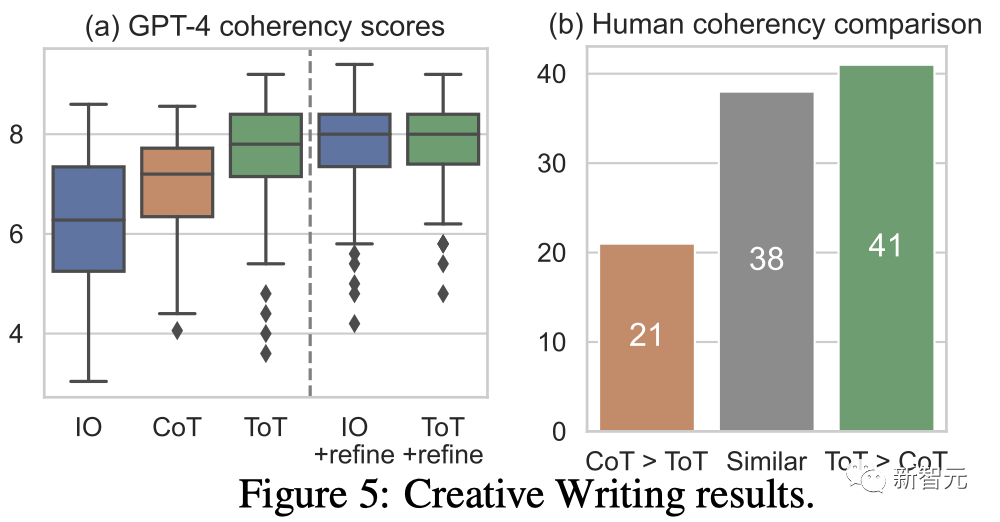
创意写作
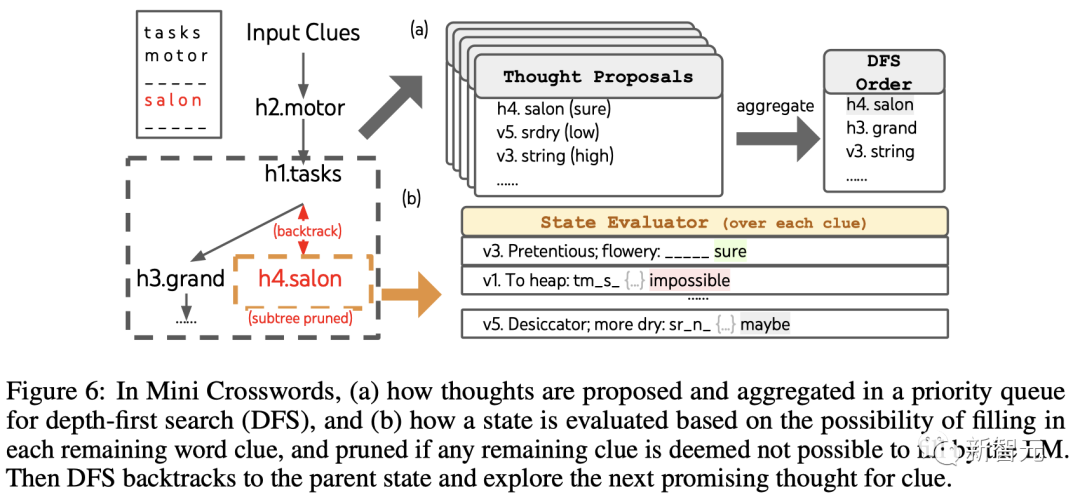
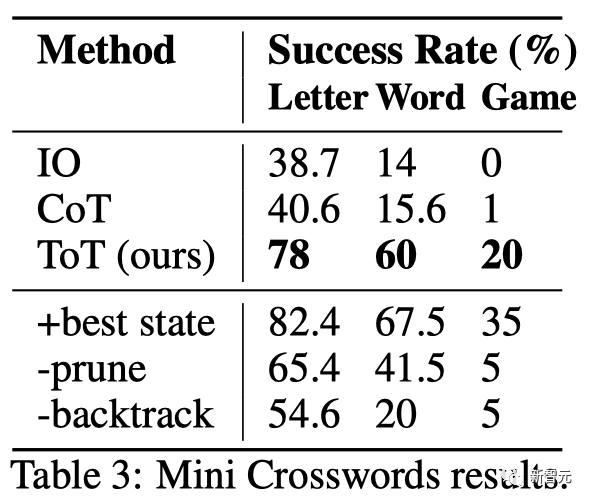
迷你填字游戏
局限性与结论
作者介绍





-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号新智元 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
10786
举报
0
-

-
北京
甲方 · 媒体平台
未认证的机构号
recently released
-
2023-12-14
-
2023-11-03











