
- 0
- 0
- 0
分享
- AIR学术|开源轻量版BioMedGPT!聂再清:最终目标是生物医药领域基础大模型
-
原创 2023-04-20
4月19日,以“大模型时代AI生物医药的创新融合”为主题的第三期AIR学术工作坊在清华大学智能产业研究院(AIR)图灵报告厅成功举办。会上AIR首席研究员聂再清教授介绍了团队在生物医药领域大模型方向上的最新进展,并开源了轻量级科研版基础模型BioMedGPT-1.6B。同时,活动还邀请了清华大学惠妍讲席教授、AIR首席科学家马维英,清华大学国强教授、AIR首席研究员聂再清,华深智药创始人、AIR高级访问教授彭健,医渡云首席技术官闫峻,北京智源人工智能研究院健康计算中心负责人叶启威五位学界及产业界嘉宾共同探讨大模型时代AI在生物医药领域的创新融合机遇。本次活动由AIR兰艳艳教授主持。

与会嘉宾合影
会议首先由中国工程院院士、清华大学讲席教授、AIR院长张亚勤院士致开场辞,他表示:将大模型范式应用于生命科学是理性又大胆的探索。AIR的研究团队以构建生物医药领域大模型为目标,相继研发了多个生物医药专业领域的AI模型,在蛋白质结构预测、抗体设计等领域并取得不错的成果。此次开源的轻量级科研版基础模型BioMedGPT-1.6B是在生命科学领域的重要进展,未来,研究团队将继续用BioMedGPT进一步整合领域内多源异构的数据,将知识融入模型构建之中,实现生物世界文本和知识的统一表示学习,带来生物医药领域的“智能涌现”。
开源BioMedGPT-1.6B轻量级科研版基础模型
接下来,聂再清教授着重介绍了团队在研的生物医药领域大模型BioMedGPT的最新进展,并开源了轻量级科研版基础模型BioMedGPT-1.6B。

聂再清教授讲座
着眼于生命科学领域,编码生命的分子语言与自然语言具有类似的特征。例如,原子的特定组合方式形成了不同类型的官能团,进而决定分子的特定功能和化学性质;基因的差异表达在细胞水平上会导致形态、结构和功能的差异,进而影响生物体生理结构和功能。顺应自然法则,基因也会不断变异产生新的序列,同时淘汰旧的序列。长期以来,生物学家在一次又一次湿实验中总结规律并通过文献记录。聂教授团队构建BioMedGPT的目标就是要把分子语言中蕴含的知识以及长期以来通过湿实验总结的文本和知识图谱信息融合压缩到一个大规模语言模型中,从而实现从序列模式中学习生物结构和功能规律,通过AI解码生命语言。

通过湿实验积累的很多有价值的知识和数据,很多都可以公开获取使用,如蛋白质序列目前已有超过22亿条数据,可购买的具备成药性的小分子有 2.3亿等。这些海量公开分子序列数据其实完全可以用语言模型来学习其语义表征,用于药物研发任务。同时,现存也有许多生物学家们几百年来积累的海量文献和知识图谱数据,无论知识图谱还是文献都可以单独训练出一个大的知识表征模型,而且这些不同模态的数据里的分子信息是相互关联的,如果能把它们统一压缩在一个大模型里,将惠及未来所有的生物医药下游任务。
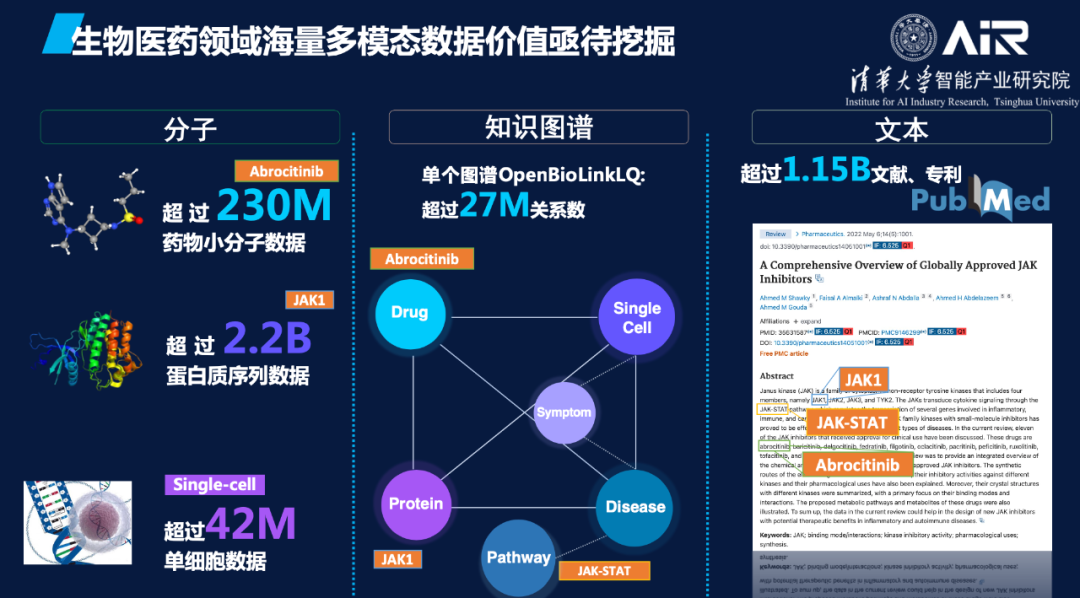
基于上述设想,聂教授团队进行了一系列实验验证,通过尝试融合分子结构、知识图谱和文本,所构建的多模态数据统一表示在多项AIDD任务,如药物性质预测、药物-靶点相互作用等均取得了SOTA的结果,佐证了融合多模态生物医药数据的价值和意义。

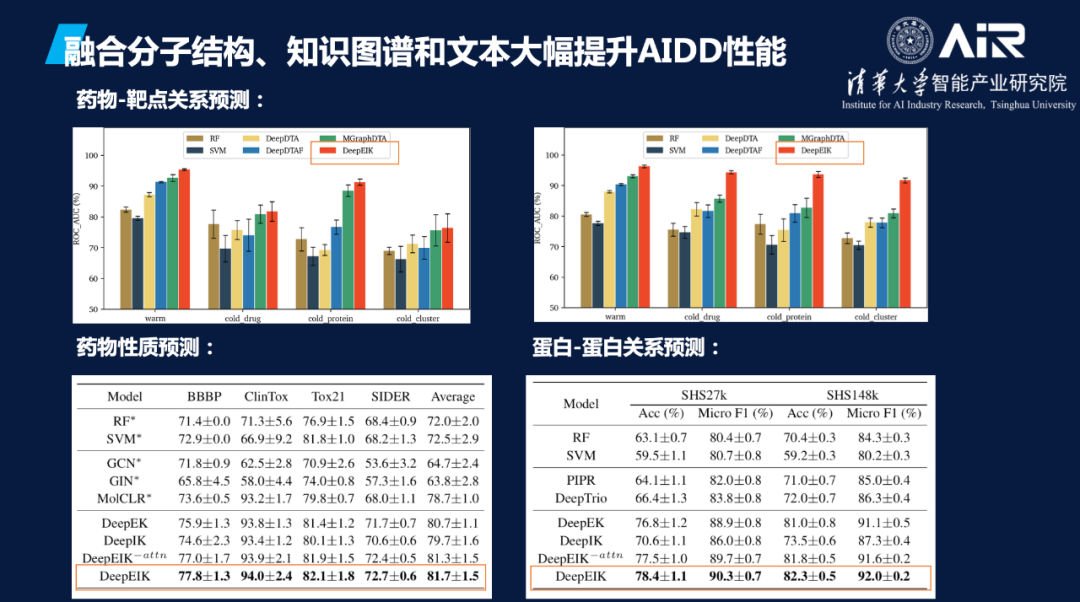
构建生物医药领域基础模型BioMedGPT
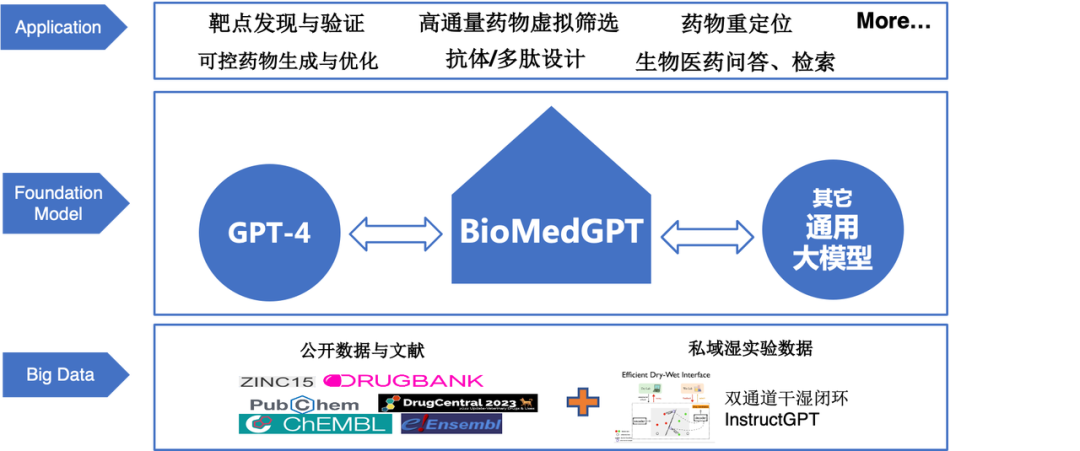
通过调研,团队发现当前还没有能够支持多模态、多任务的生物医药基础模型。聂再清教授带领团队着手构建了多模态生物医药领域基础模型-BioMedGPT,旨在将生物世界分子、文本与知识进行统一表示学习以达到在各项下游任务上能力的整体提升。


BioMedGPT在数据层面整合了基因、分子、细胞、蛋白、文献、专利、知识库等多源异构的数据,首次将知识引入到模型构建中,实现了生物世界文本和知识的统一表示学习,增强了模型的泛化能力和可解释性。在应用任务方面, BioMedGPT能够处理自然语言、药物性质预测、跨模态生成等多个任务,实现对生命科学全域任务的探索,已经在多个关键下游任务中取得了 SOTA 的效果。
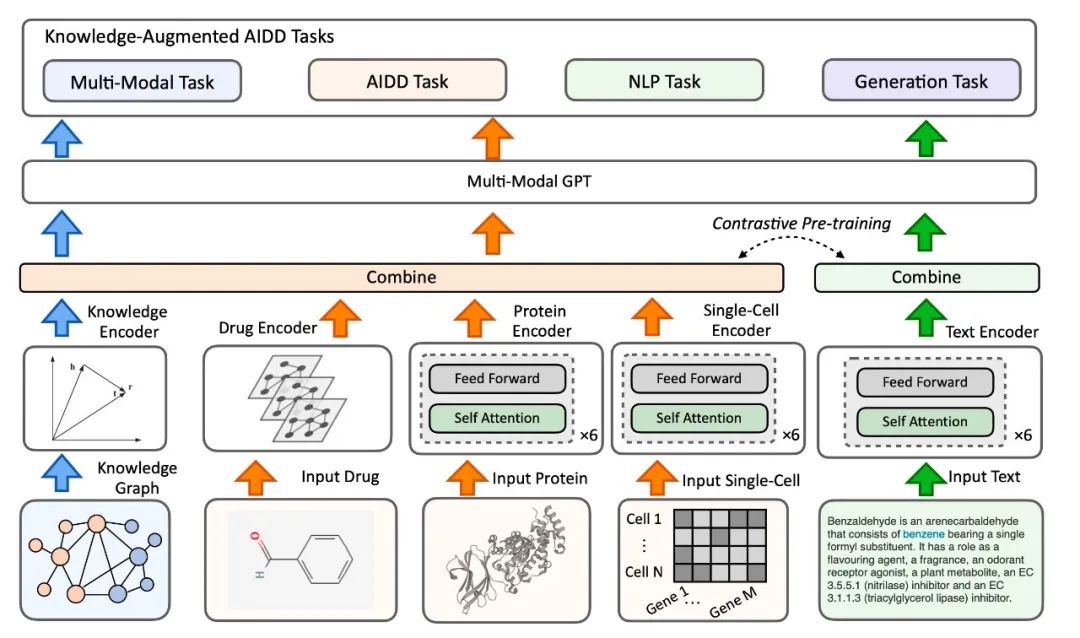
此次活动开源的轻量科研版本 BioMedGPT-1.6B包含一个16亿参数、5000万参数的单细胞预训练模型CellLM-50M,以及团队打造的生物医药知识图谱、专业数据集等。开源地址:https://github.com/BioFM/OpenBioMed

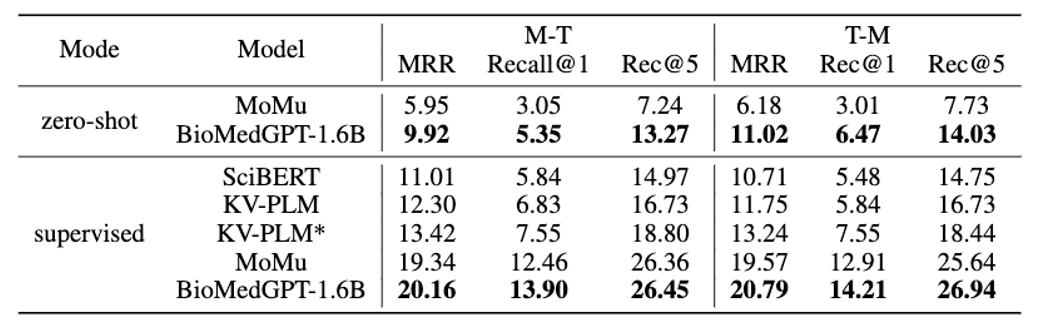
BioMedGPT-1.6B在多项下游任务中取得了SOTA。以分子-文本互检索跨模态任务为例,BioMedGPT-1.6B在两个任务的zero-shot和finetune结果上均取得SOTA。


单细胞预训练模型CellLM-50M则提供了结合了细胞层面数据的语义表征,目前在细胞类型注释任务上取得了比较理想的结果,未来将成为BioMedGPT中细胞编码的重要组成。

打造BioMedGPT双循环能力
团队接下来将着力打造BioMedGPT的双循环能力:
干湿闭环:双通道干湿闭环计算接口,结合高通量实验,突破AI模型严重受限于药物靶点活性数据少的挑战,充分利用好每一个湿实验的标签。
专家在环:专家可控交互式药物生成,给定药物靶点等信息,药化专家通过自然语言、参数设置等多种符合药化专家使用习惯的方式与AI进行多轮交互,通过迭代生成具有所需性质的药物候选。
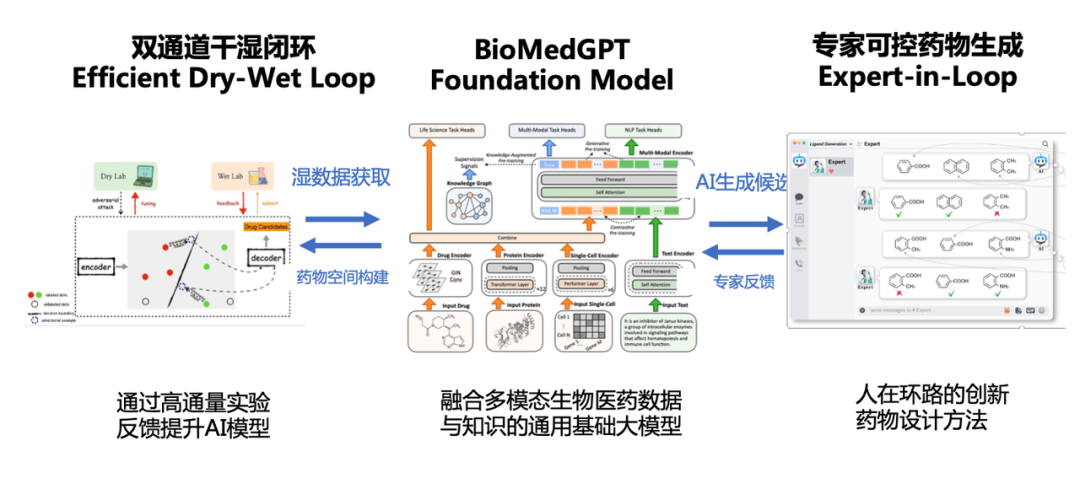
通过打造的干湿闭环和专家在环的双闭环体系,使得BioMedGPT能够从真实世界学习、向人类专家学习有望成为生物医药研发基础大模型,支撑诸如高通量虚拟筛选、分子生成与优化、个性化药物重定位、生物医药知识检索等多项应用。
圆桌论坛
在“大模型时代AI生物医药的创新融合”圆桌论坛上,各位嘉宾就 “以GPT为代表的基础模型如何更好的赋能生命科学、生物医药领域?”、“生物医药领域基础模型的构建面临哪些机遇与挑战?”,以及“生物医药基础模型的ChatGPT Moment 会以何种形式出现?“ 等诸多问题展开了深入探讨。

清华大学惠妍讲席教授、智能产业研究院(AIR)首席科学家马维英教授表示,生成式AI将颠覆甚至重新定义新科学领域,如果将其应用到生物医药领域将具有深远的意义。作为科学家,我们要拥抱新的工具,拥抱新的观念和最新的方法论。同时也要看到,这对我们做AI的人来说是非常大的机会。将来如果能用AI技术,加快药物研发的周期,并针对个体的基因序列和新抗原设计出对应的药物精准治疗,实现个性化的免疫疗法,整个生物制药会更加精准、更安全、更经济、更普惠。
清华大学国强教授、智能产业研究院(AIR)聂再清表示:“ChatGPT可能是第四次工业革命的起点,基于大数据的驱动的人工智能的能够赋能各个领域的科研工作。我们期望BioMedGPT是可以One For All,以数据和知识驱动生物医药领域内的科研发展,从而更好的帮助药物研发人员。”
华深智药创始人、AIR高级访问教授彭健认为,未来将不再有传统生物学与计算生物学的区别,假设驱动的科研将被进入数据驱动的新科研范式。我们曾致力于为每个任务设计一个模型,然而ChatGPT的出现改变了这一认知,通用的模型让原本看似无法突破的任务变得可行。超越SOTA不应是唯一追求,帮助科研界理解模型能力的上限和边界也非常重要。这种认识不仅对生物医药领域有巨大影响,还将对许多其他领域带来重要的提升。
医渡云首席技术官闫峻博士表示:“绿色医疗Green Health(即Safer,Better, more Accessible的医疗)是我们乃至当前整个社会的使命,大模型有望能够通过技术让医疗服务、医药研发的每个环节降本增效,最终反馈到每个人身上就能让更多的人得到治疗的机会,用更低的成本把病治好,解决整个医疗产业里边供应端和供应链的问题。以前医疗产业每一个链条进行的都是单点的局部优化,但是大模型时代我们有望得到全局最优。及时拥抱新的技术潮流,可能代表的是这个行业的未来。”
北京智源人工智能研究院健康计算中心负责人叶启威认为AI是一种帮助人类前进的工具,大模型就是在此基础上用一套更好的方式集成大家的共识,帮助科研工作者发现一些以前没有被发现的事情,这是我所理解的大模型的哲学。我们真的希望某种意义上来说,大家能够把精力、财力、学识都投入到这些真正能够对于未来 10 年、20 年乃至 100 年之后对人类更加有意义的事情上。
最后,AIR兰艳艳教授对本次活动进行总结发言,她表示以 GPT 为代表的这样的大模型与生物医药领域深度交叉创新,有巨大的想象空间,同时也很高兴看到大家对 AI 跟生命科学交叉研究的关注,相信通过学术界和产业界更好地合作,可以共同推动AI在生物医药领域产生真正价值。
AIR长期招聘人工智能领域优秀科研人员
点这里关注我们
关于AIR
往期精彩:
AIR学术|上海人工智能实验室李弘扬、陈立:端到端自动驾驶算法设计思考
张亚勤:大模型时代,中国AI行业的机遇与挑战
祝贺!AIR获ICLR 2023杰出论文提名
亚信科技与清华大学智能产业研究院共建“6G网络与智能计算联合研究中心”
亚信科技、清华大学智能产业研究院联合发布《AIGC(GPT-4)赋能通信行业应用白皮书》
全球首届车路协同自动驾驶算法挑战赛公布获奖名单
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号清华大学智能产业研究院 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
-

-
北京
甲方 · 公立学校
未认证的机构号
recently released
-
2023-04-29
-
2023-04-28
提名奖")










