
- 0
- 0
- 0
分享
- 张亚勤:AI大模型时代
-
原创 2023-04-26
近日,清华大学讲席教授、智能产业研究院(AIR)院长张亚勤院士发表题为《AI大模型时代》的演讲。

本次演讲围绕AI大趋势、ChatGPT现象以及AIR在做什么三大主题进行了阐述,深入探讨了人工智能的发展历程、ChatGPT及数字化3.0时代人类面临的机遇与挑战,同时介绍了AIR的研究概况和发展方向。
AI大趋势
在过去三十年,整个IT行业最重要的变革是实现数字化。人工智能有三个要素:算力、算法和数据。过去十年算力增加了10万倍,远超摩尔定律。数据是新一代人工智能,特别是大模型的基石。数字化经历了三个发展阶段,数字化1.0是内容的数字化,包括文本、音乐、图片、视频、语言,直接产物是消费者互联网;数字化2.0是企业的数字化,又称为企业的信息化,如ERP、CRM、商务智能、企业智能等,直接产物是云计算;现在进入数字化3.0时代,包括信息、物理、生物世界的数字化,比如车、机器、城市、道路、家庭、大脑、身体器官、细胞、分子、基因都在数字化。1.0到2.0是从原子到比特,3.0是比特和原子分子的相互映射,直接产物是海量数据,并且数据比1.0和2.0时代大很多数量级,也是人工智能发展最重要的基石。

人工智能的鼻祖是图灵,通过图灵测试来验证人类是否能够分辨出他们的交互对象是另一个人还是一台机器。在人工智能的发展过程中存在几大学派,一个是连接主义,另一个是基于规则符号的理性主义。2020年,GPT-3和AlphaFold2把人工智能推向了新的台阶。整体来看,过去十年是深度学习的十年。
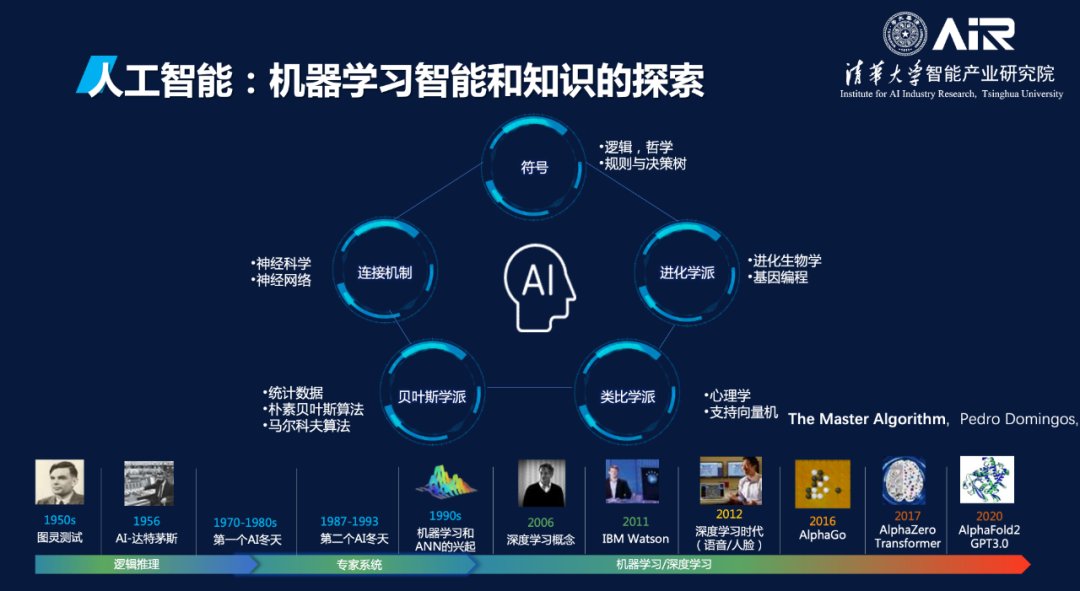
GPT-3和AlphaFold2出现之后,深度学习走向预训练、多模态、大模型的时代。深度学习分为两个阶段,1.0阶段是感知的突破,包括语音、图像、人脸等特定场景特定任务的突破,且在第一个五年已达到人类水平。2.0阶段是认知的突破,思考、决策、预测、生成,我们现在也已几乎达到人类水平。这其中存在很多问题,如透明性、可解释性、因果性、安全隐私、伦理、生成式AI版权和内容不可控等。物理世界和信息世界走向融合的时候,我们一定要有边界。科研人员要有意识从事先进的认知感知方面的研究,技术有很多发展空间,但有些方面我们不能去触碰,包括人工智能有无情感、自主意识等方面,我们不应涉足研究。

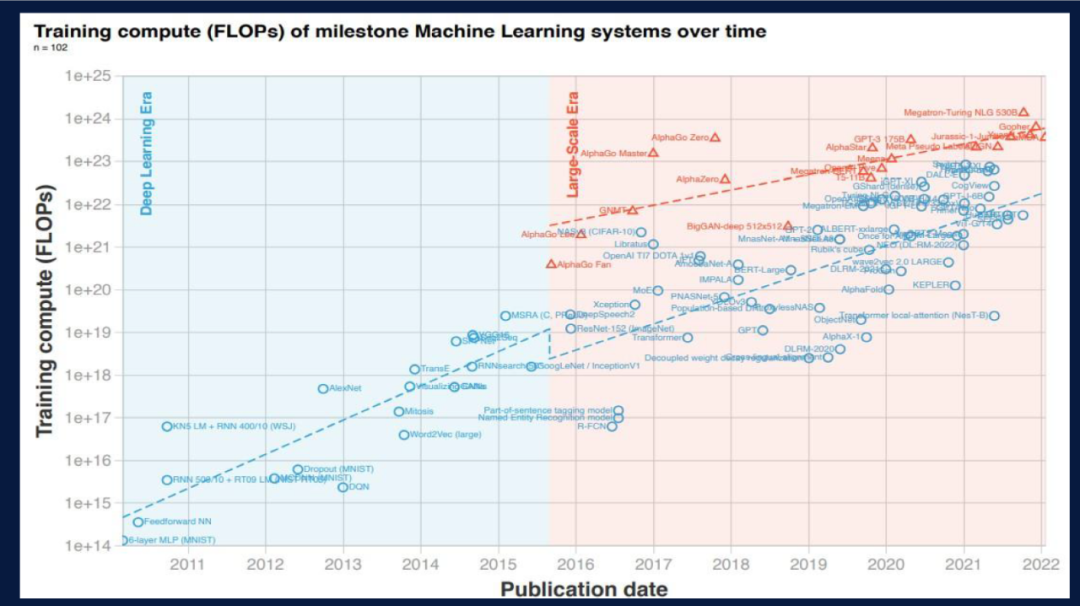
随着时间推进,模型的体量增加。第一个里程碑是2016年的AlphaGo,另一个是2020年的GPT-3。GPT-3出现之后,大模型如雨后春笋般大量涌现。
ChatGPT现象
下图总结了ChatGPT的发展过程。从2018年GPT-1的1.17亿参数,到2019年GPT-2的15亿参数,再到2020年GPT-3两个数量级的跳变。2020年之后出现两个分支,即Codex和InstructGPT。ChatGPT是InstructGPT的延伸,其中重要的改进是指令微调和基于人类反馈的强化学习。

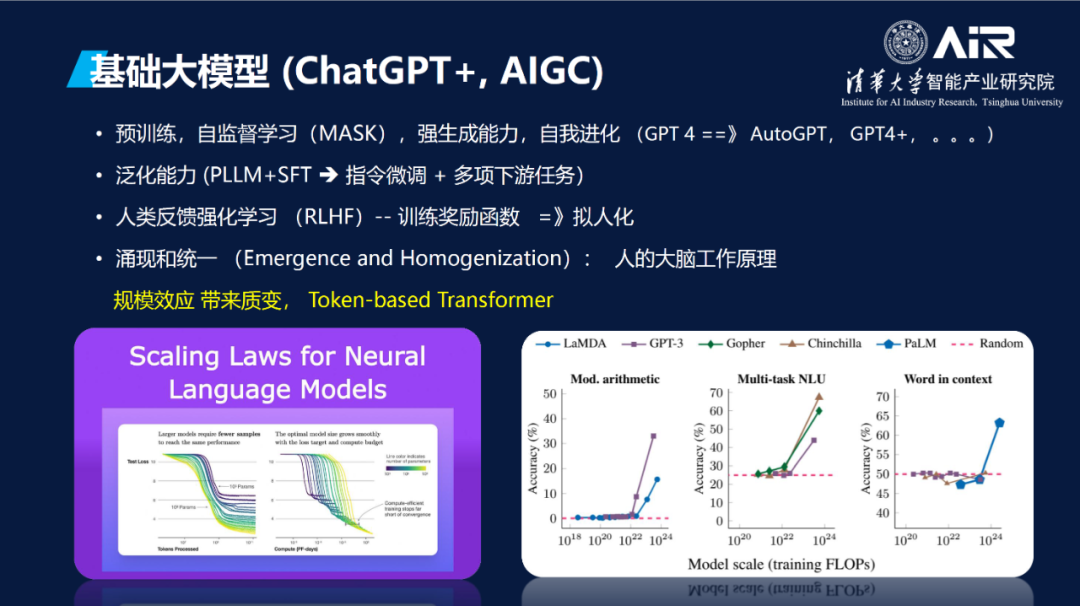
过去两年有ChatGPT、GPT-4、AIGC(Stable Diffusion, DALLE, NeRF)这样一些大趋势。GPT是预训练的,能够自监督学习,具有强生成能力,并且可以自我进化,这些特征改变着产品、开发、科研的范式。预训练学习首先将模型训练好,自监督学习脱离了海量数据的人工标注,这使得现在的起点是基于模型而非数据去生成应用和产品,以预训练模型为起点,加上自己的数据进行微调,用少于1%的参数就可以执行大量的下游任务。GPT-4同样具有强大的自我演化能力,比如AutoGPT、GPT-4+等模型主要的开发任务主要程度上是由GPT-4自身来进行编码完成,整个产品的开发理念更重视模型的泛化能力和通用能力。基于人类反馈的强化学习让训练更有人性,该方法属于工程方面的重要进展。
人工智能主要在两个维度做平衡,分别是Exploitation和Exploration。Exploitation是将现在的知识优化并运用到最好,Exploration是通过试错来探索新的能力。比如AlphaGo是探索,OpenAI更多是优化已有的能力,ChatGPT也可以做强化学习,也可以进一步探索,目前刚刚开始起步,但第一次有了新的能力。我们现在熟悉的概念是涌现和统一。涌现指数据量达到一定程度时各项任务出现跳变,但是如何发生大家并不了解。统一是指过去语音、图像、语言有各自的算法,Transformer出现后所有的模态都实现了统一(token-based)。这和我们大脑的工作原理很相似,人在学习的时候,在知识量达到一定程度时,我们实现“涌现”突然开窍得到顿悟。人的大脑860亿个神经元,每个神经元之间有突触。每个神经元都相同,通过联结、网络、参数等 “涌现”出来。现在大家做小模型是不够的,模型要先做大再做小,先“涌现”再量化、蒸馏、压缩,有了涌现效应再回到下游任务。
ChatGPT的确是一款现象级的产品,可以说是人类历史上最受欢迎的产品:短短2个月吸引上亿用户,且无广告,完全依赖用户口碑,具有全球范围的影响力。在ChatGPT横空出世的这几个月里,几乎所有的会议主题都在讲ChatGPT,它的影响力是史无前例的。2016年AlphaGo的影响力局限在中国乃至亚洲,而ChatGPT的影响力可以说是“席卷全球”,深入各个领域,各个层次的。与其他大模型不同的是,ChatGPT还开放了用户界面。很多人提到“网景时刻”、“iPhone时刻”、“GUI时刻”,而ChatGPT的影响力堪可比互联网,堪称“ChatGPT时刻”。

ChatGPT是人类第一个通过图灵测试的智能体。虽然聊天机器人做了很多年,在专有领域如智能客服等方面做的很好,但跨越领域后会出现问题,其用到的还是分析式、决策式、预测式、鉴别式AI,而不是生成式AI。其次,ChatGPT开启了强人工智能之路,通过更多的数据更大的模型我们可以走向通用人工智能。大模型用不同的微调策略,执行不同的下游任务。从产业方面讲,GPT+等各种大模型是人工智能时代的“操作系统”,在重构、重写上面的应用。PC时代的操作系统是Windows,操作系统把硬件和其他应用隔离,形成产业链,是一个时代和产业的重心。PC时代的芯片架构是x86,上层是浏览器和各种应用,然后有Client、Server服务器。在移动互联时代,由于操作系统变化,出现了iOS、Android,芯片架构也变了(CPU、GPU)。上层是垂直模型,会产生新的应用。每次产业平台的更迭所产生的效应都是超过数量级的。移动互联时代的产业机会比PC时代至少大10倍,人工智能时代比PC时代至少大100倍,比移动互联时代大10倍或更高。

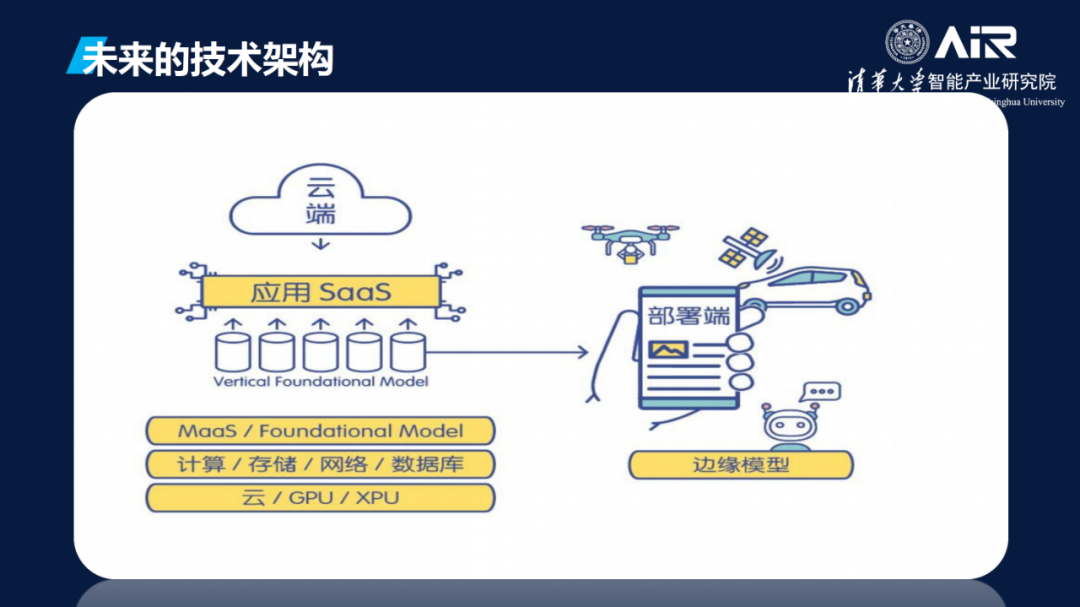
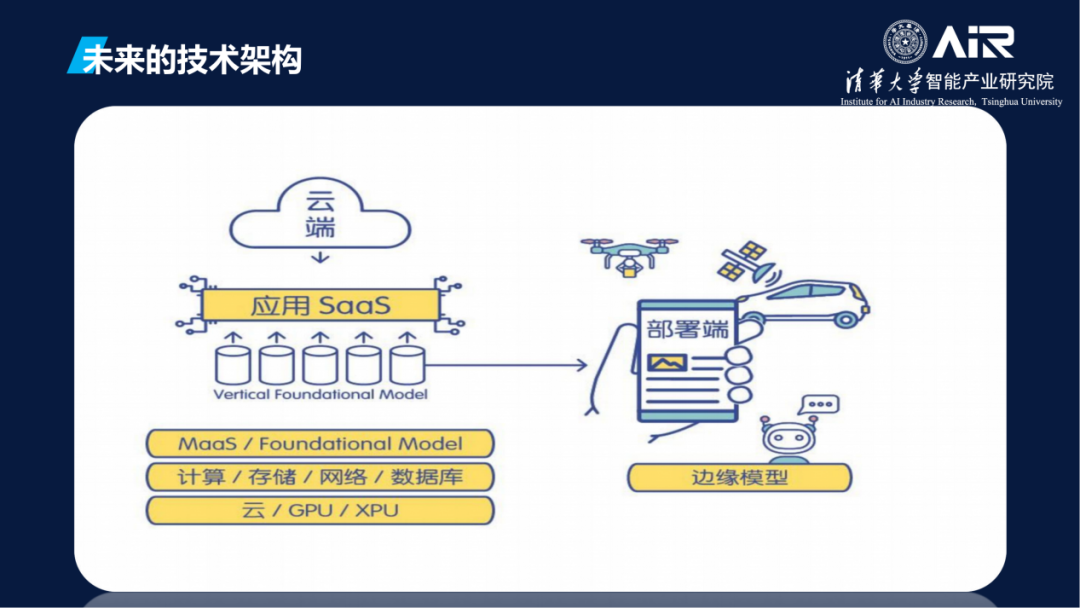
关于未来的技术架构,在云端有各种芯片,上层还有计算、存储、网络、数据库。基于大模型作为服务有垂直模型,比如自动驾驶、蛋白质解析、先进制造,模型之上可以开发新的应用。到了部署端,机器人、自动驾驶车、无人车、手机、工厂需要小的模型,要把大模型蒸馏过来变成小模型,实时化、低功耗、低成本部署。
现在许多公司和研究机构都处在“百模大战”之中,目前至少有40到50家公司在做大模型,不论初创公司还是大公司,充分竞争的市场才
是好市场,充分竞争的公司才是好公司。大模型时代才刚刚开始,42公里的马拉松我们刚跑到5公里,算力、数据不够都不成问题。中国在PC时代落后于美国,但在移动互联时代领先于美国(数字支付、微信、短视频),AI时代要给创业者、科研人员、企业更多信心。

关于AIR
最后是清华大学智能产业研究院(AIR)的简单介绍。AIR是一个面向第四次工业革命的一个国际化、智能化、产业化的研究机构。在产业方面,我们希望和产业合作来解决真正的问题、实际的问题。同时,作为清华大学的研究机构,我们肩负着人才培养的职责和使命,目标是培养未来的CTO、未来的架构师。

AIR的科研方向包括三个,也是人工智能在未来五年十年具有巨大影响力的三个方向。第一个是机器人和无人驾驶,又称为智慧交通;第二是智慧物联,特别是面向双碳的绿色计算、小模型部署到端等;第三是智慧医疗,包括药物研发等。基于计算机学科基础ABCD(Artificial Intelligence, Big Data, Cloud, Device),相关的研究工作是面向总书记讲的世界科技前沿、经济主战场、国家重大需求和人民生命的健康来开展的。

在大模型方面,基础模型需要太多算力,高校难以支持和维护。但AIR与产业紧密合作,重点致力于在三个垂直产业做三个专业模型,称为垂直行业模型,包括在部署端、边缘端的小模型。整体来讲目前大模型的效率很低,模型用的越多亏损越多。尽管大模型能力显著,但是目前工程壁垒高,很难真正落地。提高模型效率既是研究课题也是工程方向。从规模和耗能来看,人类的大脑是效率最高的智能体,它有860亿个神经元,每个神经元有上万个突触,却只有不到3斤重,耗能30瓦,从这个角度来看,人脑的储存量和效率之高,是目前任何大模型都无法比拟的。从运作层面来看,人类的大脑有很多神经元,但在解决某一个任务的时候并不调动所有的神经元,只调动某一个或几个区域的神经元,但现在的大模型在处理任务时几乎所有参数都激活了,所以如何去做稀疏的激活,如何把大模型变小,如何让模型有更好的对齐能力至关重要。最后是交互能力,模型和模型之间怎么交互?模型可以作为工具去调用其他模型,开发者也可以使用不同的模型,但模型之间怎么去联合,怎么去交互,这也是一个大课题。
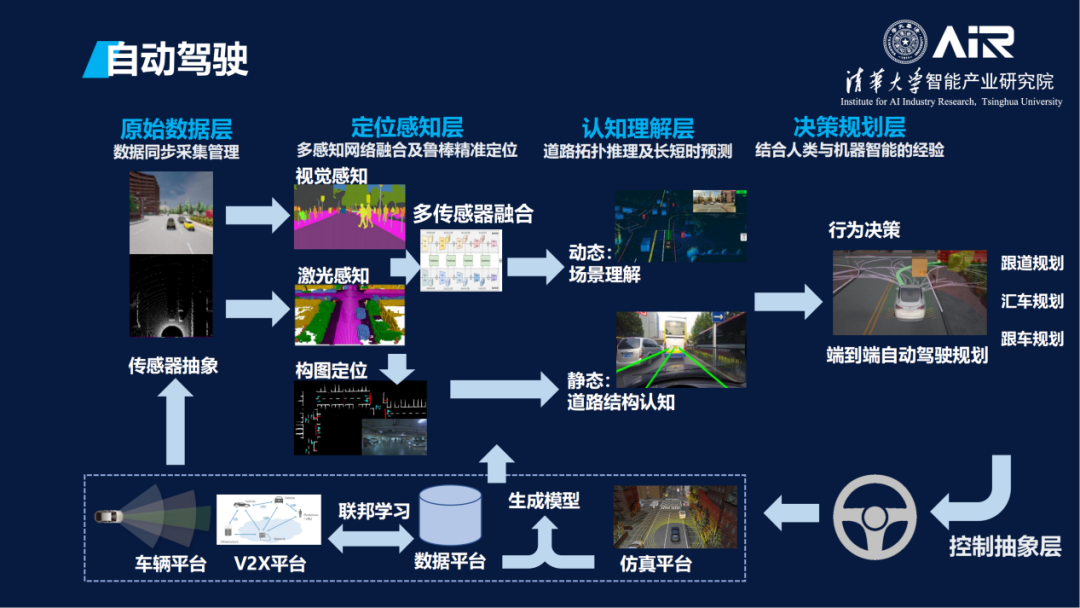
这是AIR在自动驾驶方面的一些具体工作,包含数据、感知、理解、规划四个层次。具体技术包括联邦学习、仿真模型等。
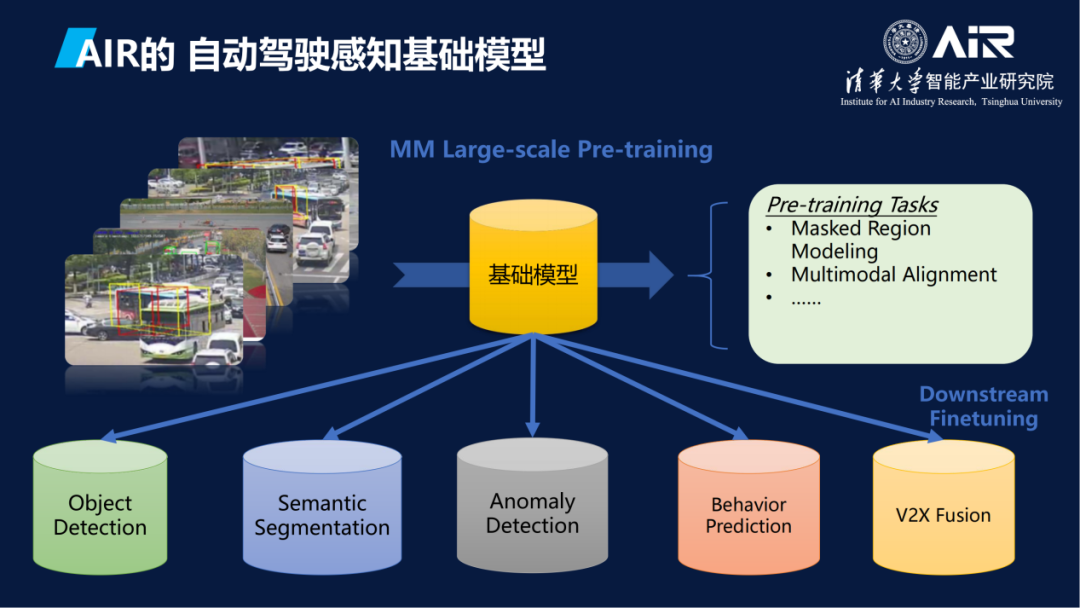
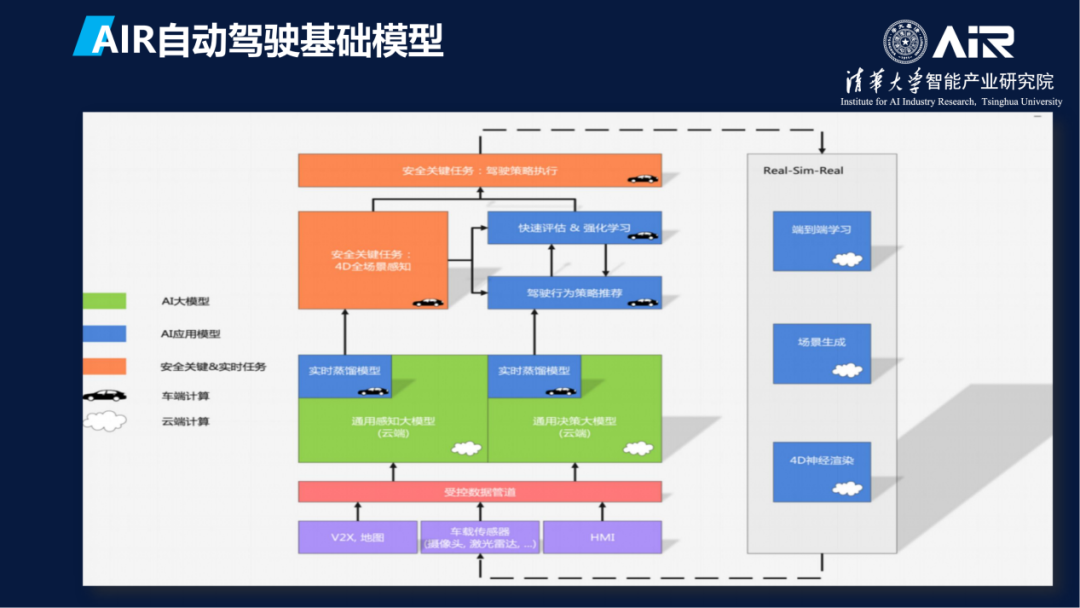
这里很重要的一点是,原来各个不同任务有不同的模型、不同的算法。AIR用基础模型把它整合到一个大的模型里面去。
AIR的模型不仅使用了基于Transformer的大模型,而且也使用了很多的强化学习基础模型。
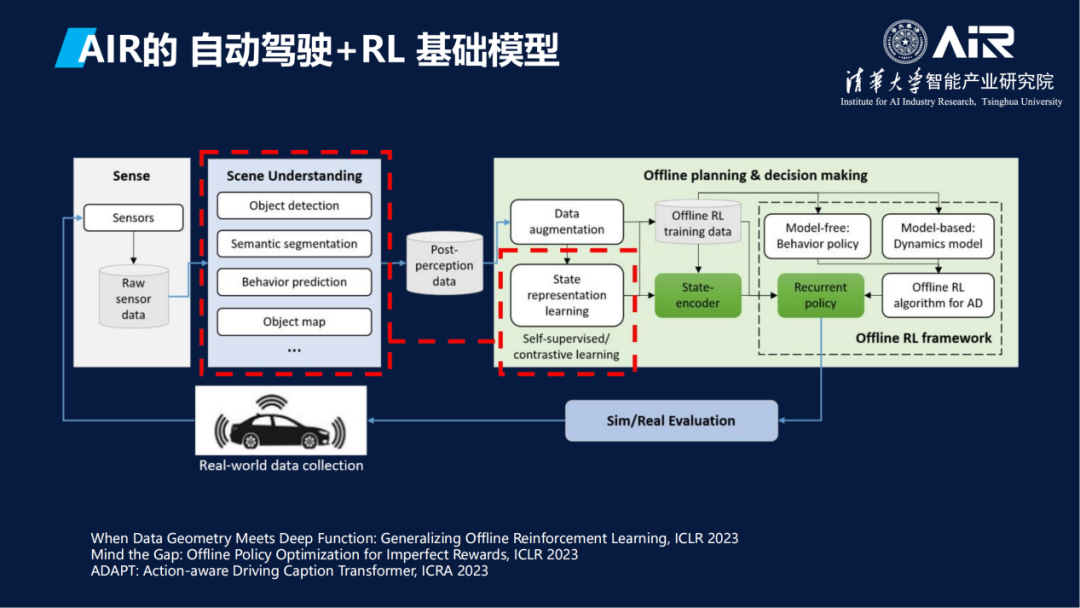
这是在无人驾驶方面的一个基础模型的框架。云、端、边缘、语言模型、决策模型、感知模型等所处的位置和相互关系如图所示。具体研究包括如何实现关键任务,用什么样的数据,如何清洗等。经过两年多的努力和尝试,AIR基本上完成了基础模型的搭建。
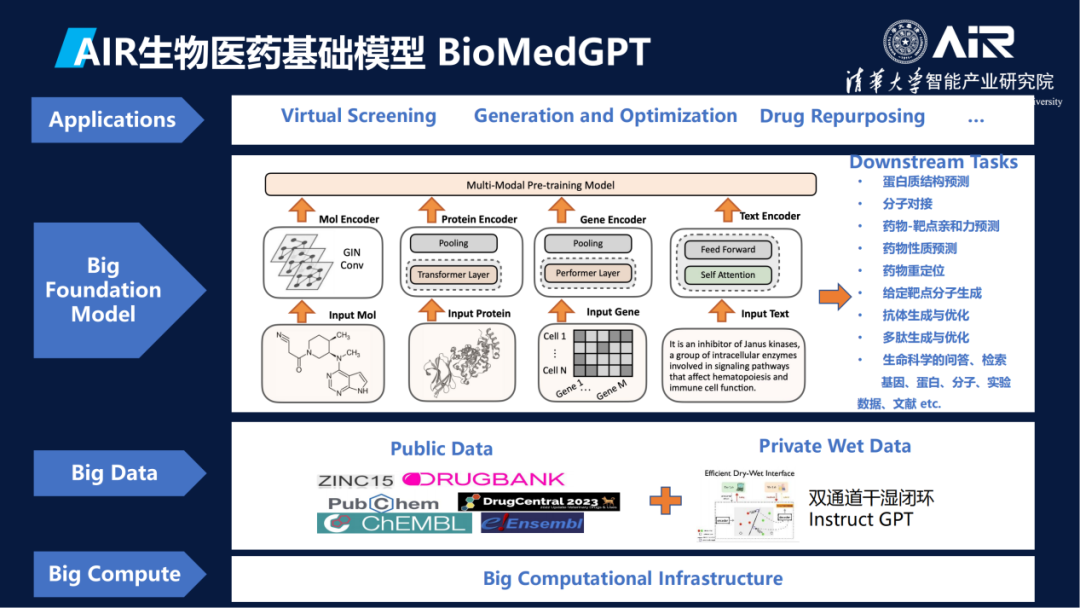
在生物医学方面,AIR刚刚宣布开源了一个轻量级的模型BioMedGPT-1.6B。人工智能学派一个是经验主义,比如用大数据、模型,另一个是用规则、知识体系、知识图谱,然后在这个模型里面试图把知识和数据相结合,里面有文献信息、专利信息、蛋白质基因、细胞等这些数据,同时AIR也有已经做好的知识图谱,集成训练出基础模型,经过一些监督微调训练,就可以做各类下游的任务,包括蛋白质结构解析、分子对接、靶点生成等。
此外,AIR还开展了蛋白质的结构预测模型研究。由AIR兰艳艳教授课题组研发的系统化蛋白质结构预测解决方案AIRFold,在蛋白质结构预测竞赛 CAMEO 上连续四周夺得全球第一。

另外,AIR也研究了基于抗体设计的模型。AIR执行院长刘洋教授课题组在人工智能辅助抗体设计领域取得新进展,相关研究成果“基于三维等变图翻译的条件式抗体设计”(英文名称Conditional Antibody Design as 3D Equivariant Graph
Translation,并于2023年3月21日获得人工智能领域重要国际会议ICLR 2023杰出论文提名(Outstanding Paper Honorable Mention)。

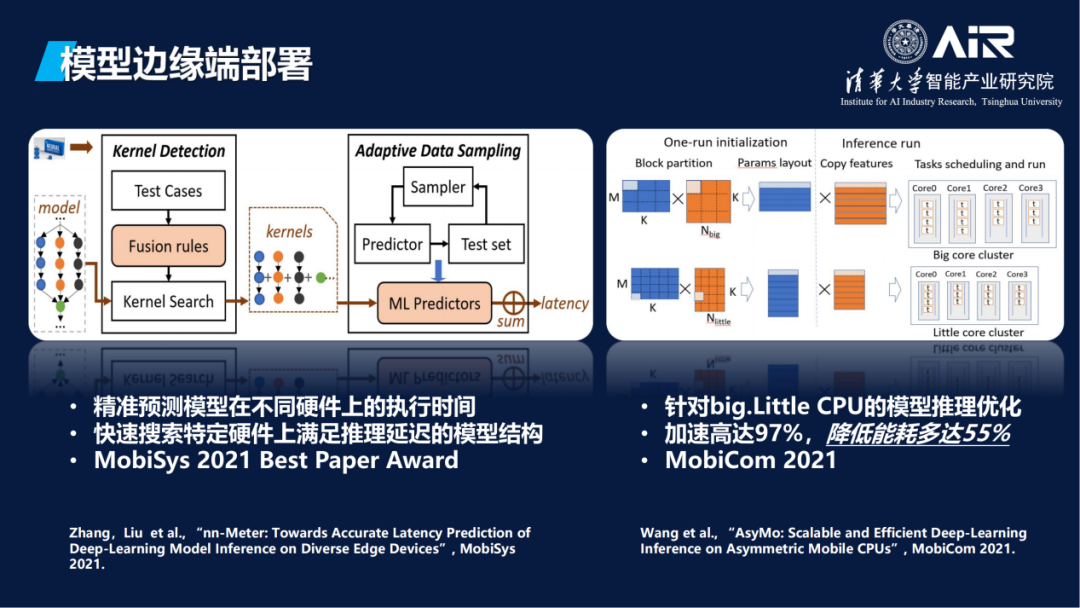
最后,AIR也研究了模型边缘端部署工作,目标是通过模型轻量化和系统底层优化等手段,支撑模型在边缘端的高效运行。其中,AIR刘云新教授课题组在边缘端模型架构搜索领域取得新进展,相关研究成果“面向多样化边缘设备的深度学习模型精准延迟预测”(英文名称nn-Meter: Towards Accurate Latency Prediction of
Deep-Learning Model Inference on Diverse Edge Devices)于2021年6月获得移动计算领域顶级会议MobiSys最佳论文奖(Best Paper Award)。
科学领域正进入一个被AI颠覆、重新定义的时代。近年来,预训练大模型和生成式AI为代表的技术在计算机视觉和自然语言处理等领域取得突破性进展,大规模数据驱动的计算范式也在深刻影响着生物、化学、生命科学等学科的科学发现模式,这对于我们理解什么是智能的本质,如何达到新的智能,为什么会达到新的智能都有很深的意义。

总结来看,我们现在正走向大模型时代,从过去多算法、多任务、多模型的数据驱动,到现在统一算法、多模态、预训练大模型的模型驱动。以ChatGPT为代表的新的技术通过了图灵测试,有了通识,点亮了通用人工智能时代的曙光。基础大模型的几个特点,包括Token-based、Scaling Law、规模效应下的涌现和统一,也是AI时代的“操作系统”。在这些大模型上有垂直的模型、开源的模型、API和Plugin,基于此打造新的2C、2B的应用生态,比过去的可能要大100倍,这也是中国企业和创新的大机遇!


*特别感谢AIR王思雨、王祎乐、及副教授李鹏对本次讲座的文字总结
AIR长期招聘人工智能领域优秀科研人员
点这里关注我们
关于AIR
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号清华大学智能产业研究院 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
-

-
北京
甲方 · 公立学校
未认证的机构号
recently released
-
2023-04-29
-
2023-04-28
提名奖")










