
- 0
- 0
- 0
分享
- 马维英:AI与新科学
-
原创 2023-04-28
近日,清华大学惠妍讲席教授、智能产业研究院(AIR)首席科学家马维英发表演讲《AI与新科学》。

本次讲座围绕AI与新科学时代的到来、了解人工智能的内在机理、以及AI在生化环材领域正在进行的创新三部分展开,从宏观的角度系统地定义了新科学,深入浅出地科普了AI的工作原理,最后从微观的角度介绍了多个AI在不同科学领域中的应用实例,为听众打开了探索未来科学的窗口。
AI与新科学时代
新科学时代
什么是新科学?马教授指出,科学是指系统性的构建和组织知识,并将知识用于理解我们所处的宇宙。而新科学的“新”指的是“模型”。各个科学领域的知识在原先基础上会出现AI模型这一新的知识形式。AI特别擅长理解高维度的数据,并从海量的数据中寻找结构、规律、模式、与关系。这一计算能力远超过人类。例如,当AI模型学习大量蛋白质序列与结构的数据后,能够理解氨基酸序列折叠的内在规律,而能准确预测蛋白质结构,这任务对人类十分困难。因此,在新科学时代,科学知识可能由人类能够理解的知识和AI模型两部分组成。
当前的科学研究中,AI通常被作为一种工具,用于高性能计算或数据分析。然而,在未来,AI在科学中的地位会进一步提高,AI可能会以自己的方式探索科学问题,并甚至通过AI的方式来发现科学问题。马教授将其总结为“AI first, of AI, by AI, for AI”。

AI for Science:What's New
当前,在生物、化学、环境和材料等领域,数字化和实验自动化进程正在快速发展。此外,科学智能(AI for Science)的革命也在进行中。
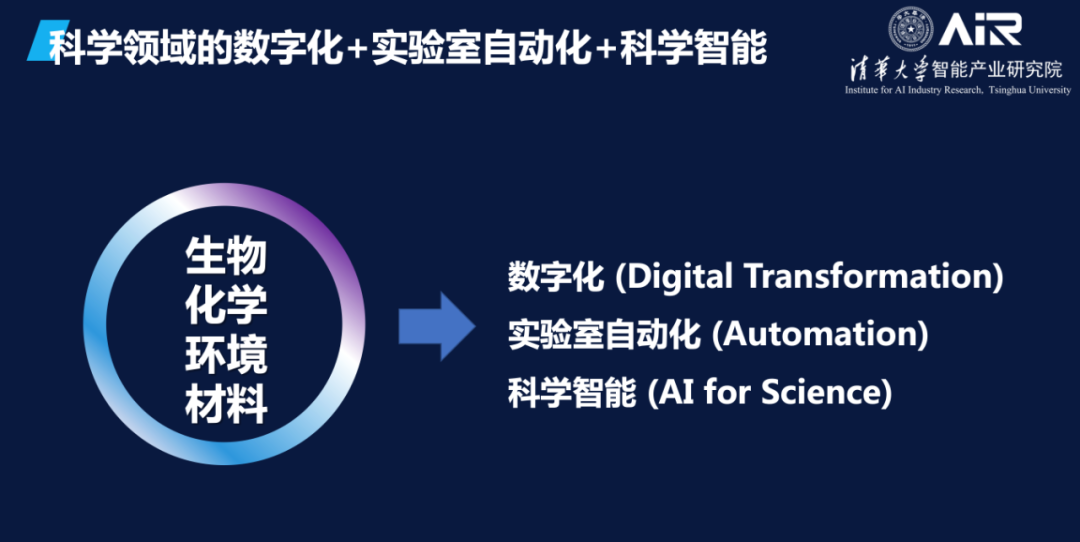
在科学领域,大量AI技术已经体现其作用,如生成式AI(Generative AI)、超大模型(Ultra large model)、多模态、预训练(Multi-modal, Pre-trained)、干湿闭环(Dry-lab and Wet-lab Loop)、自主学习(Autonomous AI)等。这些AI技术在加速科学发现方面发挥着重要作用,同时也在改变科学研究的方式和进程。

生成式人工智能最初在内容创作领域被广泛使用,例如生成图片、文字、视频和广告等。其核心目的是为创作者提供更便捷的创作方式。然而,随着时间的推移,越来越多的科学家开始探索如何将生成模型应用于分子生成,以生成新型药物。今年,ChatGPT在全球范围内引起轰动,人们开始意识到生成模型已经具备了颠覆互联网及其相关生产力的能力。同时,人们也开始注意到GPT在生物医药领域正在发生革命性变化,并有望进入其他各个科学领域。
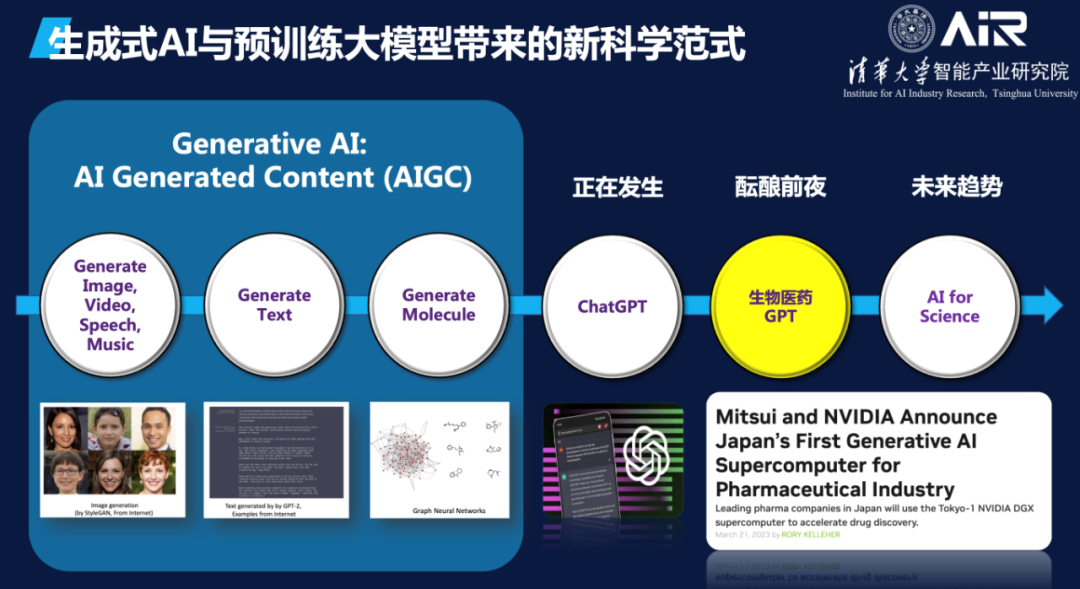
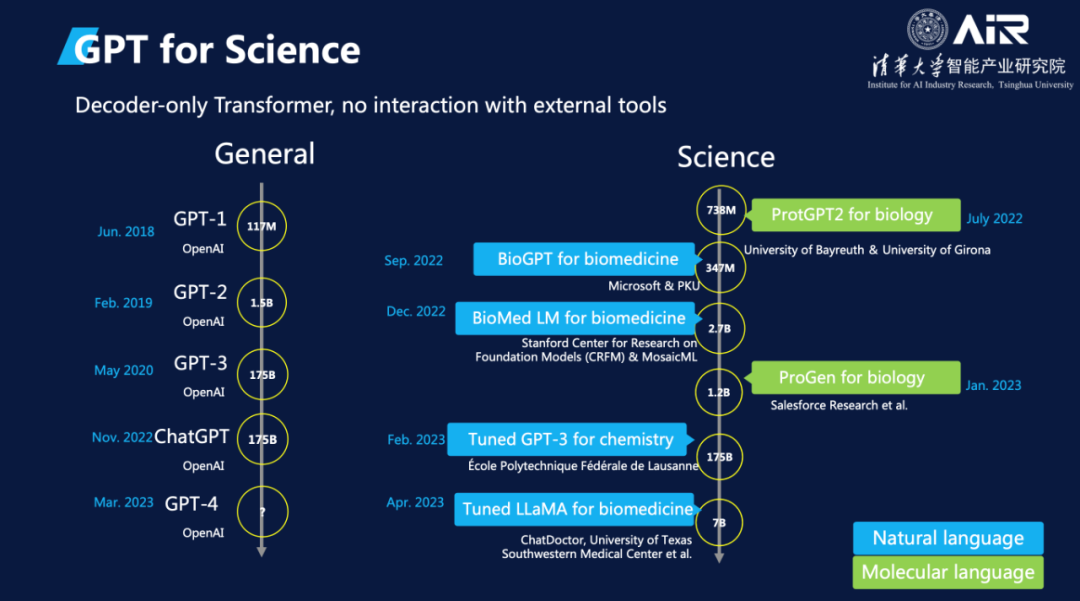
马教授总结了GPT在科学领域中的发展。如下图所示,蓝色模型代表通过自然语言训练的领域内模型,而绿色模型代表通过生物数据训练的科学模型。未来,这两种模型将深度融合,形成更加强大的生成模型。
插件技术和工具也大大增强了GPT在实际应用中的能力。当前,一些研究人员已经将化学领域的工具设备作为插件引入到GPT中,使得该模型可以综合调用搜索引擎、代码执行、文献检索、自动化实验等工具,以完成科研任务。
“已经有AI自主学习的感觉了。”马教授这样讲到。
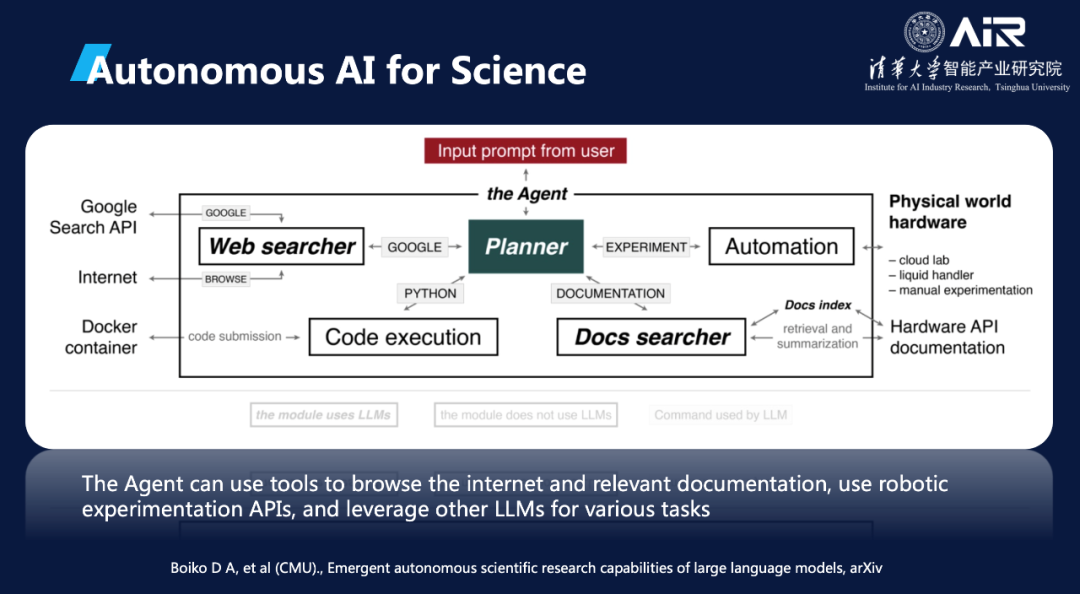
当将自动化实验室和AI模型结合起来时,就可以实现干湿闭环。干实验室可以发起一个实验请求,并将该请求交由模型处理。随后,模型会将处理结果反馈给自动化实验室,以执行相应的湿实验。在实验的过程中,自动化实验室会将实验数据不断反馈给AI模型,以帮助模型进行迭代和优化。通过这种干湿闭环的方式,AI模型可以更加高效地进行科学研究,也可以更加精准地预测和优化实验结果。
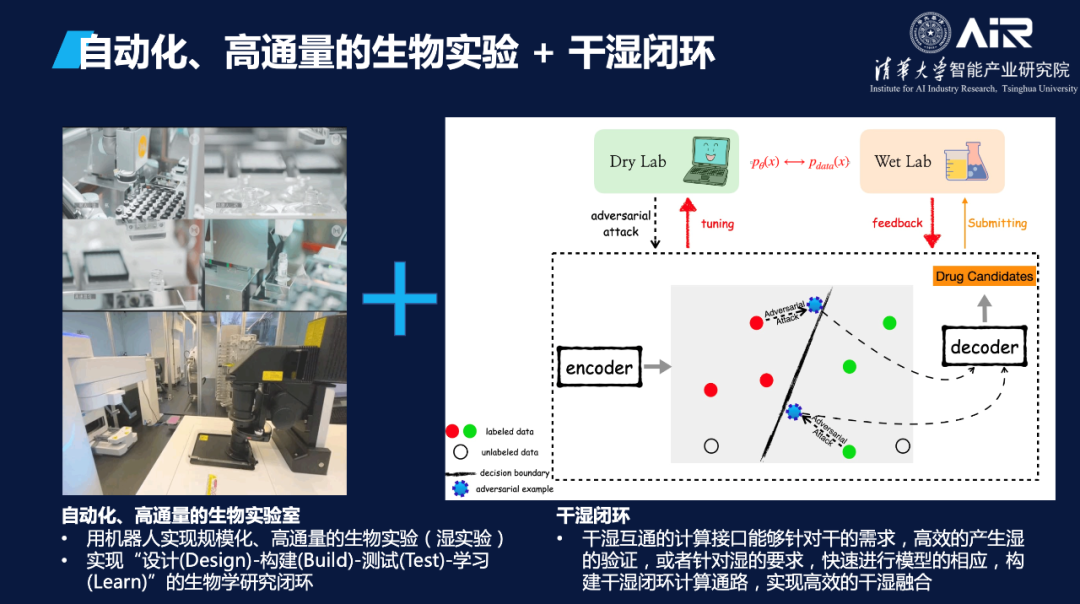
同时,AI模型还可以与药学家进行交互式药物生成。在这种模式下,药学家可以根据自身的专业知识对AI模型的生成效果进行判断,并提出相关指导和建议。这种基于药学家专业知识的AI模型生成方式被称为"Expert-in-the-Loop",即专家在循环中的应用。通过这种方式,药学家的专业知识和AI模型可以深度融合,从而实现更加高效和精准的药物研发和生成。

在干湿闭环和专家可控药物生成之间,还需要一个药物基础大模型来不断累积数据和知识。这个大模型可以基于已有的数据集和知识库进行训练和优化,从而实现更加精准和高效的药物生成和研究。当干湿闭环和专家可控药物生成与药物基础大模型相结合时,AI在科学方面的能力将得到进一步的推进和提升。这将为药物研发和生成带来更多的机会和可能性。“如果我们能够创造这个闭环,AI在科学方面的能力将大大推进。”
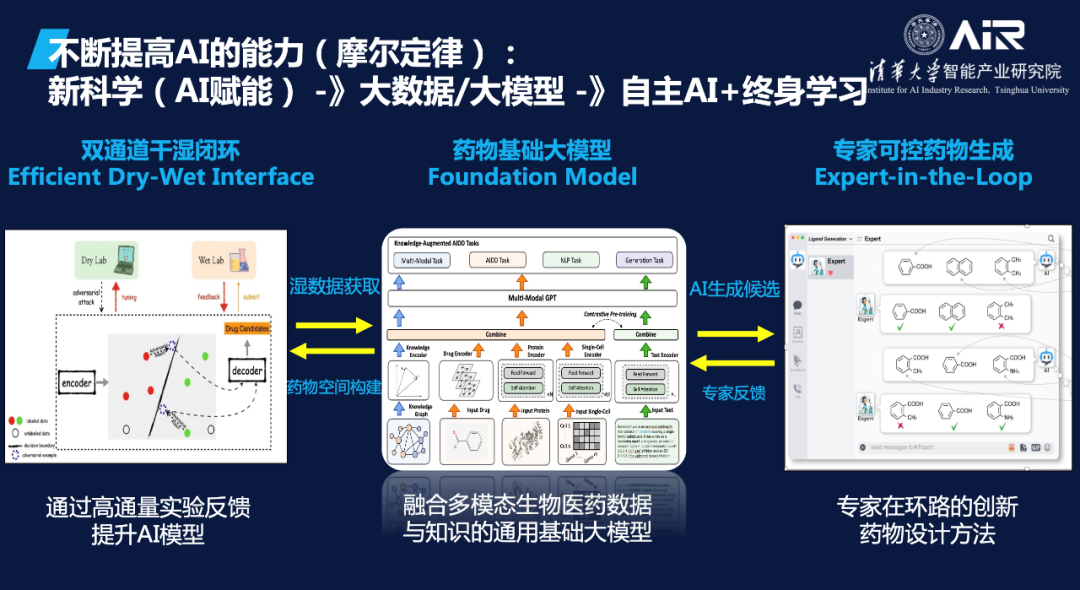
AIR于近期开源了轻量级科研版基础模型BioMedGPT-1.6B。聂再清教授课题组构建BioMedGPT的目标是要把分子语言中蕴含的知识以及长期以来通过湿实验总结的文本和知识图谱信息融合压缩到一个大规模语言模型中,从而实现从序列模式中学习生物结构和功能规律,通过AI解码生命语言。
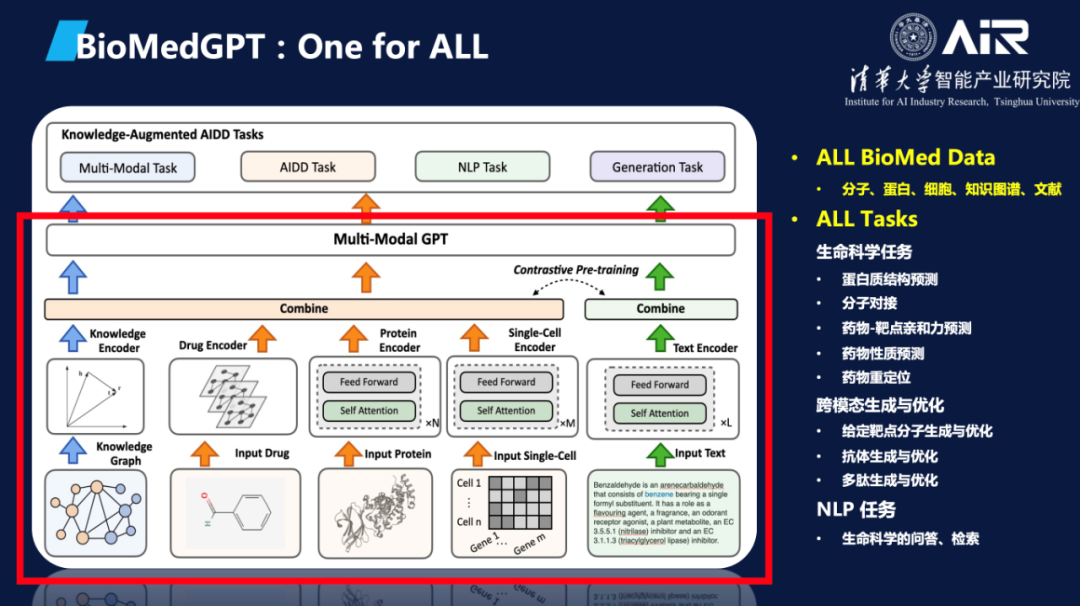
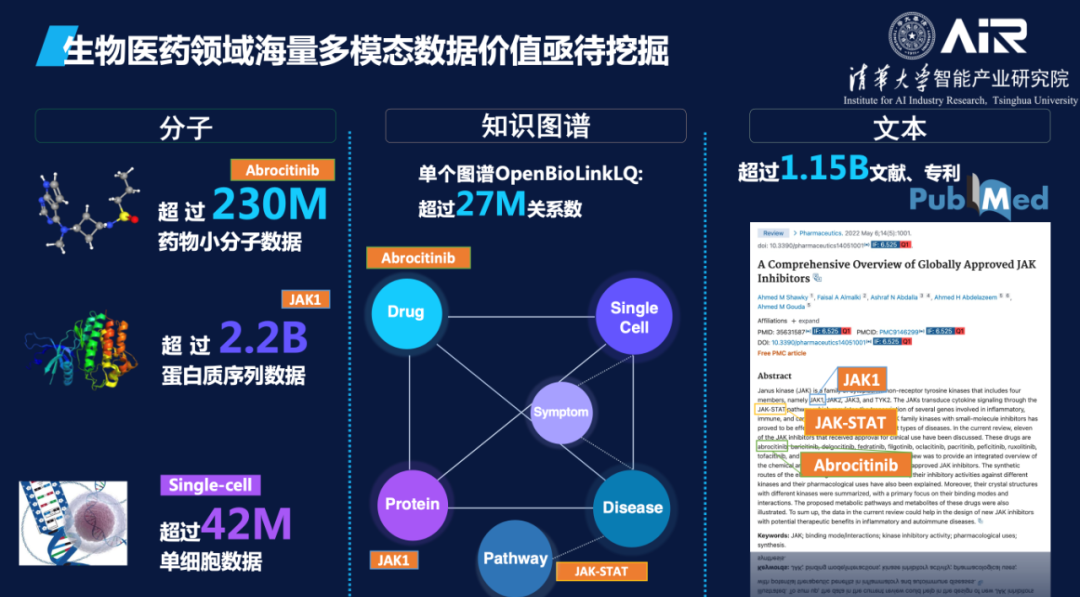
生物医药领域通过湿实验积累了很多有价值的知识和数据,很多都可以公开获取使用,如蛋白质序列目前已有超过22亿条数据,可购买的具备成药性的小分子有2.3亿等。这些海量公开分子序列数据其实完全可以用语言模型来学习其语义表征,用于药物研发任务。同时,现存也有许多生物学家们几百年来积累的海量文献和知识图谱数据,无论知识图谱还是文献都可以单独训练出一个大的知识表征模型,而且这些不同模态的数据里的分子信息是相互关联的,如果能把它们统一压缩在一个大模型里,将惠及未来所有的生物医药下游任务。
BioMedGPT在数据层面整合了基因、分子、细胞、蛋白、文献、专利、知识库等多源异构的数据,首次将知识引入到模型构建中,实现了生物世界文本和知识的统一表示学习,增强了模型的泛化能力和可解释性。在应用任务方面,BioMedGPT能够处理自然语言、药物性质预测、跨模态生成等多个任务,实现对生命科学全域任务的探索,已经在多个关键下游任务中取得了 SOTA 的效果。
了解人工智能的内在机理
生成式AI
为了更好地理解生成式AI,我们需要了解其涉及的三个关键阶段:目标、概率建模和参数化。
“生成式AI的本质目标是拉进两个分布。”马教授简明扼要地总结了生成问题的本质目标,即让AI学习到的分布尽可能的拟合真实数据的分布。只要AI模型能逼近真实的分布,就可以通过采样生成各种模态的数据,如图片、文本、乃至蛋白质和小分子等。如图里表示的,这两个分布一个是P-data,即数据本身的真实分布,是不可知的。另一个是 P-theta,是我们要用模型参数theta去近似的分布,只要P-theta学的足够准,和P-data一样,那从P-theta模型里采样出的样本点就和从真实数据中采样出来的一样,就算是生成了这个数据。
在这个目标下, 生成模型主要是分成两部分:第一,我们需要考虑用什么模型来建模这个概率分布,要拉近这两个分布,从概率上应该怎么拉呢?概率模型是什么?现有的一些比较常见的如自回归模型,就是GPT采用的,还有如VAE,GAN,Diffusion等等,其实就是不同的概率建模,这些方法各自有其优点和局限性。在不同的概率建模后面,具体P-theta用什么参数来参数化,现在用的多的就是Transformer。Transformer是一种强大的神经网络结构,可以有效地捕获数据中的长程依赖关系,从而提高模型的性能和泛化能力。
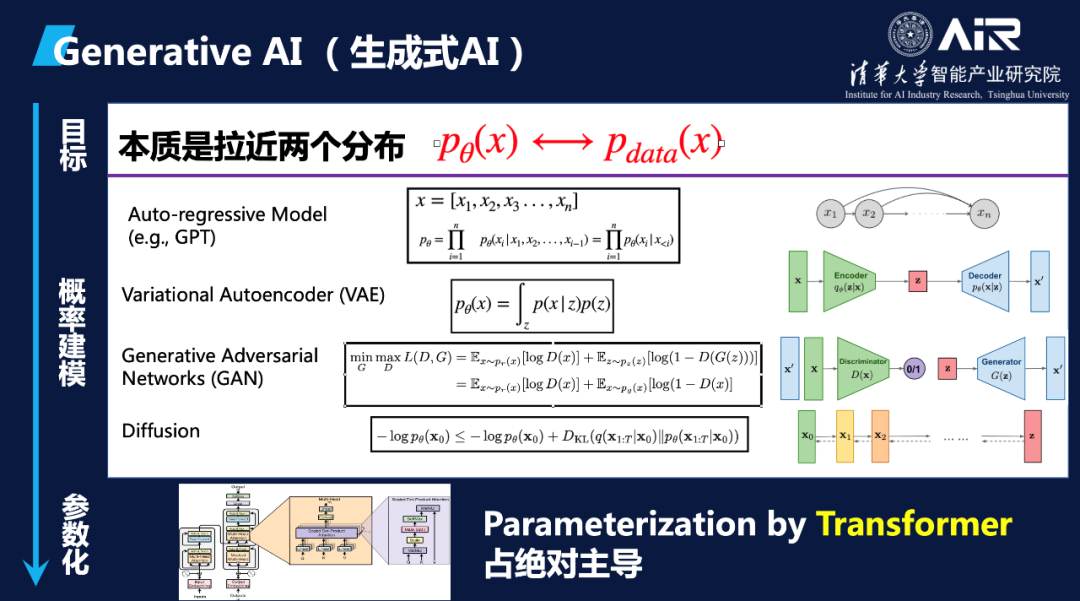
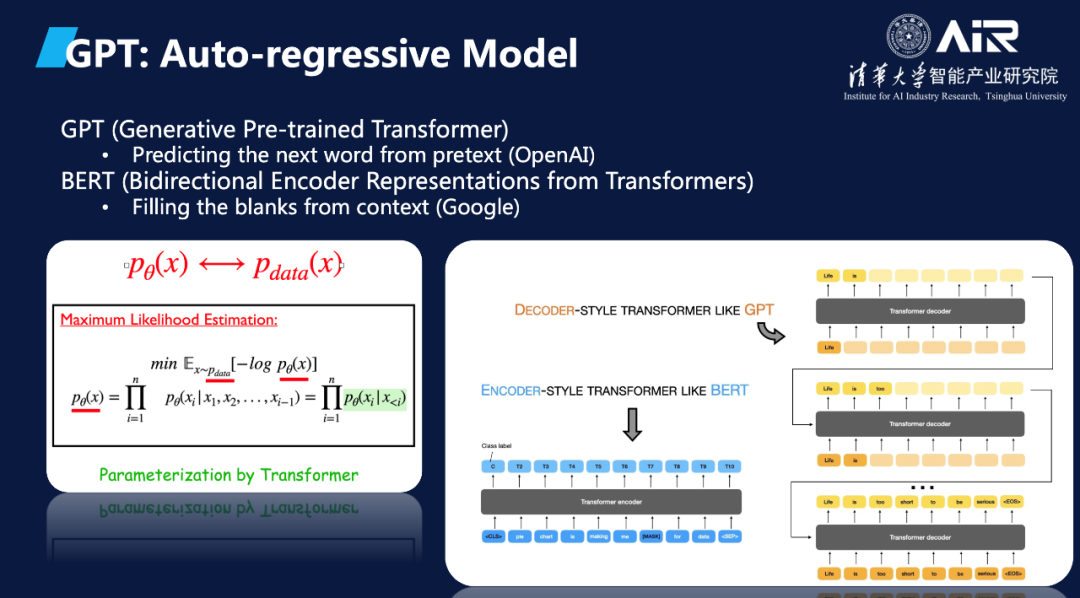
马教授进一步讲解了两个著名的大规模语言模型范式:BERT和GPT,并在GPT的基础上介绍了OpenAI提出的InstructGPT(ChatGPT的前身)
智能涌现和过度参数化
智能涌现是指当模型参数量增加到一定规模时,模型的性能会突然提升,这与传统观点认为模型性能随参数数量呈线性增长的看法不同。马教授还介绍了大模型里Double Decent的现象,还有过度参数化(over-parameterization)和过度拟合(Over-fitting)是不同的概念。当模型参数数量增加时,效果将呈现U型变化,即随着参数数量的增加,模型的性能先得到增强,然后随着参数数量的进一步增加,模型性能开始下降。然而,当模型的参数数量达到一定阈值时(Interpolation threshold),模型会进入过度参数化阶段,此时随着参数数量的进一步增加,模型的性能会再次提升,这与传统机器学习对大模型性能的了解不太相同。
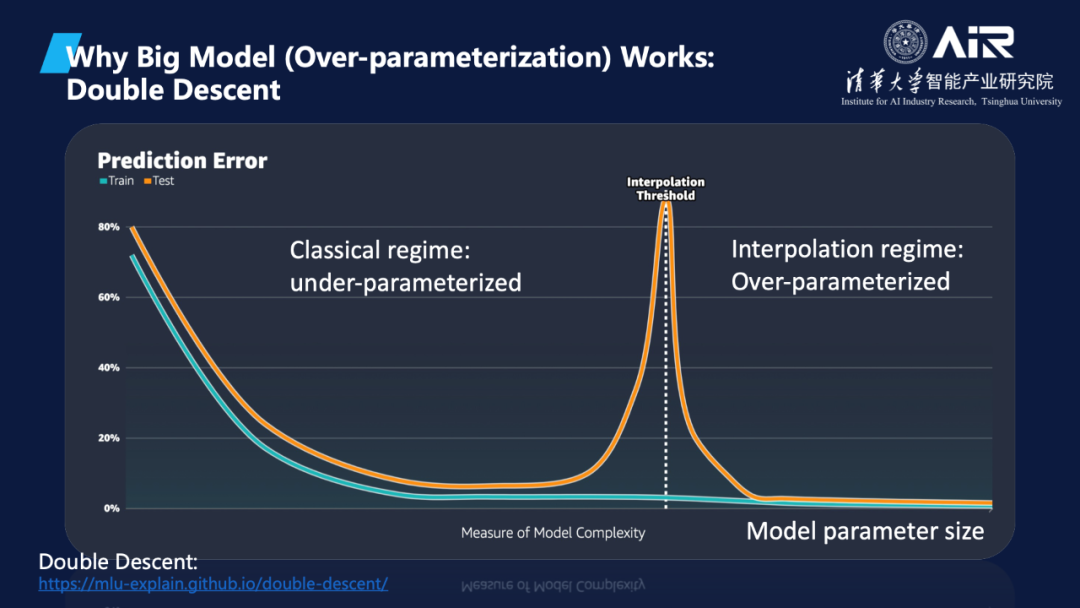
“很多时候做科学研究,我们会有一个局限的认知,一直在门口不敢再往前,但是冲过去发现居然是这样。”马教授对这一现象进行了提炼升华。
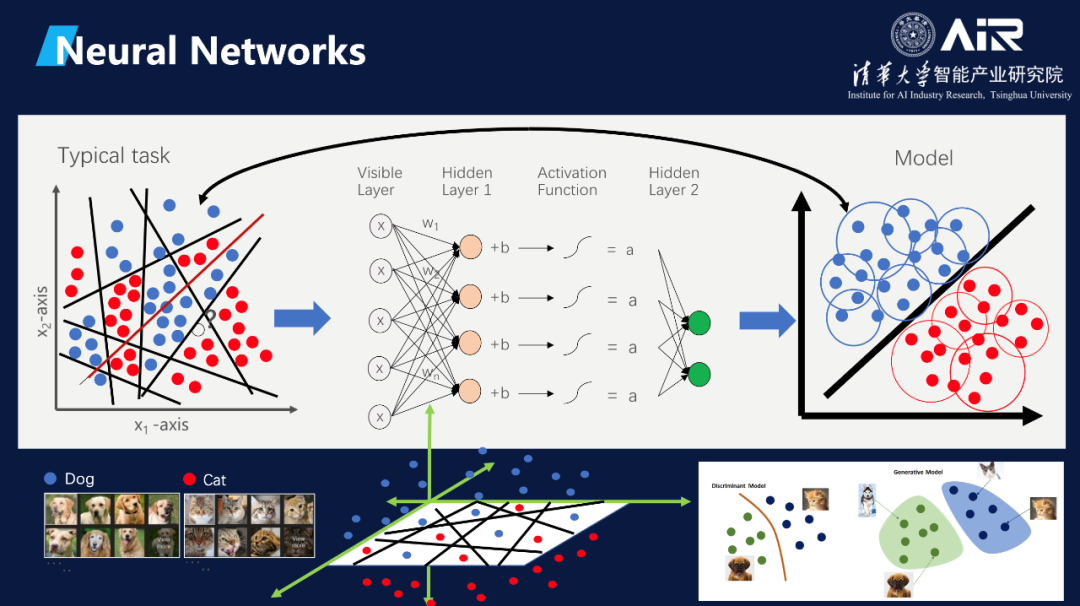
随后,马教授用猫狗图像分类问题为切入点,结合生动的图表与动画为听众介绍了深度神经网络是如何学习和工作的。
AI在生化环材领域正在进行的创新
蛋白质工程与抗体设计
早期的自然语言处理中,语言学家设计了大量规则来建模语言,后来逐渐被统计的方法取代,直至当下的生成式AI。有趣的是,如果我们将蛋白质序列视为一种语言,就可以将蛋白质和自然语言处理领域进行比较。当下的很多基于规则的蛋白质理解或设计方法都具有被AI模型增强甚至取代的可能性。如下图所示,我们可以很容易地找到与自然语言处理领域相关的概念,在蛋白质领域中进行类比。

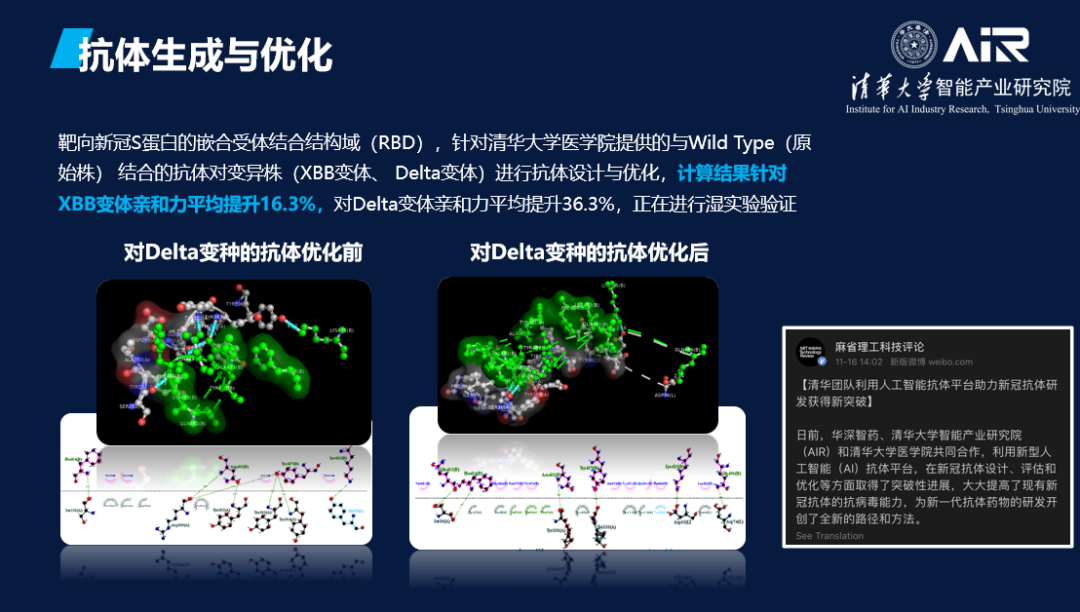
AIR智慧医疗团队在抗体设计领域进行了大量研究工作。我们与清华大学医学院张林琦教授团队合作,对人体内的新冠中和抗体进行了定向优化,使得其中和能力超过了人体能够提取出的最佳抗体。“等于说用AI将一个三流的学生优化成了一个一流的学生。”这项工作也曾被麻省理工科技评论报道。
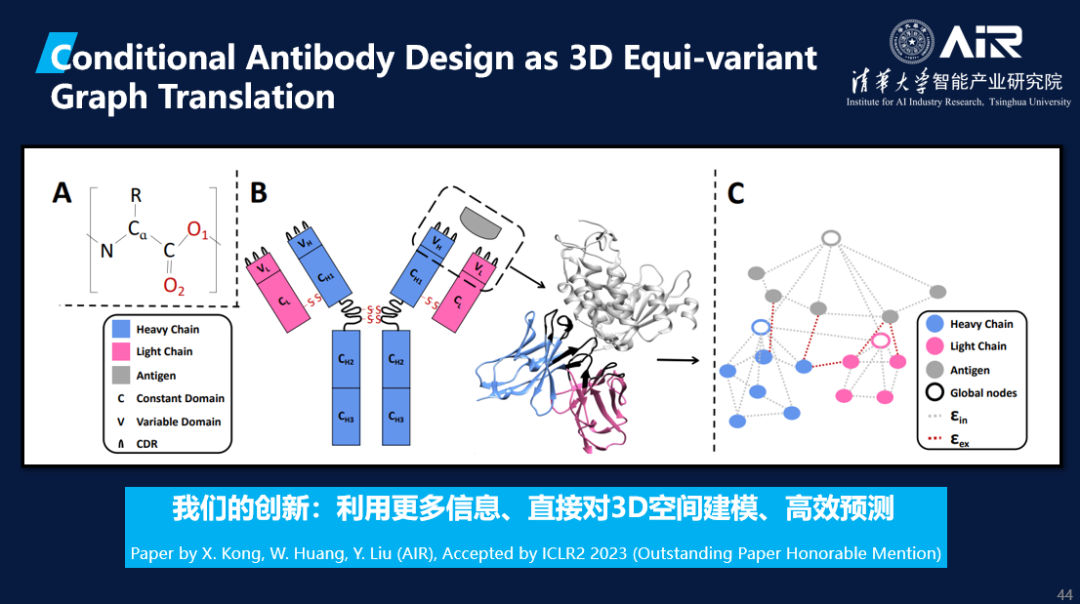
近期,AIR在抗体设计领域取得了新进展,AIR执行院长刘洋教授课题组论文《Conditional Antibody Design as 3D Equivariant Graph Translation》使用了图学习的方法,通过将抗体的CDR区视为一个翻译问题来设计抗体。这篇论文获得了ICLR2023 Outstanding Paper Honorable Mention。
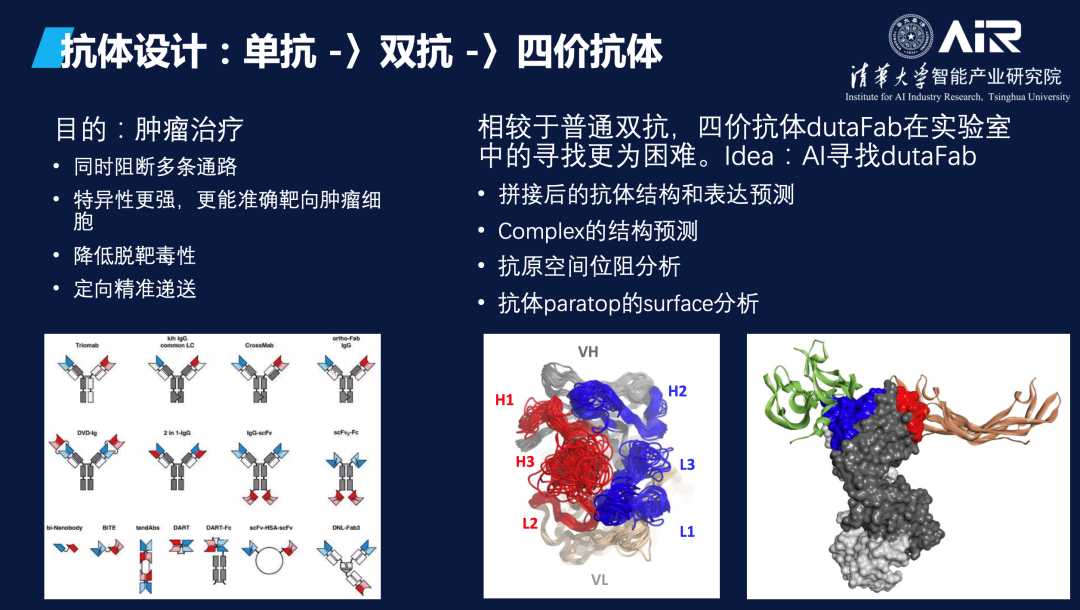
目前,AIR团队正在和Helixon一起研究双特异性抗体和四价抗体的表位设计,这些抗体在肿瘤治疗方面具有巨大的潜力。
小分子药物与酶设计
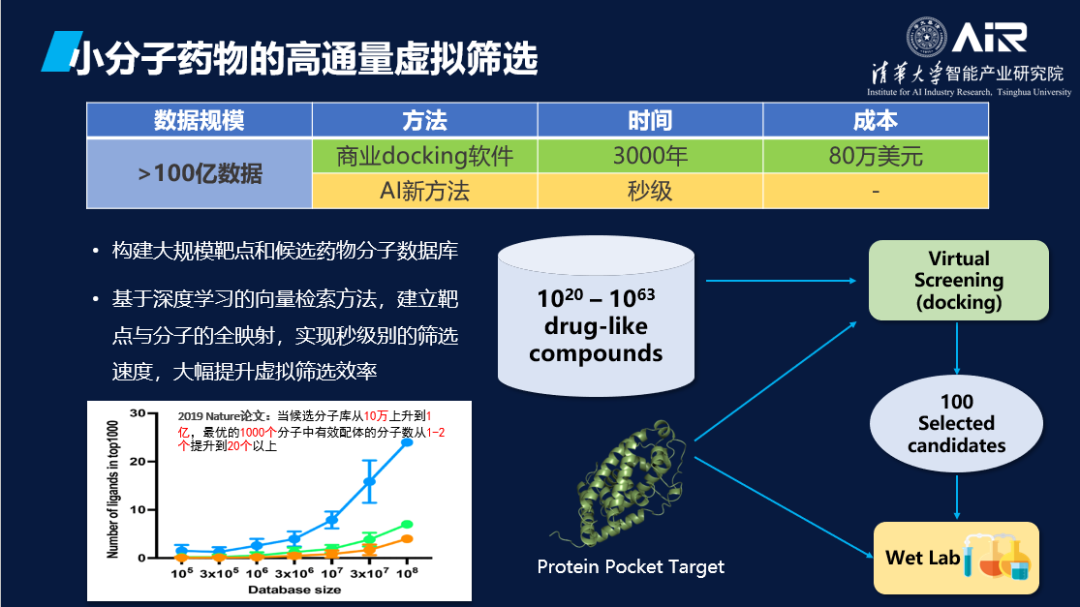
小分子药物的种类非常多,传统的高通量虚拟筛选成本高昂。例如,如果需要进行100亿规模的虚拟筛选,可能需要耗费3000年的时间和80万美元的成本。然而,使用AI模型则有望大大加速虚拟筛选的过程,并在秒级时间内完成这一任务,这具有广阔的应用前景。
药物设计和酶设计是两个重要的问题,前者是给定蛋白质,寻找可以作用于其上的小分子,后者则是给定小分子,寻找可以催化其反应的蛋白质。将这两个问题结合起来思考非常有趣。
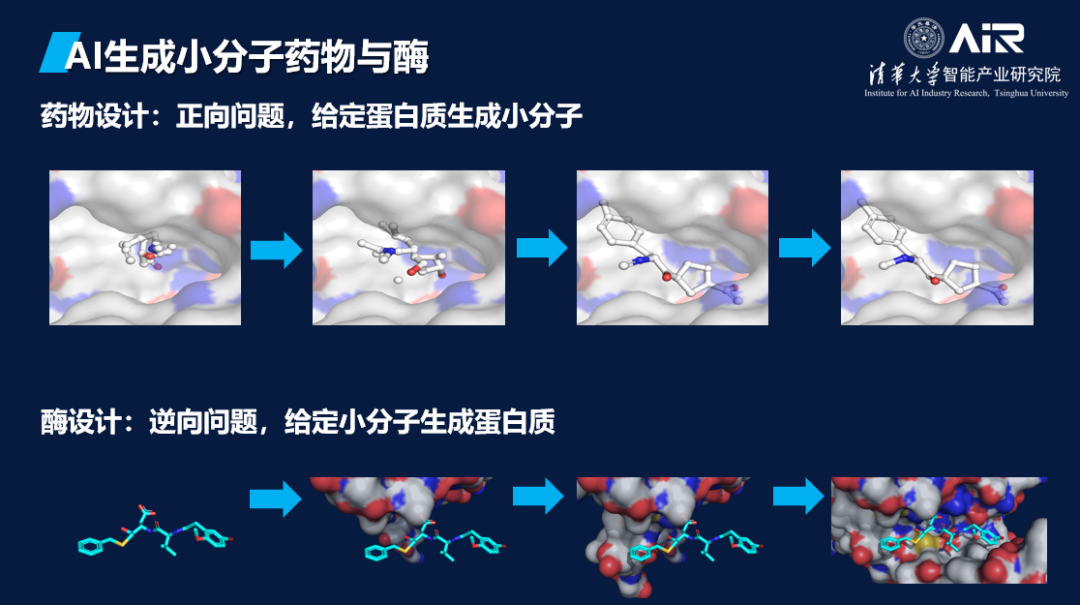
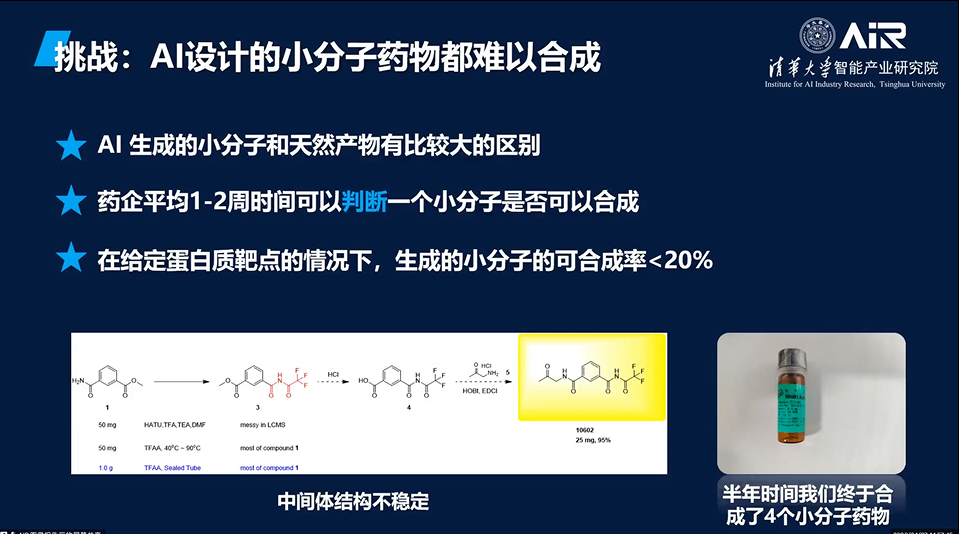
AI设计小分子也面临着很多挑战。例如,生成的分子不能和靶点之外的蛋白相作用,否则会导致副作用等不良影响。此外,AI设计的小分子药物通常难以合成,因为这些分子结构复杂、多样,需要经过多步的合成过程。但这些问题都在逐渐得到优化和解决。

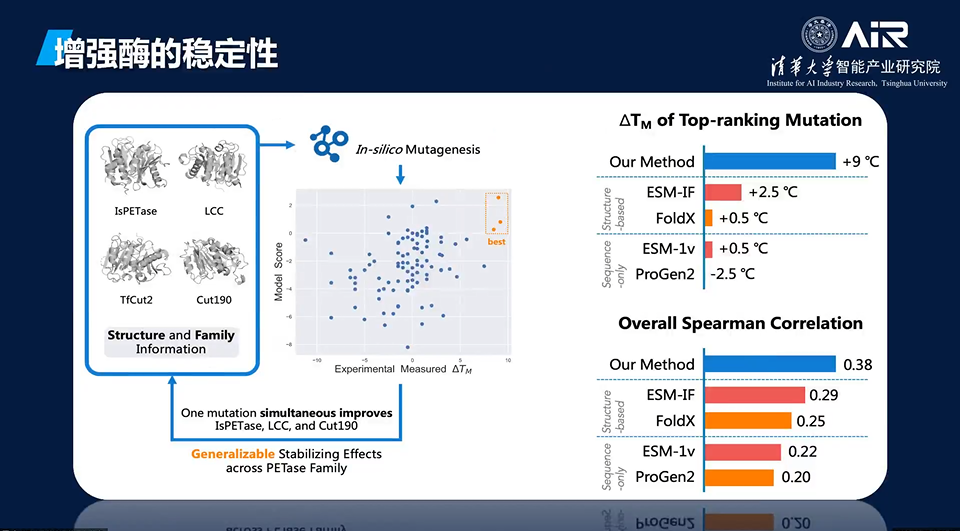
AI模型已经被用来优化酶,例如增强酶的稳定性。我们团队也在进行一些研究工作,已经能够大大改进设计的酶的稳定性。
新材料设计
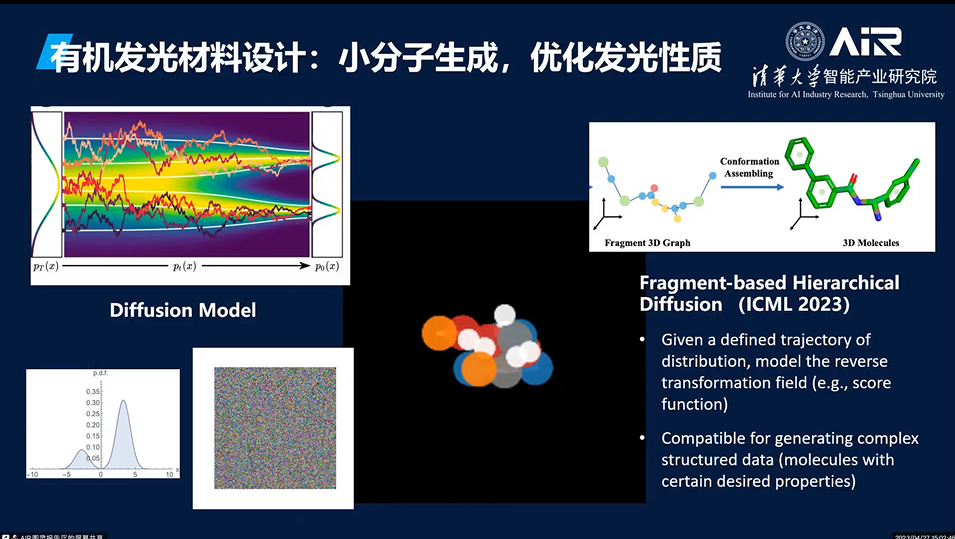
随着柔性显示等领域的发展,有机半导体材料越来越多地受到人们的关注。有机半导体材料良好的成膜性质及其可溶液加工的特点使器件的制备较传统的无机材料更简便,成本更低廉。在柔性显示、传感器和可穿戴设备等领域具有非常广阔的应用前景。
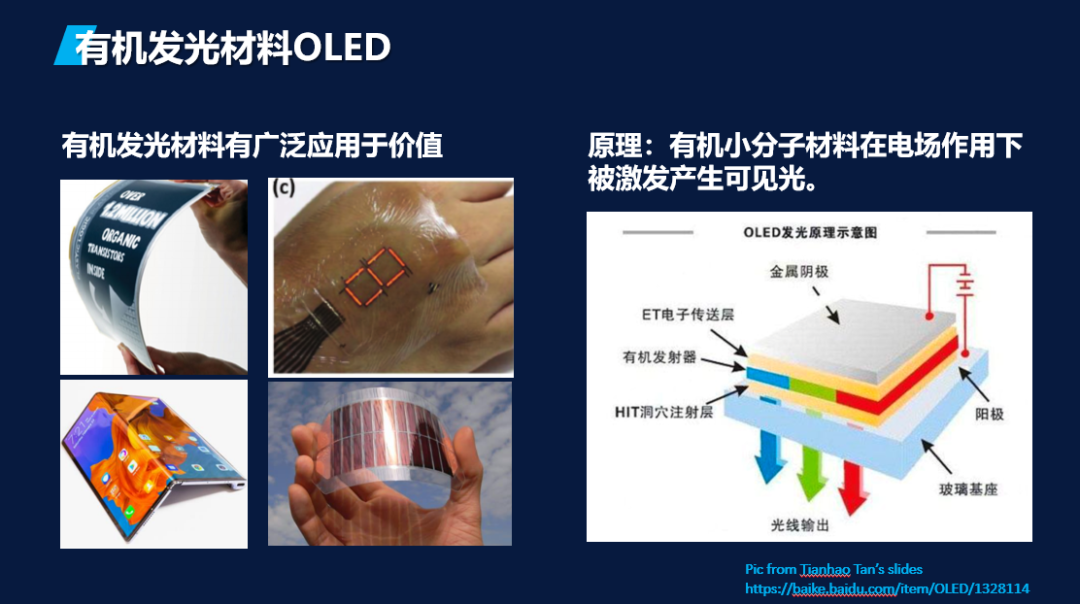
有机发光分子的空间结构巨大,其设计往往需要考虑多种因素。传统的设计方法往往依赖于人类的经验和知识,而难以覆盖整个设计空间。因此,利用人工智能进行有机发光分子的设计具有巨大的潜力。例如,通过利用深度生成模型,如diffusion模型,可以对有机发光分子进行高效的设计。
总 结
“这个领域有非常大的科研机会,科学是无尽的前沿,我认为一切才刚刚开始。”马教授这样总结。
的确,AI+新科学是一个非常新颖且前沿的领域,它们的结合为我们带来了非常多的机遇和挑战。它可以进一步加深我们对自然世界的理解。通过AI的技术手段,我们可以处理更加复杂和大量的数据,探索我们过去从未探索过的现象和规律,从而推进新的科学发现。欢迎对AI for Science感兴趣的科研人才加入这一领域,一起推动科学事业的进步。“一切刚刚开始,一切皆有可能。”

AIR长期招聘人工智能领域优秀科研人员
点这里关注我们
关于AIR
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号清华大学智能产业研究院 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
-

-
北京
甲方 · 公立学校
未认证的机构号
recently released
-
2023-04-29
-
2023-04-28
提名奖")










