
- 0
- 0
- 0
分享
- 自动生成拓扑、自动Blendshape拆分!FACEGOOD发布全平台桌面级表情动画软件
-
2023-04-14
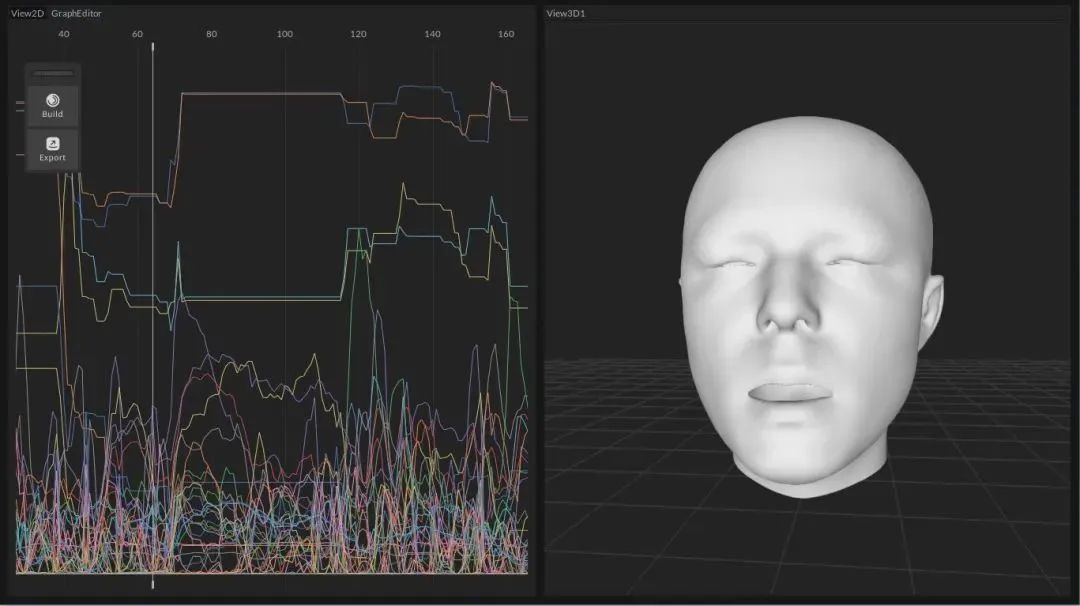
桌面级表情动画软件Fogo
FACEGOOD近日发表了桌面级表情动画软件,为动画师而生,为动画制作献上高精度表情软件。在正式介绍之前我们先来看一下表情动画的基本原理。生物的表情是数字动画成本最高最复杂的部分,一个精密的表情绑定需要耗费大量时间,精确驱动一个精密的绑定系统从而把它的潜能完全发挥出来也是一个艰难的课题。
目前在实时渲染场景中主流做法是基于骨骼点跟表情体Blendshape的做法去模拟真实软体的变形,可以看到无论是Metahuman,还是ziva rt都使用了类似的方法也做到了一些基本的效果,这取决于参数的数量级。在最新的战神游戏中,表情体已经高达5000多个,是Metahuman的十倍之多。在离线渲染场景,可以基于计算力学当中经典的方法“有限元法”去模拟真实软组织的变形,这种做法效果最接近真实生物的表情,但是计算量很大,往往需要经过AI进行简化才能实时调用。

FACEGOOD 骨肌引擎
在完成绑定后就进入了表情动画环节,表情动画传统做法基于手工从Breakdown、Blocking、Polish分了三步逐层细化最终得到动画,这个过程非常耗时,以一般电影级别的表情动画为例,一天只能做24帧动画,也就是1秒。
在技术发展下,市面上的表情捕捉方案主要是动捕级,是在动作捕捉场景下使用,配合动作捕捉,在动捕棚捕捉演员的表演,经过人工智能技术将表演自动转化为表情动画,这个过程节省了大量时间,因为动画是实时产生的,产能是手工方式无法比的。这个流程是动捕级表情捕捉流程,专为演员在需要动捕的场合下使用。
 动捕级表情捕捉方案
动捕级表情捕捉方案
目前在PGC(平台制内容)的场景中多数基于动捕级的表情捕捉方案,除了配合动捕使用之外,多演员,大批量高精度表情动画解算是动捕级表情捕捉方案的主要特点。
但是在UGC(用户制内容)领域长期以来缺乏好用的,高精度的表情捕捉软件,目前AIGC技术突飞猛进,数字人的应用场景越来越广泛,伴随着表情效果差,开关嘴、唇音不同步、表情不同步等问题越来越突出,已经变成制约数字人发展的卡点。
因此,我们看到业内的一些公司发布了一些新技术解决数字人表情动画问题,例如前段时间发布的Metahuman Animator仅仅通过一部苹果手机就达到了不错的效果,它的原理类似于Faceshift软件,基于一个深度摄像头的3D点云信息,增强了表情解算,得到了不错的表情效果。

FACEGOOD 3D摄像头
FACEGOOD专注于软体动力学研究十年,目前已成长为国际领先的产研公司,他们表情绑定的技术路线基于自研“骨肌引擎”来解决生物软组织的变形问题,属于一种工业级的非线性的完全可微的数学表达,因此在绑定精度上没有理论上限。而在表情动画驱动上,FACEGOOD完成了从动捕级到桌面级的产品研发,产品广泛应用于全球各大知名PGC企业及团队,其中包括天美、游戏科学、UBI(加拿大)、SEGA(如龙)、叠纸、玄机等。
近日,FACEGOOD对外发布了他们的新产品Fogo,Fogo的定位类似Metahuman Animator、Faceshift,是面向动画师的桌面级的高精度表情动画软件,用户只需要一台iphone手机就可以使用,据研发团队介绍说,Fogo支持高精度实时表情捕捉跟超高精度4D点到点离线解算,也就是同时支持实时跟离线两种不同精度的解算模式,4D点到点的驱动方式跳过了绑定直达最高精细度,因为我们知道无论是ziva rt还是说metahuman这种标准化的绑定形式的bs跟骨点的上限就是动画上限,点到点的驱动方式不受这个限制。

FACEGOOD 3D摄像头效果(右)
Iphone等手机级别的民用3D摄像头精度有限,尤其会丢失人脸上的高频特征,为了达到更高的精细度,FACEGOOD牵手3D摄像头研发商共同研发了新一代3D摄像头,该摄像头在被动深度视觉算法下,可以达到每秒60帧密集3D点云实时重建。
FACEGOOD介绍到,目前深度摄像头有两大流派,其一以Primsense、苹果为代表的使用结构光的主动式深度摄像头技术路线。其二是以Realsense为代表的基于双目视觉被动式深度摄像头技术路线。主动式路线缺陷是无法在强光下使用,因为结构光会被光线干涉,另外主动式一般的工作范围是数十厘米内,超出这个范围后光线的强度会因为散射导致失焦从而无法解算3D点云。而被动式路线可以做到高精度的同时,实现远距离,极高的光线鲁棒性。
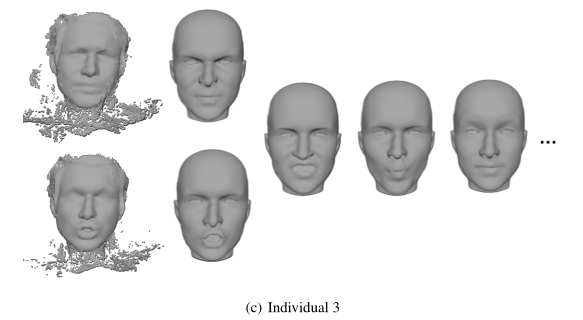
在算法上,FACEGOOD近日公开了一篇论文深入介绍了基于深度摄像头进行高精度表情捕捉的思路,文中介绍到主要难点在于高精度3DMM、通用的实时点云融合、噪音去除。
传统的3DMM在人脸重建上无法满足高精度需求,FACEGOOD团队联合清华大学Thuhcsi实验室共同研发了新一代3DMM模型,解决了高精度人脸重建问题,另外该成果已经投递国际顶级学术期刊,论文及数据集将会开源。
改进后的3DMM只用于人脸3D重建的初始化阶段,初始化之后需要进行实时点云融合,最终通过自动拓扑算法弥补重建误差,完成网格重建及Blendshape自动拆分,Blendshape的数量级可以自定义,因此在精度上没有理论上限,用户可以根据自身需要自定义。
在噪音去除方面,传统的基于解析的算法通常会有很严重的副作用,具体体现在曲线相位跟幅值上会发生不可逆的损伤,也就是在动画的节奏跟表情幅度上有显著减弱,因此是一种有损的噪音去除方法,FACEGOOD提出了一种基于预测的方法,在高频,低振幅的噪音去除上有很好的表现,最终得到的动画丝滑如玉。

跨平台使用
在软件上,Fogo是一个开放式架构,支持所有主流的DCC软件,这里包括Maya、3DMax、Blender、Unreal、Iclone、Unity等,同时Fogo不仅限于表情捕捉,根据官方介绍,Fogo的定位是表情动画软件,因此后续会加入自动化绑定、动画自动修复、风格化、实时MAYA驱动等功能,动画师可以驱动任意美术形式的动画,不仅限于写实风格。除此之外,研发团队介绍到,FACEGOOD将会为第三方开发者提供SDK,方便开发者进行各类应用程序的二次开发,相信很快会有越来越多基于FACEGOOD Fogo技术的应用程序面世。
Fogo界面设计及其简约,操作非常简单,连接上摄像头后录制视频,一键就可以得到高保真的动画数据,数据是标准的权重或顶点数据,因此可以将数据导入其他渲染引擎,对接后续流程,没有多余操作使用方便。Fogo的首次使用需要有一个表情注册过程,一般来讲Fogo内置了23个表情,用户可自己增加更多,中性表情是必须要扫面的。使用3D摄像头扫描完成后,Fogo会自动生成拓扑、自动Blendshape拆分,这个过程是完全自动化的不需要人工参与,也就是把3D人脸扫描到拓扑再到自动Blendshape拆分实现了自动化,Fogo内置了Arkit标准,用户也可以根据自身需求任意定义Blendshape数量。表情注册完成后就可以进行表情捕捉了,一键生成高精度动画,不需要多余人工操作。目前从公开的信息来看,Fogo还处于alpha测试阶段,也就是内测,研发团队称Beta公测将会在下月启动,届时用户可以用iphone手机体验Fogo,让我们拭目以待。
最后,FACEGOOD 团队介绍到,FACEGOOD产品Avatary上线两年以来,团队一直坚持工业级技术的民主化运动,目前在全球近50多个国家地区,上万名创作者使用免费的Avatary制作高精度表情动画。同时,FACEGOOD开源的Audio2Face算法已经服务了近千个AI数字人团队,相信Fogo的出现可以把这个民主化进程继续提速,在各类AI技术的赋能下,成就内容创作最好的时代,赋能全球3D内容创作者。上www.avatary.com了解更多
全文完
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号CG世界 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
-

-
北京
甲方 · 媒体平台
未认证的机构号
recently released
-
2024-02-21
-
2024-01-12











