

—— 青亭网

分享
原创 2023-02-27

Esther | 编辑
我们知道,Meta为了给AR眼镜打造智能助手,专门开发了第一人称视觉模型和数据集。与此同时,该公司也在探索一种将视觉和语音融合的AI感知方案。相比于单纯的语音助手,同时结合视觉和声音数据来感知环境,可进一步增强智能助手的能力,比如模拟人类感知世界的方式,来理解声音在空间的传播方式。
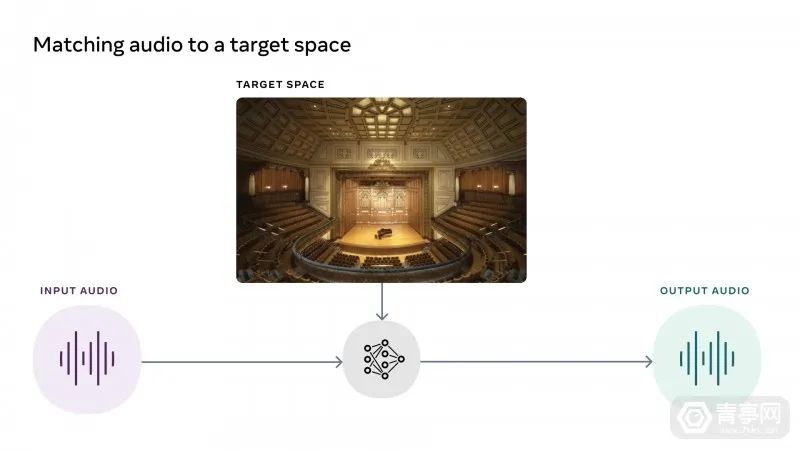
Meta表示:在元宇宙社交、AR观影等多种场景中,声音都扮演了重要的角色。为了满足沉浸式AR/VR场景的需求,Meta决定采用AI来实现高保真的音质,并与沉浸的空间逼真匹配。
为此,Meta AI科研人员和Reality Labs音频专家、德克萨斯大学奥斯汀分校科研人员合作,开发了三个专为AR/VR打造的声音合成AI模型:Visual Acoustic Matching Model(视听匹配模型)、Visually-Informed Dereverberation(基于视觉信息的抗混响模型)、VisualVoice(利用视听提示将对话和背景音区分)。它们特点是可对视频中人类对话和声音进行视听理解,并与3D空间定位进行匹配,实现沉浸的空间音频效果。
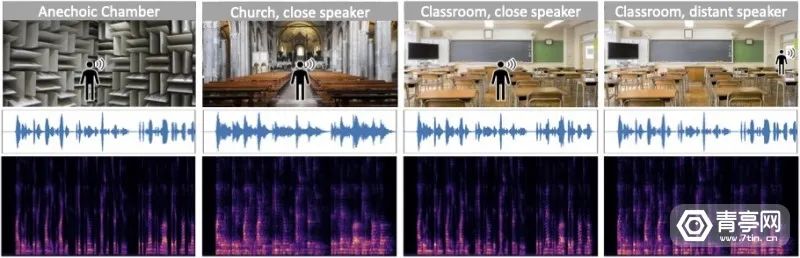
简单来讲,这种AI模型根据外观和声音来理解物理环境。我们知道,声音在不同的物理空间中听起来也会有不同,比如在山洞里你会听到自己说话的回声,而在音乐厅和客厅两种不同规模的空间中,声音传播效果也不相同。这是因为,声音传播路径受到空间结构、材料和表面纹理、距离等因素影响,因此听起来会有所不同。
一,Visual Acoustic Matching Model,视听匹配模型
在这个模型中输入在任何场景录制的音频片段,以及一张目标场景的图像,便可以将录音片段与目标场景融合,音频听起来就像是在目标场景中录制的那样。比如,可以将洞穴中录制的音频与餐厅图像融合,输出的语音听起来就会像在餐厅中录制的那样。
通常在看一段视频时,如果视频的声音和视觉不匹配(不符合传统认知),会造成不自然的体验,人可以轻易发现这种差异,并认为视频声音为后期配音。
利用声音模型,科研人员可模拟声音在房间中传播产生的脉冲,来重现空间的声学效果。但这种方式需要结合空间3D网格,来测定空间的几何结构、材料属性。在大多数情况下,这些信息并不是已知的,因此声学模型难以实现。
科研人员指出,也可以根据在特定空间中捕捉的音频,通过声音在目标空间中产生的混响,来预测声学特性,但缺点是智能获得有限的声音信息,因此模拟效果通常不够好。
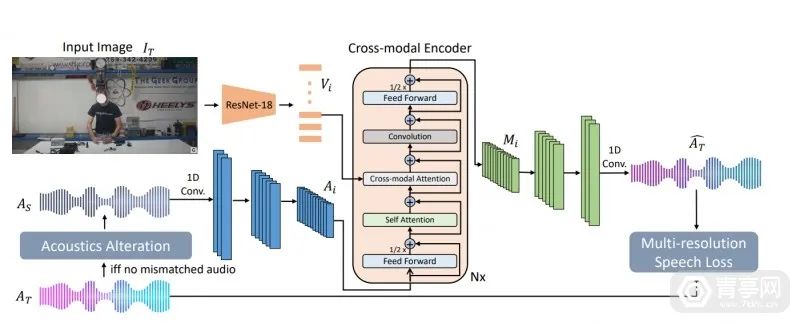
为了解决上述问题,Meta科研人员创建了一个名为AViTAR的自监督视听匹配模型,特点是可通过调整音频,来与目标图像中的空间匹配。AViTAR是一个交叉感知模式转化模型,它可以通过复合模式推理,将输入的视听数据转化成视觉和听觉匹配的高保真数据。此外,AViTAR模型可利用任意网络视频,来进行自我监督训练,练习匹配声音和图像。
Meta为AViTAR创建了两个数据集,其中一个建立在开源AI视听平台SoundSpaces基础上,另一个数据集包含了29万个公开可用的英语对话视频(3到10秒片段)。据悉,SoundSpaces是Meta在2020年开源的AI平台,其特点是建立在虚拟仿真平台AI Habitat之上,可模拟高保真、逼真的声源,并插入到Replica、Matterport3D等开源的真实场景扫描环境中。
这两个数据集主要包含了室内场景中的对话,目的是为了探索未来AI语音和视觉助手在室内的应用场景。细节方案,数据集中的视频拍摄也有要求,麦克风和摄像头在同一个位置,并且远离声源。
为了训练AI模型识别声音和场景不匹配,Meta科研人员还制作了一系列音画不匹配的随机合成视频,并加入噪声。
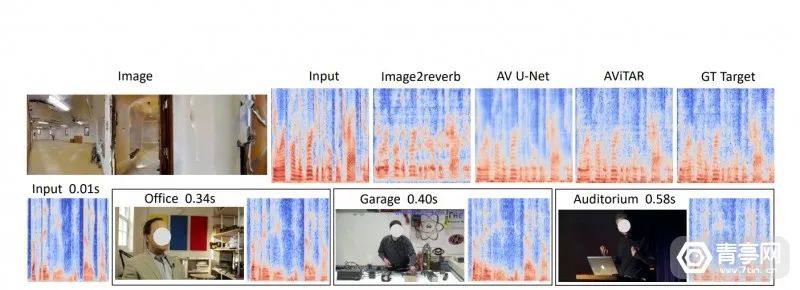
利用这些数据,科研人员验证了视听匹配模型的效果,结果发现该模型可成功将对话与目标图像场景融合,效果比传统的纯音频声学匹配方案更好。
二,Visually-Informed Dereverberation,基于视觉信息的抗混响模型
和上一个模型相反,Visually-Informed Dereverberation(VIDA)专注于消除混响,比如去除声音在洞穴中传播产生的回声。该模型根据视听提示,来优化、筛选音频中的混响。在热闹的火车站场景中,该模型可以提取小提琴演奏的声音,并去除小提琴声与火车站场景交互而产生的回响,好处是可以让小提琴声音听起来更纯粹。
在AR场景重现时,更沉浸、纯粹的声音可以让第一人称观看体验更加保真。
我们知道,回声指的是声源发出声波并到达场景中各表面后反射的现象。将回声、环境音、原声等声音混合并依次进入人耳的过程,则被视为混响。混响、回声通常会降低音频质量,降低人耳感知和分辨声音的能力。比如当你在大课堂给老师录音时,通常也会将同学产生的噪音收录进去。这种混响也会影响语音识别的准确性。

去除混响后,便可以增强声音的重点,帮助自然语言模型更好的识别对话,并生成更准确的字幕。
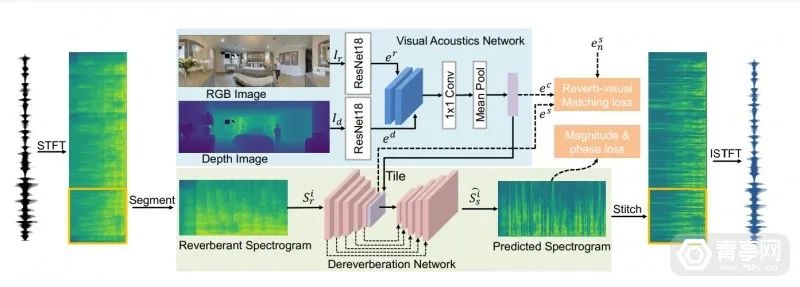
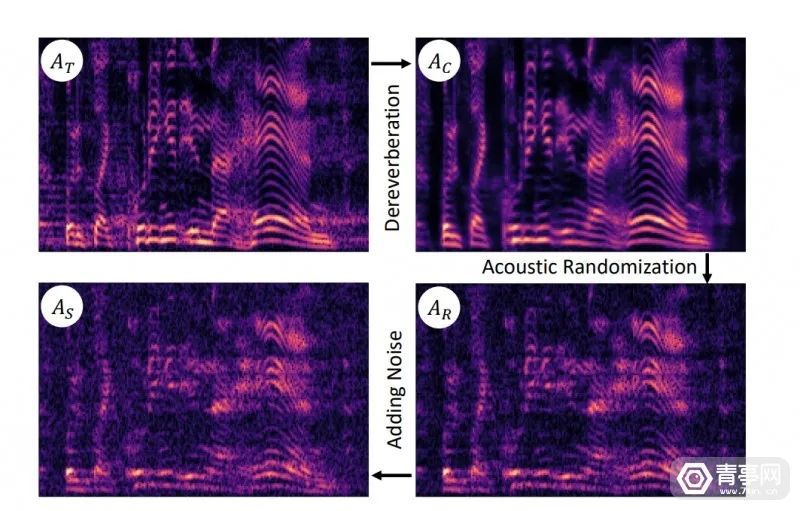
此前,人们通常直接处理音频来消除混响,但这并没有考虑到环境的完整声学特性。为了提升消混响的效果、更自然增强音频,Meta科研人员提出了搭配视觉分析的方案:VIDA,也就是说利用视觉数据来辅助混响消除。

VIDA模型基于视听数据来训练,可通过识别空间结构、材质和扬声器等线索,来消除混响。
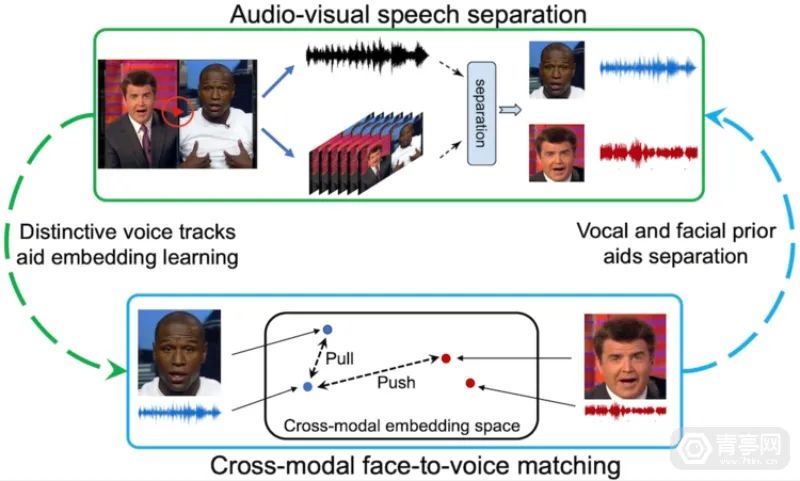
三,VisualVoice,利用视听提示将对话和背景音区分
VisualVoice模型利用视听提示,来区分对话和背景音,其好处是可以帮助人和AI更好的听清对话,从而提升多人VR社交的沟通效率、实时字幕效果等等。
Meta设想了一个未来场景,即人们通过AR眼镜以第一人称视角,重温沉浸的全息回忆,并获得保真的视觉和声音体验。或是在VR游戏中,空间音频可进一步增强沉浸感。
这个模型同时通过视听数据来分析对话,Meta认为,这项技术是改善人机感知的重要因素。
Meta指出,在复杂环境中,人类可以比AI更好的理解对话,这是因为人不止会用耳朵听,也会用眼睛辅助。举个例子,当你周围有人说话时,你可以用耳朵听到他的声音和声音来源,同时也可以用眼睛来定位这个说话人的具体位置。
因此,Meta AI决定开发一个同时模拟视觉和听觉感知的多模式对话模型,帮助AI更好的分析视觉和语音之间的细微关联。即使使用未标记的视频,也能训练VisualVoice模型提取对话中的视听信息。
未来应用场景
Meta表示:利用这些智能的AI语音分割模型,未来虚拟助手可以随时随地听到你的指令,不管是在音乐会、热闹的聚会还是其他环境音量大的场景。
接下来,若想要为AR/VR构建更加沉浸的体验,将需要这种多模式的AI模型,才能模拟人类感知的方式,通过音频、视频、文本等信号来更好的理解周围环境。
为了继续优化AViTAR、VITA等模型,Meta未来将使用视频来训练AI捕捉空间声学特性。
( END)
* 文章为作者独立观点,不代表数艺网立场转载须知

北京
甲方 · 媒体平台
未认证的机构号
2023-07-13
2023-07-12
广告 欺诈 淫秽 色情 侵权 骚扰、辱骂、歧视 敏感 违法 犯罪 反动、政治 其它
数艺网是一个信息获取、分享及传播的平台,我们尊重和鼓励数艺网用户创作的内容,认识到保护知识产权对数艺网生存与发展的重要性,承诺将保护知识产权作为数艺网运营的基本原则之一。
本条款原则如下:
1. 用户在数艺网上发表的全部原创内容(包括但不仅限于文章、案例/项目和评论),著作权均归用户本人所有。用户可授权第三方以任何方式使用,不需要得到数艺网的同意。
2. 数艺网上可由多人参与编辑的内容,包括但不限于案例/作品的认领、企业/机构的认领,所有参与编辑者均同意,相关知识产权归数艺网所有。
3. 数艺网提供的网络服务中包含的标识、版面设计、排版方式、文本、图片、图形等均受著作权、商标权及其它法律保护,未经相关权利人(含数艺网及其他原始权利人)同意,上述内容均不得在任何平台被直接或间接发布、使用、出于发布或使用目的的改写或再发行,或被用于其他任何商业目的。
4. 为了促进知识的分享和传播,用户将其在数艺网上发表的全部内容,授予数艺网免费的、不可撤销的、非独家使用许可,数艺网有权将该内容用于数艺网各种形态的产品和服务上,包括但不限于网站以及发表的应用或其他互联网产品。
5. 第三方若出于非商业目的,将用户在数艺网上发表的内容转载在数艺网之外的地方,应当在作品的正文开头的显著位置注明原作者姓名(或原作者在数艺网上使用的帐号名称),给出原始链接,注明「发表于数艺网」,并不得对作品进行修改演绎。若需要对作品进行修改,或用于商业目的,第三方应当联系用户获得单独授权,按照用户规定的方式使用该内容。
6. 数艺网为用户提供「保留所有权利,禁止转载」的选项。除非获得原作者的单独授权,任何第三方不得转载标注了「禁止转载」的内容,否则均视为侵权。
7. 在数艺网上传或发表的内容,用户应保证其为著作权人或已取得合法授权,并且该内容不会侵犯任何第三方的合法权益。如果第三方提出关于著作权的异议,数艺网有权根据实际情况删除相关的内容,且有权追究用户的法律责任。给数艺网或任何第三方造成损失的,用户应负责全额赔偿。
8. 如果任何第三方侵犯了数艺网用户相关的权利,用户同意授权数艺网或其指定的代理人代表数艺网自身或用户对该第三方提出警告、投诉、发起行政执法、诉讼、进行上诉,或谈判和解,并且用户同意在数艺网认为必要的情况下参与共同维权。
9. 数艺网有权但无义务对用户发布的内容进行审核,有权根据相关证据结合《侵权责任法》、《信息网络传播权保护条例》等法律法规及数艺网社区管理规定对侵权信息进行处理。
侵权举报
1.处理原则
数艺网作为新媒体艺术领域的分享交流平台,高度重视自由表达和个人、机构正当权利的平衡。依照法律规定删除违法信息是数艺网社区的法定义务,数艺网社区亦未与任何中介机构合作开展此项业务。
2.受理范围
受理数艺网社区内侵犯机构或个人合法权益的侵权举报,包括但不限于涉及个人隐私、造谣与诽谤、商业侵权。
a.涉及个人隐私:发布内容中直接涉及身份信息,如个人姓名、家庭住址、身份证号码、工作单位、私人电话等详细个人隐私;
b.造谣、诽谤:发布内容中指名道姓(包括自然人和机构)的直接谩骂、侮辱、虚构中伤、恶意诽谤等;
c.商业侵权:泄露机构商业机密及其他根据保密协议不能公开讨论的内容。
3.举报条件
用户在数艺网发表的内容仅表明其个人的立场和观点,并不代表数艺网的立场或观点。如果个人或机构发现数艺网上存在侵犯自身合法权益的内容,可以先尝试与作者取得联系,通过沟通协商解决问题。如您无法联系到作者,或无法通过与作者沟通解决问题,您可通过点击内容下方的举报按钮来向数艺网平台进行投诉。为了保证问题能够及时有效地处理,请务必提交真实有效、完整清晰的材料,否则投诉将无法受理。您需要向数艺网提供的投诉材料包括:
a. 权利人对涉嫌侵权内容拥有商标权、著作权和/或其他依法可以行使权利的权属证明,权属证明通常是营业执照或组织机构代码证;
b. 完整填写的通知书;附供下载的:侵权投诉通知书;
c. 举报人的身份证明,身份证明可以是身份证或护照;
d. 如果举报人非权利人,请举报人提供代表权利人进行举报的书面授权证明。
e. 为确保投诉材料的真实性,在侵权举报中,您还需要签署以下法律声明:
(1) 我本人为所举报内容的合法权利人;
(2) 我举报的发布在数艺网社区中的内容侵犯了本人相应的合法权益;
(3) 如果本侵权举报内容不完全属实,本人将承担由此产生的一切法律责任,并承担和赔偿数艺网因根据投诉人的通知书对相关帐号的处理而造成的任何损失,包括但不限于知乎因向被投诉方赔偿而产生的损失及数艺网名誉、商誉损害等。
4.处理流程
出于网络平台的监督属性,并非所有申请都必须受理。数艺网自收到举报的七个工作日内处理完毕并给出回复。处理期间,不提供任何电话、邮件及其他方式的查询服务。 出现数艺网已经删除或处理的内容,但是百度、谷歌等搜索引擎依然可以搜索到的现象,是因为百度、谷歌等搜索引擎自带缓存,此类问题数艺网无权也无法处理,因此相关申请不予受理。您可以自行联系搜索引擎服务商进行处理。 此为数艺网社区唯一的官方侵权投诉渠道,暂不提供其他方式处理此业务。 用户在数艺网中的商业行为引发的法律纠纷,由交易双方自行处理,与数艺网无关。
免责申明
1.数艺网不能对用户发表的回答或评论的正确性进行保证。
2.用户在数艺网发表的内容仅表明其个人的立场和观点,并不代表数艺网的立场或观点。作为内容的发表者,需自行对所发表内容负责,因所发表内容引发的一切纠纷,由该内容的发表者承担全部法律及连带责任。数艺网不承担任何法律及连带责任。
3.数艺网不保证网络服务一定能满足用户的要求,也不保证网络服务不会中断,对网络服务的及时性、安全性、准确性也都不作保证。
4.对于因不可抗力或数艺网不能控制的原因造成的网络服务中断或其它缺陷,数艺网不承担任何责任,但将尽力减少因此而给用户造成的损失和影响。
协议修改
1.根据互联网的发展和有关法律、法规及规范性文件的变化,或者因业务发展需要,数艺网有权对本协议的条款作出修改或变更,一旦本协议的内容发生变动,数艺网将会直接在数艺网网站上公布修改之后的协议内容,该公布行为视为数艺网已经通知用户修改内容。数艺网也可采用电子邮件或私信的传送方式,提示用户协议条款的修改、服务变更、或其它重要事项。
2.如果不同意数艺网对本协议相关条款所做的修改,用户有权并应当停止使用数艺网。如果用户继续使用数艺网,则视为用户接受数艺网对本协议相关条款所做的修改。
阅读并同意此认领协议方可认领案例
*认领案例的操作记录无法自行删除,请务必确保您参与该案例身份的真实性











