
- 0
- 0
- 0
分享
- 被Google收购的初创“AI虚拟形象”公司Alter:3D虚拟化身是未来在线社交的重要趋势,仍有技术和工具化机会|「文娱科技」
-
2023-01-03

文娱科技,
Google收购Alter,
后者专注AI虚拟化身技术研发
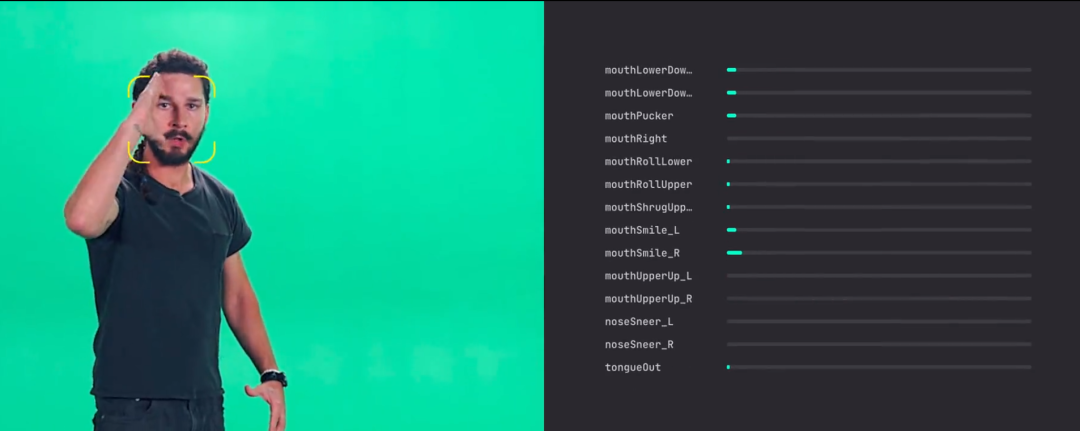
 mop4face SDK产品
mop4face SDK产品 tiktok的avatar产品
tiktok的avatar产品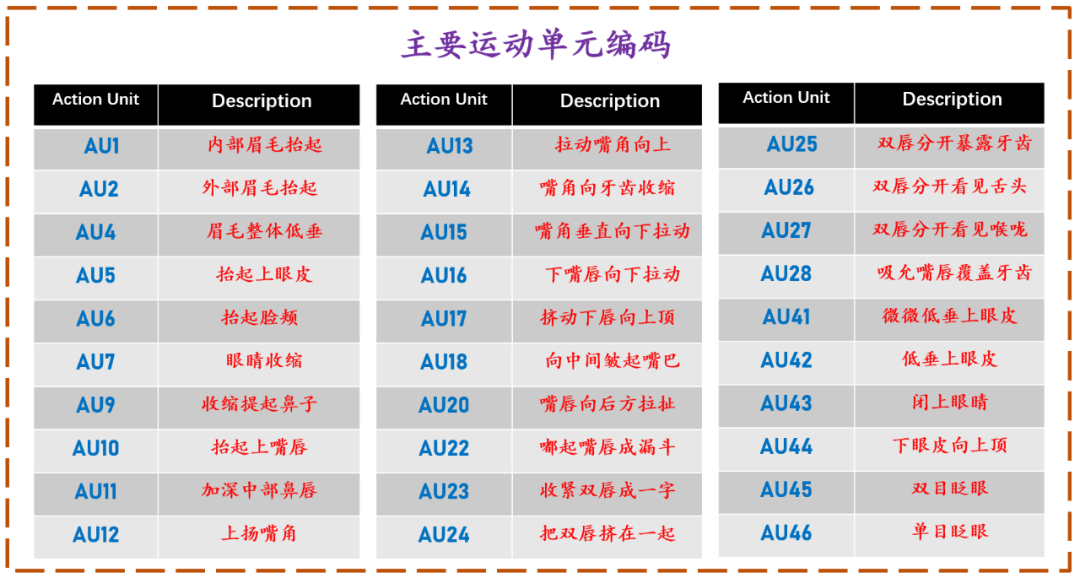 FACS对人脸主要运动单元(AU)的编码
FACS对人脸主要运动单元(AU)的编码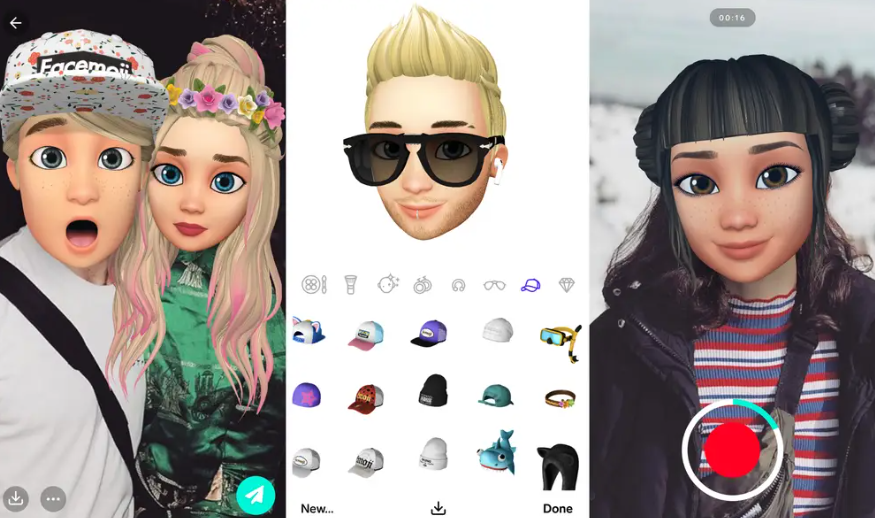 Facemoji app
Facemoji app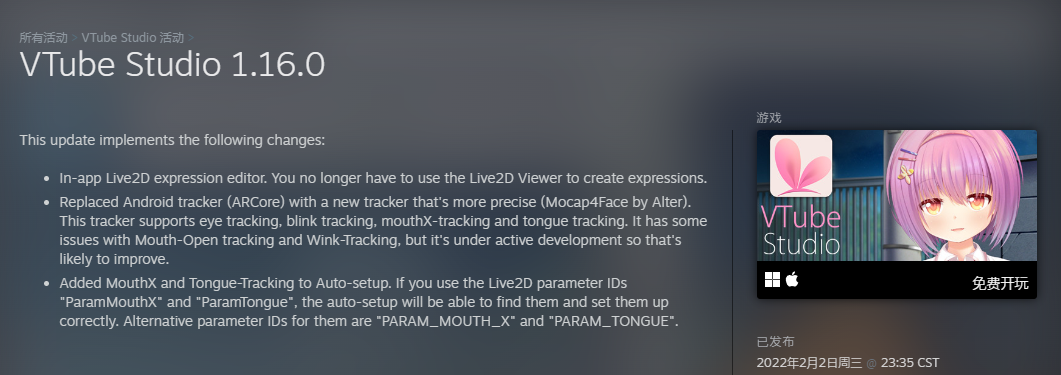 VTube Studio 1.16.0的版本更新说明
VTube Studio 1.16.0的版本更新说明
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号东西文娱 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
22479
举报
0
-

-
成都
分包方 · 系统集成/多媒体总包
未认证的机构号
recently released
-
2024-08-19
-
2024-02-24











