- 0
- 0
- 0
分享
- Meta布局视频领域的AIGC工具:推出Make-A-Video,用AI驱动文本、图片生成短视频 |「AIGC系列」
-
2022-11-16


除了语音、文本和绘画,AIGC相关技术和工具也在渗透到视频创作领域。平台与技术公司陆续推出工具产品,辅助内容生产者进行视频创作。
日前Meta 旗下人工智能实验室 Meta AI,发布了从文本生成视频的AI系统“Make-A-Video”,即根据输入的自然语言文本生成一段5秒钟左右的短视频。并且在此基础上,拓展到从图像生成视频,和从视频生成视频。
这与“文本生成图像”(Text to Image)的AI作画有异曲同工之处,但相比AI作画又需要AI对物体运动逻辑有更深层的理解。
Meta CEO 扎克伯格在自己的Facebook中表示,“AI生成视频要比图像困难得多,这是非常惊人的进步。系统除了要正确生成每个像素外,还需预测像素将如何随时间变化。Make-A-Video 能够理解物理世界中的运动,并将其应用于传统的文本生成图像AI技术中。”
Make-A-Video 并非AIGC应用在视频赛道的个例,国内外已经有清华、谷歌等研究机构和科技公司公布相关技术并开发相应工具产品等。
Make-A-Video:
文本生成视频,让创作者更自由塑造内容
Meta AI 公布的Make-A-Video,是一个用AI技术从文本生成视频的工具,能仅凭几个单词或者一行文字,生成一段分辨率768 * 768的5秒视频。
例如,输入“一只泰迪熊在画肖像”,Make-A-Video 便能生成一个泰迪熊般的角色,在画板上绘画的画面,并表现出细腻的手部动作。同时,Make-A-Video 还允许输出超现实、写实、风格化等不同的视频类型。

并且在此基础上,Make-A-Video 进一步拓宽了视频生成的输入窗口,支持从单图片、两张相似图片、一段视频素材输出一段视频。
上传一张静止的航海油画,Make-A-Video 会输出一段正在海浪中前行的帆船视频。还可以为两张相似的陨石图像,补全一段陨石运行变化的视频。甚至是根据一段玩偶跳舞的视频,生成多个类似的视频。

Make-A-Video 其实是建立在 Meta 已有的AI图像生成技术之上。今年7月,Meta 公布了自研的文本生成图像 AI 模型 Make-A-Scene。
Make-A-Scene 与现在市场熟知的DALL-E类似,用数百万个示例图片训练AI模型学习图像和文字间的关系,并最终能从输入的文本生成图像。
文本生成视频是在图像生成的基础上更进一步,表面上看是多张 AI 图像堆叠成一段视频。但背后要求 AI 模型能够理解每个像素点正确的运动方式,并且每帧图像的分辨率不能太低,如此才能形成连贯的视频画面。
为此,Meta AI 将 Make-A-Video 分割成三个组成部分,并分开训练:
1、基础的文字生成图像 AI模型。
2、构建了新的AI训练模块,学习视频中图像在时间维度上的动态变化。
3、加入超分辨率模型和插帧模型,提高视频的分辨率和帧率,提高视频画质。
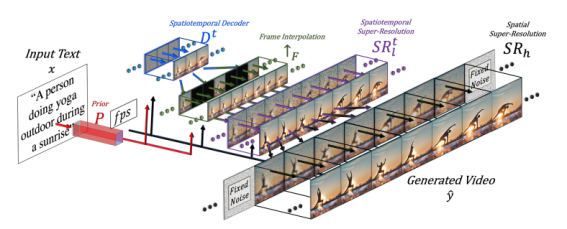
Make-A-Video 工作原理示意图
在 Make-A-Video 的官方白皮书中,提到这样的训练方法有三大优点:(1)加速了视频生成模型的训练时间;(2)不需要大量带有文本描述的视频数据集;(3)继承了图像生成模型的多样性。
客观而言, Make-A-Video 生成的视频依然有很多瑕疵。Meta AI 也表示目前最主要的限制在于无法体现太多的细节,仅局限于简单动作和场景,不能生成多个场景、多个事件的长视频。这也是下一阶段,Make-A-Video 需要攻克的难题。
当下,Make-A-Video 也并未正式向大众开放,但已经受到一些创作者的关注。Meta 官方在推特上表示,“像 Make-A-Video 这类AIGC工具正在通过让人们更自由地塑造内容,推动创作者的表达。”
AIGC在视频领域的用例也在丰富,相关工具尚在起步阶段
Make-A-Video 并不是AIGC在视频领域中唯一的玩家。
在今年5月,清华大学曾联合智源研究院发布CogVideo ,这是第一个开源的大规模的文字生成视频 AI 模型。它能够生成一段480*480分辨率,由32张图像组成4秒视频。

 CogVideo生成的视频
CogVideo生成的视频
尽管 CogVideo 的视频画质不尽如人意,但可以算是这一领域的开拓者。
而就在 Make-A-Video 发布后的一周,谷歌发布了两个文字生成视频 AI 系统,Imagen Video和Phenaki。同样,目前Imagen Video 和 Phenaki 也尚未对大众开放。
这两个AI系统同样是以谷歌之前发布的文字生成图像 AI 系统 Imagen 为基础,但两者侧重不同。
Imagen Video 侧重于输出较高画质的视频图像,而 Phenaki 则擅长生产长视频。
Imagen Video 先生成24*48低分辨率低帧数的视频,之后通过 AI 超分辨率模型提升视频画质,最终输出分辨率为1289*768,每秒包含24帧图像的短视频,时长也大约在5秒左右。
视频画质较高,但缺点也同样明显,一旦涉及动物肢体运动时,Imagen Video 所生成的视频都会发生怪异扭曲的形变。当 Imagen Video 生成“一只英短跳到沙发上”的视频时,甚至无法清楚分辨猫的脸。

但令人惊喜的是,在生产一些艺术字相关的视频时,Imagen Video 的效果十分不错,例如在沙滩背景上绘制出“IMAGEN VIDEO”字样的视频、从童话书中长出“IMAGEN VIDEO”字母形状的嫩芽等。

而 Phenaki 虽然视频画质较差,却能生成超2分钟时长的视频,并且涉及多个场景、不同主题间的变换。正如 Phenaki 官网所展示的,这段视频使用了一段200个单词构成的提示词,生成了一段关于未来科幻世界的视频。

Phenaki生成的2分钟视频
总的来说,当下的视频领域以AIGC为主体进行创作的技术,距离落地实际应用还比较长。不过Phenaki 研究人员在论文中提到的,他们希望未来的AI视频生成模型“能够成为艺术家和非艺术家广泛使用的工具之一,为表达创造力提供新的令人兴奋的方式。”
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号共同虚拟 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
-

-
上海
甲方 · 垂直媒体
未认证的机构号
最近发布
-
2024-01-11
-
2023-12-12











