
- 0
- 0
- 0
分享
- 几张手机照片就能打造3D写实角色建模?AI建模软件迎来井喷式更新!
-
2022-10-14
只需几张手机照片就能打造
3D写实角色建模?
这是扎克伯格刚刚发布的1款演示
快来康康
👇👇👇
视频中Meta展示了最新全身编码器化身
Codec Avatars 2.0
用户只需使用手机简单扫描
即可轻松创建更加细节、高质量逼真的虚拟化身
今日凌晨1点
一年一度的Connect大会正式拉开序幕
扎克伯格除了展示新产品
Meta Quest Pro之外

还在之后的技术演示中
展示了Codec Avatars 2.0的最新进展
不仅化身的面部表情更加真实、生动
便于社交时通过微表情和语气理解彼此
甚至还能控制光照



而利用正在开发的Instant Codec Avatars
只需用智能手机从不同角度扫描人脸
再进行各种表情的扫描
几个小时就能生成
这样精细的虚拟化身
据悉,未来这个时间还会进一步缩短



以前可能需要一个VR头显才能实现的景象
Meta现在说
不用带这东西了,有个iPhone就行了!
只要一台带正面深度传感器的智能手机
直接扫一扫你,就能生成逼真的虚拟人头像
那么这到底是个什么事物
他是怎么产生的呢
让我们一起来看看官方是怎么设计的
# Codec Avatars 的由来 #
官方于 2019 年 3 月首次展示了
“Codec Avatars”的工作
第一代数字人是利用多重神经网络
用 132 个摄像头的专用捕获装置生成的

一旦生成
在VR头显设备上的5个摄像头
每只眼部提供两个内部视角
脸部以下提供三个外部视角
↓就像下面这样↓

从那时起,研究人员一直致力于更新功能
比如只需麦克风和眼球追踪技术
就可以获得更逼真的形象
最终在2020年8月
进化为Codec Avatar 2.0版
这次更新的最大进步在于
摄像头不再需要扫描跟踪人脸
而是只要跟踪眼球的运动就行了
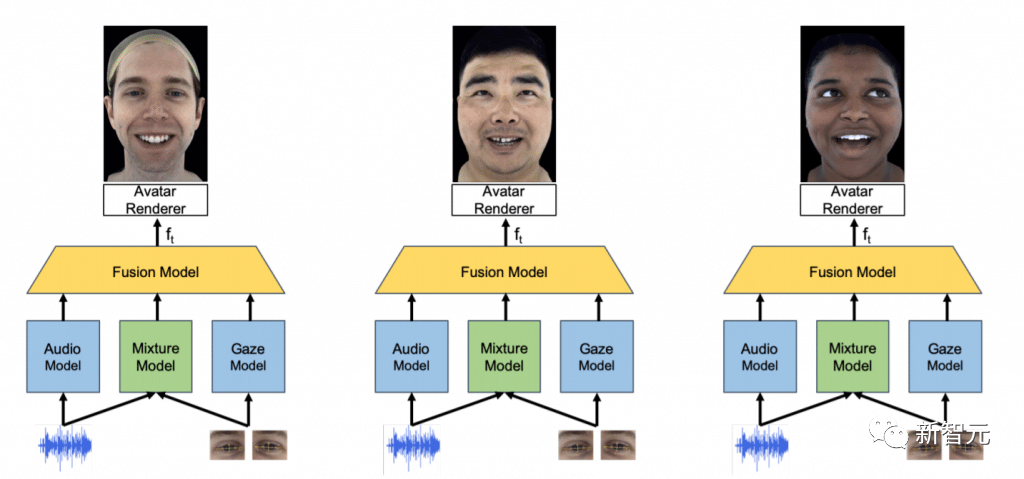
新的神经网络将
VR头显的眼动追踪数据与麦克风的音频推送相融合
推断佩戴者可能的面部表情
将声音模型和眼动模型数据
反馈至混合模型
再经过融合模型计算处理
由渲染器输出Avatar形象

今年5月,团队更进一步宣布
2.0版本彻底达成了“完全逼真”的效果
让我们根据官方示例进行对比
a为真人照片,e为最终渲染生成的虚拟人
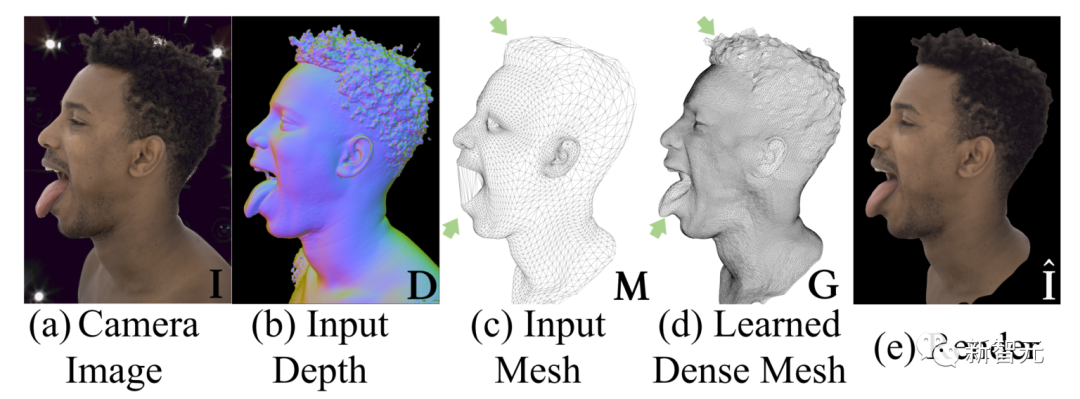
上面这是实验中的比对结果
实际上应用场景下
目前Meta虚拟人的形象是这样的

有网友对此表示
此技术的不断发展有可能冲击到现有行业
AI技术的发展在近1个月
便开始逐步深入到建模相关行业中
除了本次公布的技术外
让我们看看还有哪些热度较高的新应用
# 一块GPU每秒生成20个模型 #
近日,英伟达发布了最新的GET3D模型
能快速生成虚拟世界的对象
而且只需要一块GPU每秒就能产出大约20个模型
来自NVIDIA的AI研究人员介绍了GET3D
这是一种新的生成模型
GET3D通过一系列2D图像训练后
可生成具有高保真纹理和复杂几何细节的 3D 形状

GET3D之所以得名
是因为它能够生成显式纹理3D网格
它创建的形状是三角形网格的形式
就像纸模型一样,上面覆盖着纹理材质
而且这个模型可以生成多类型
且高质量的模型
汽车的车轮、灯和车窗
摩托车的后视镜、车轮胎上的纹理
都能办到


研究团队仅用2天时间
就使用A100 GPU
在大约100万张图像上训练了模型

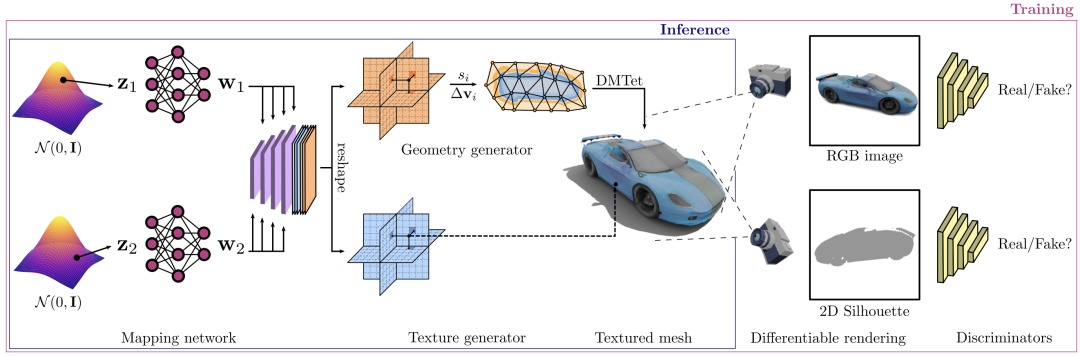
随后研究人员又进行了广泛的实验来评估该模型
如下图所示,在每一行中展示了
由相同的几何隐藏代码生成的形状
同时更改了纹理代码
在每一列中展示了
由相同的纹理隐藏代码生成的形状
同时更改了几何代码

研究人员在每一行中相同的纹理隐藏代码生成的形状
从左到右插入几何隐藏代码
并由相同的几何隐藏代码生成的形状
同时从上到下插入纹理代码
结果显示,每个插值对生成模型都是有意义的

而且在每一行中
可以添加一个小噪声来局部扰乱隐藏代码
通过这种方式
GET3D能够在局部生成
外观相似但略有差异的形状

不仅如此,结合英伟达的另一个AI工具
StyleGAN-NADA
开发人员可以使用文本提示
为图像添加特定的风格



英伟达人工智能研究副总裁Sanja Fidler表示
”GET3D让我们离人工智能驱动的
3D内容创作大众化又近了一步“
“它即时生成带纹理3D形状的能力
可能会改变开发人员的游戏规则
帮助他们用各种有趣的对象快速填充虚拟世界”
# 文本直接生成3D模型 #
今年9月底,Google研究员另辟蹊径
提出一个新模型DreamFusion
先使用一个预训练2D扩散模型
基于文本提示生成一张二维图像
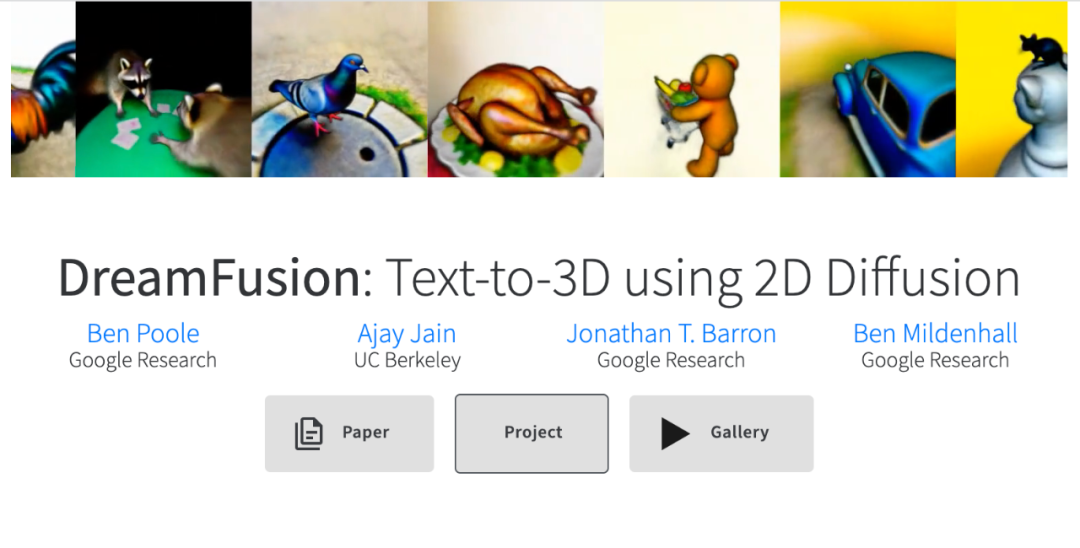
然后引入一个基于概率密度蒸馏的损失函数
通过梯度下降法优化一个
随机初始化的神经辐射场NeRF模型
训练后的模型可以在
任意角度、任意光照条件、任意三维环境中
基于给定的文本提示生成模型
整个过程既不需要3D训练数据
也无需修改图像扩散模型
完全依赖预训练扩散模型作为先验
目前 Dreamfusion 还未完全做到工具开源
不过项目网站上也提供了生成的词条组合
比如说下面这样
微博评论区下的网友也感到十分震惊
感叹AI发展速度快的同时也对
是否会引起部分行业冲击感到担忧


大家觉得扎克伯格此次的演示效果如何?
3D建模行业也会受到AI的影响吗?
欢迎在评论区留言分享
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号GGAC ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
3D写实角色建模 AI建模软件 扎克伯格 前沿科技 虚拟化身
-

-
上海
甲方 · 垂直媒体
未认证的机构号
recently released
-
2024-12-23
-
2022-10-14






