“ 感知技术 · 感触CG · 感受艺术 · 感悟心灵 ”
中国很有影响力影视特效CG动画领域自媒体
编辑:木木
驱动一个数字人往往被拆分为追踪(Tracking)与重定向(Retargeting)两个环节。追踪由专业的面部捕捉设备及其辅助算法完成,负责记录演员的面部动作信息,重定向则是将捕捉到的动作信息迁移到新的角色。在传统的流程中,这两个环节往往是分离的两套体系,难以融合,且两个环节都有大量不可控的人工发挥成分,互相影响。近些年,随着计算机图形学技术的发展与渲染硬件性能的不断提升,人们已经能够通过复杂的物理模拟,借助离线渲染技术得到无限真实的静态人像。但即便如此,在动态数字人角色的呈现上,我们距离跨越恐怖谷效应还有很长的路要走。虽然人们已经能够在诸如《阿凡达》《双子杀手》等电影中带来与真实演员别无二致的数字替身,但其背后是艺术家手工绑定与手工制作关键帧动画带来的大量资金投入。针对上述问题,上海科技大学科研团队联合数字人底层技术公司影眸科技提出了这样的思路:将首创的4D PBR扫描技术与神经网络表达相结合,训练多VAE的网络结构,跳过了传统的绑定与动态贴图制作流程。这意味着,无需面捕头盔、无需人工绑定,只需要一段4D序列作为训练,RGB视频就可以实现精细到微表情级别的实时面部捕捉。这项工作已经被SIGGRAPH Asia 2022 接收为Technical Paper - Journal Track并受邀作报告分享。据研究人员介绍,这项技术不仅能够生产出与现有渲染引擎兼容的面部几何模型和多层材质贴图,还能让任何人凭借手机进行轻量级面部捕捉,实时驱动高质量的面部资产,该技术已经投入国内影视特效与游戏行业使用。

使用神经网络构建面部资产
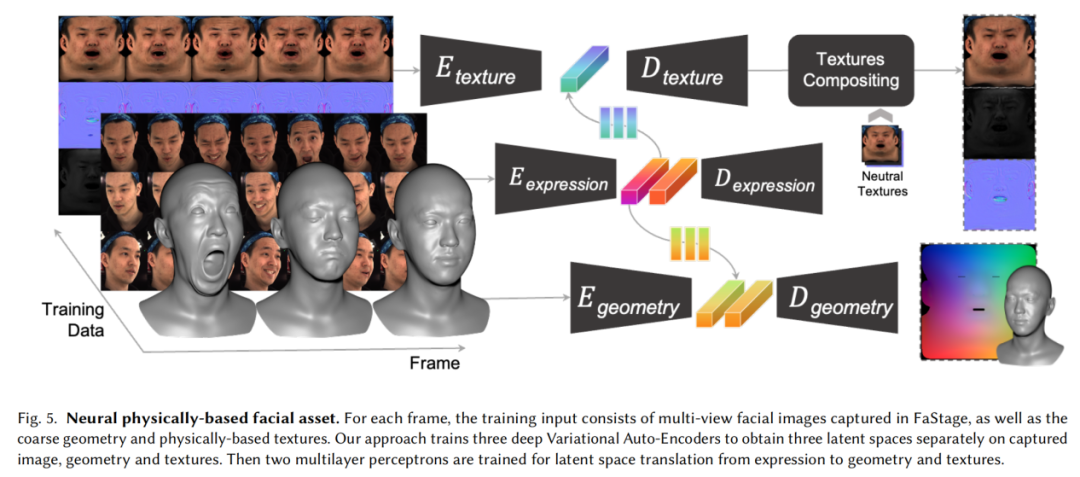
上科大联合影眸科技研发团队将预先捕捉好的高质量面部资产与轻量级的输入设备相结合,填补了两种不同解决方案中间的空白。他们带来了全新的思路——基于高质量的4D面部资产数据,实现对面部动态几何和材质贴图的隐式表达,从而得到更真实自然的面部驱动效果。

首先是训练数据采集。研究人员使用了穹顶光场设备采集演员的面部资产。模特按照研究人员的设计进行面部表演,由穹顶光场以24fps采集了模特表演的动态面部几何和材质贴图(漫反射、高光、法线贴图)。

接着,研究人员实现了神经网络重定向(Neural Retargeting)。他们将该任务分解为:使用神经网络解析输入视频的表情信息(捕捉),并将其迁移到面部资产上(重定向)。具体实现时,任务被拆解为了三个分支——表情、几何、材质贴图。研究人员针对每个部分分别训练了一个VAE以提取相关信息。表情网络负责捕捉,后两个则负责重定向。
在训练表情网络时,他们使用了全新的三元训练法来监督训练。训练时,将某张图片与其相同视角不同表情的照片,以及不同视角相同表情的照片分在一组,使得网络能够学会从输入视频帧中解耦表情与视角信息,从而在视角变换的情况下也能稳定地以隐向量形式提取出表情信息。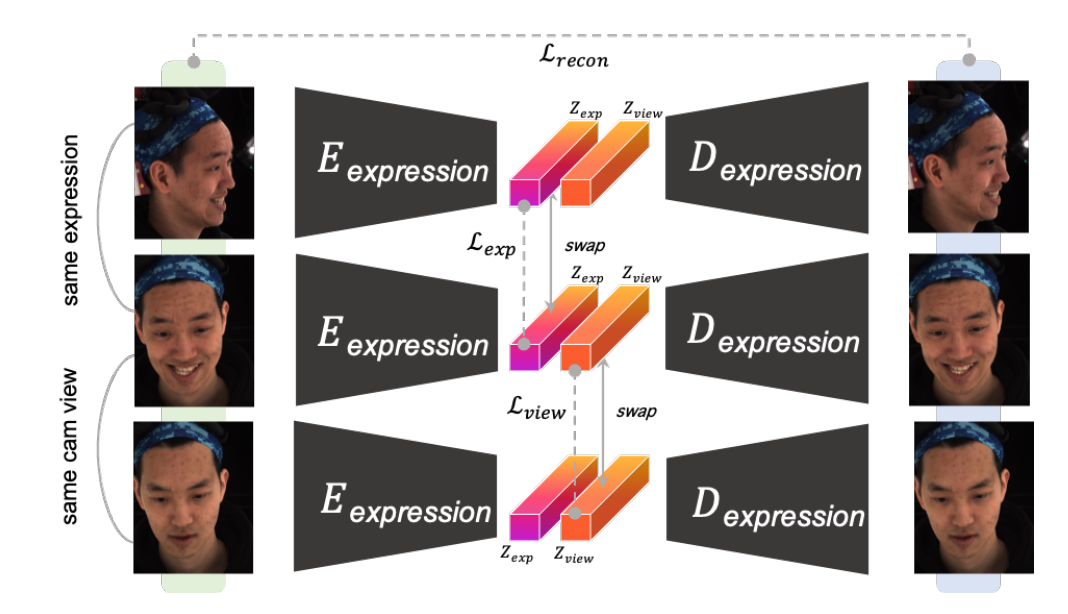
面部几何网络也用类似的方法训练。训练时,网络需要预测当前表情面部几何与无表情面部几何的差值。对于材质贴图训练,VAE网络只需要能提取输入贴图中的表情隐向量,并根据其恢复出输入材质贴图即可。值得注意的是,这里使用了皱纹图的方式来表达材质贴图变化,具体来说,是网络输出当前帧材质贴图与无表情材质贴图的差值。将这张皱纹图线性放大到4K分辨率下并与无表情材质贴图叠加,就能得到高分辨率的面部材质贴图。这样既可以保留高分辨率贴图下的毛孔级面部细节,又可以精准表达皱纹、阴影等在动态表情中出现的面部特征。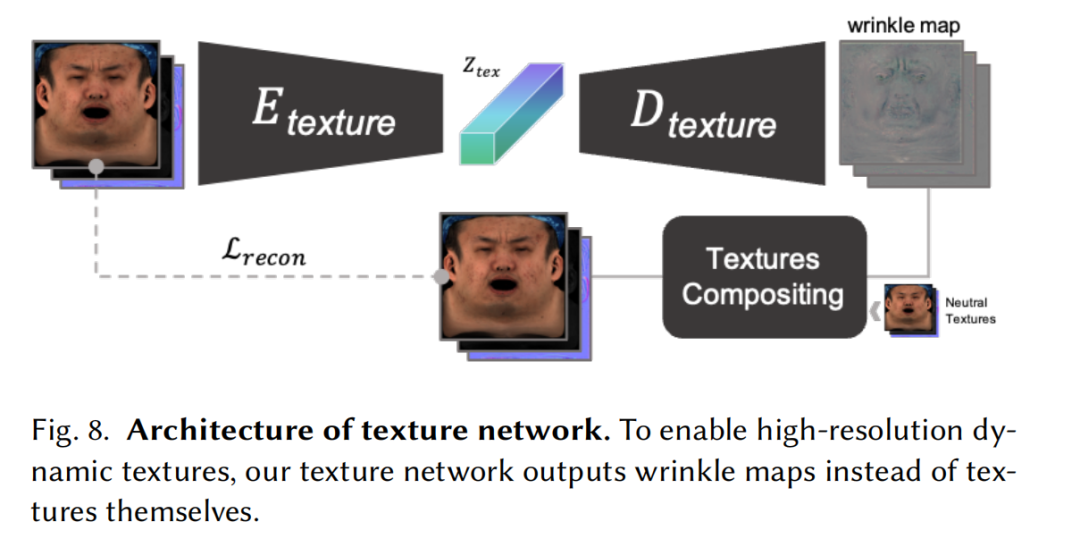
此外,为了让三个VAE所提取的表情隐向量处于一致的隐空间,研究人员还训练了两个MLP来实现不同VAE之间表情信息的转化。几何和材质贴图网络的训练,将训练集中的高质量面部资产编码于神经网络所构建的隐空间中。只需要一个表情隐向量,就可以得到对应的高质量几何、纹理资产。最后使用时,对于某一视频输入帧,由表情VAE的编码器提取表情信息,由两个MLP分别将其转化为几何、材质贴图VAE的表情隐向量,再由两个VAE的解码器得到对应的几何和材质贴图。资产的比较与使用
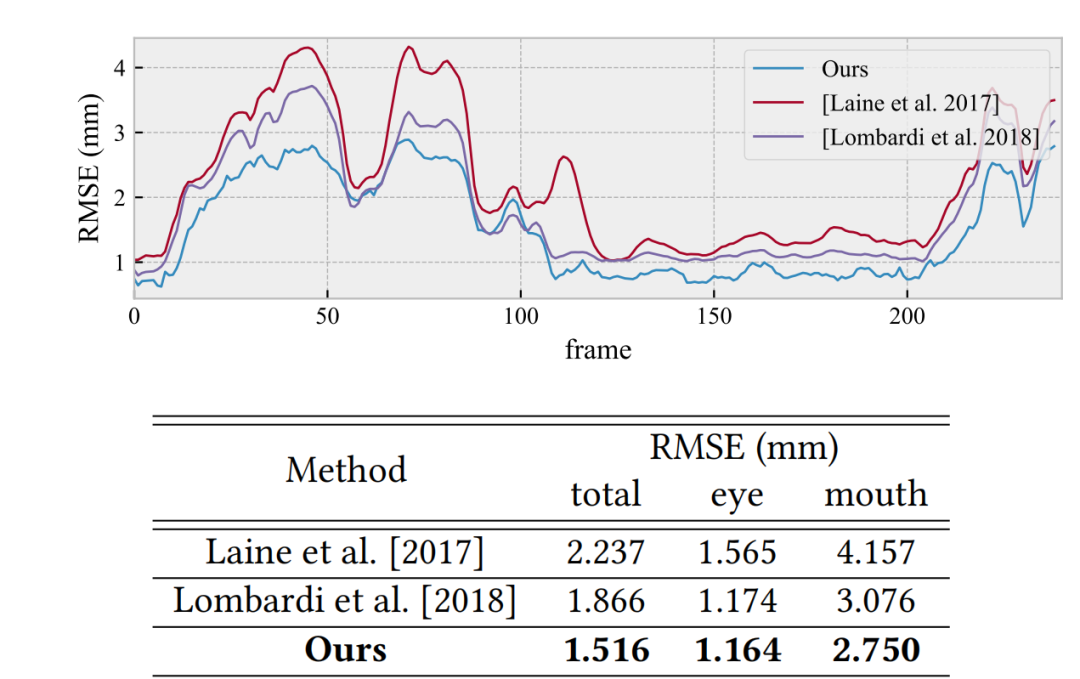
与之前的工作相比,该方法在几何精度上有了一定提高。首先,模特本人的视频可以被用来驱动生成的资产。即便是面对训练集中没有做出过的表情,网络也能立刻给出高真实度的几何和材质贴图预测。这免去了后续专门为演员安装面部捕捉设备的工作。其次,该方法也支持自由环境跨对象重定向(in-the-wild cross-identity retargeting),即,非模特本人的面部表演视频,也可以驱动面部资产。只需要一小部分视频帧混入网络训练中进行优化,并使用指示变量告知网络输入图片是手机拍摄输入或是设备采集结果,网络就可以提取输入视频中的人脸表情信息,并预测原模特做出该表情时,对应的面部几何和材质贴图。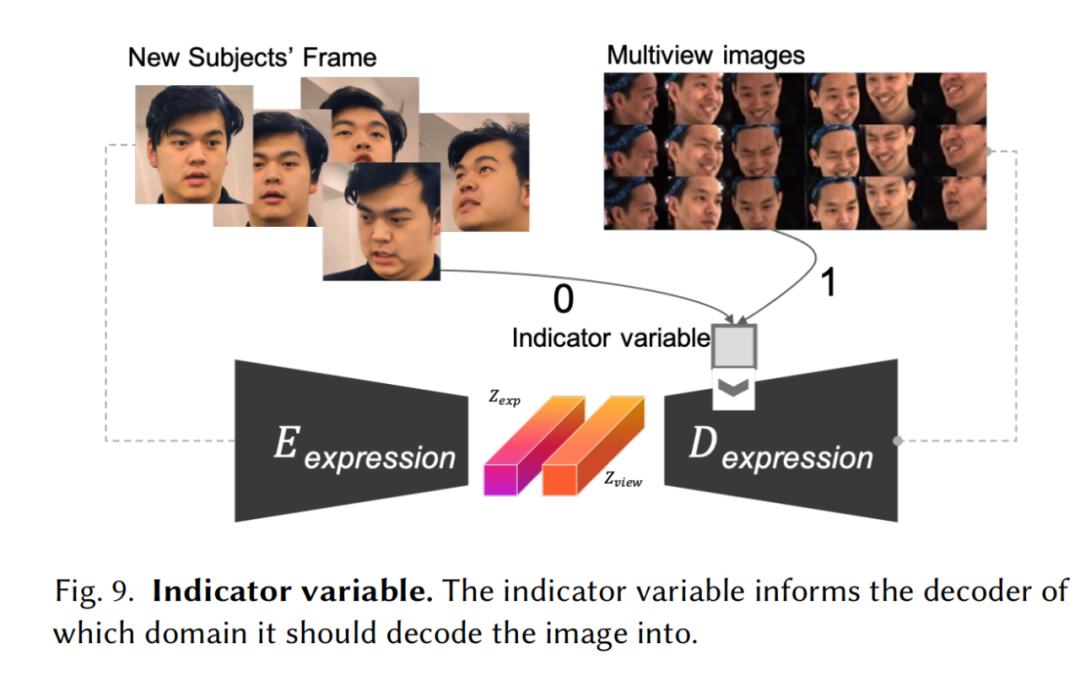
此外,视频输入也可以驱动艺术加工过的人物形象。在艺术家对模特无表情的几何和材质贴图进行一定的修改后,网络对表情的预测结果可以直接应用在它们上面。因为网络预测的是相对无表情几何和贴图的偏差,所以表情变化和皱纹运动都可以真实地反映在修改后的面部几何和材质贴图上。

总结
该项目基于4D动态几何和材质贴图的训练数据,训练多VAE的网络结构从输入的人脸面部表演视频解耦出表情信息并解算出高精度的面部几何和材质贴图,最终得到了真实而细腻的视频驱动人脸效果。将追踪与重定向两个环节自动化与标准化,极大程度地降低了高精度数字人制作与驱动的成本,减少了数字人艺术家的大量重复工作,使他们有更多的时间进行内容向的创作。关于团队
影眸科技是一家致力于数字人底层技术的初创公司,由上海科技大学孵化并于今年上半年官宣完成了来自红杉种子与奇绩创坛的数千万元融资。在今年的SIGGRAPH/SIGGRAPH Asia中,影眸科技共4项工作被接收,在数字人技术与AIGC的交叉领域取得了国际认可的进展。自2022年7月新技术正式开始对外开发以来,影眸科技已为数十家影视游戏行业提供不同等级的面部资产。未来,影眸将进一步提升数字人精度与质量,降低数字人制作成本与周期,为打造元宇宙时代的“数字身份系统”夯实技术基础。