

—— 青亭网

分享
原创 2022-09-13

Esther | 编辑
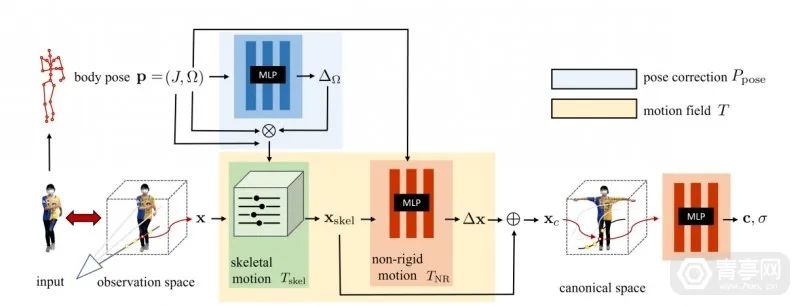
近期,华盛顿大学计算机科学院的GRAIL图形和成像实验室发布了一项基于NeRF合成的新技术:HumanNeRF,该方案的最大特点就是利用AI算法将2D视频合成高保真3D全身模型。科研人员表示:HumanNeRF可从网络视频等2D数据提取动态人像,并进行自由视点渲染。


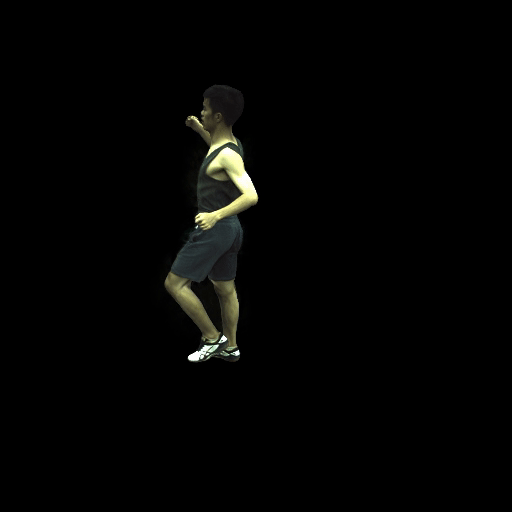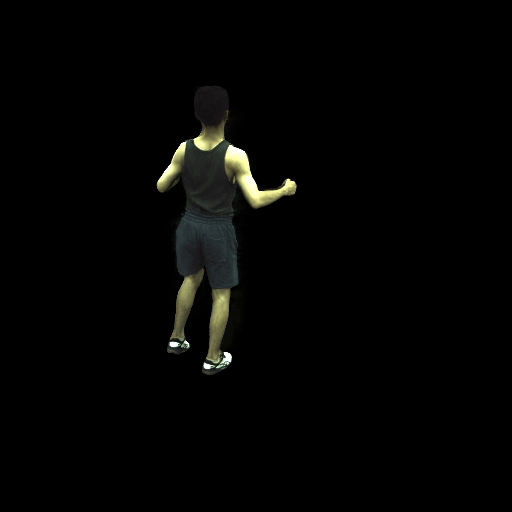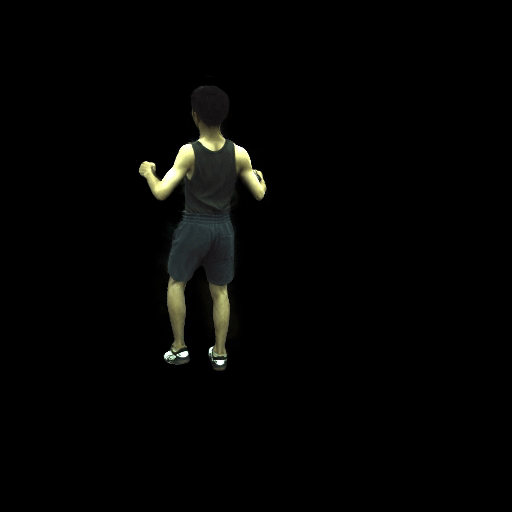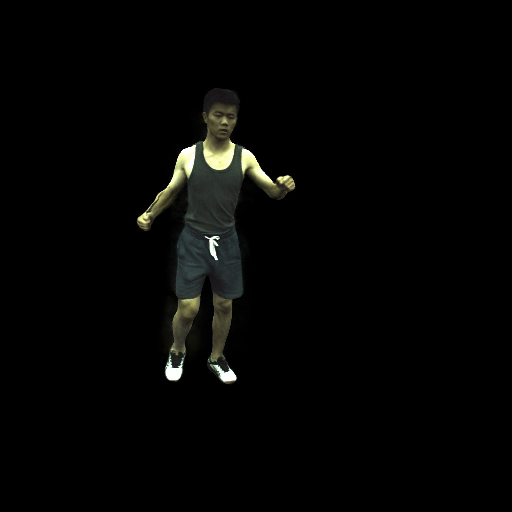



参考:
https://grail.cs.washington.edu/projects/humannerf/
( END)
* 文章为作者独立观点,不代表数艺网立场转载须知

北京
甲方 · 媒体平台
未认证的机构号
2023-07-13
2023-07-12
广告 欺诈 淫秽 色情 侵权 骚扰、辱骂、歧视 敏感 违法 犯罪 反动、政治 其它
数艺网是一个信息获取、分享及传播的平台,我们尊重和鼓励数艺网用户创作的内容,认识到保护知识产权对数艺网生存与发展的重要性,承诺将保护知识产权作为数艺网运营的基本原则之一。
本条款原则如下:
1. 用户在数艺网上发表的全部原创内容(包括但不仅限于文章、案例/项目和评论),著作权均归用户本人所有。用户可授权第三方以任何方式使用,不需要得到数艺网的同意。
2. 数艺网上可由多人参与编辑的内容,包括但不限于案例/作品的认领、企业/机构的认领,所有参与编辑者均同意,相关知识产权归数艺网所有。
3. 数艺网提供的网络服务中包含的标识、版面设计、排版方式、文本、图片、图形等均受著作权、商标权及其它法律保护,未经相关权利人(含数艺网及其他原始权利人)同意,上述内容均不得在任何平台被直接或间接发布、使用、出于发布或使用目的的改写或再发行,或被用于其他任何商业目的。
4. 为了促进知识的分享和传播,用户将其在数艺网上发表的全部内容,授予数艺网免费的、不可撤销的、非独家使用许可,数艺网有权将该内容用于数艺网各种形态的产品和服务上,包括但不限于网站以及发表的应用或其他互联网产品。
5. 第三方若出于非商业目的,将用户在数艺网上发表的内容转载在数艺网之外的地方,应当在作品的正文开头的显著位置注明原作者姓名(或原作者在数艺网上使用的帐号名称),给出原始链接,注明「发表于数艺网」,并不得对作品进行修改演绎。若需要对作品进行修改,或用于商业目的,第三方应当联系用户获得单独授权,按照用户规定的方式使用该内容。
6. 数艺网为用户提供「保留所有权利,禁止转载」的选项。除非获得原作者的单独授权,任何第三方不得转载标注了「禁止转载」的内容,否则均视为侵权。
7. 在数艺网上传或发表的内容,用户应保证其为著作权人或已取得合法授权,并且该内容不会侵犯任何第三方的合法权益。如果第三方提出关于著作权的异议,数艺网有权根据实际情况删除相关的内容,且有权追究用户的法律责任。给数艺网或任何第三方造成损失的,用户应负责全额赔偿。
8. 如果任何第三方侵犯了数艺网用户相关的权利,用户同意授权数艺网或其指定的代理人代表数艺网自身或用户对该第三方提出警告、投诉、发起行政执法、诉讼、进行上诉,或谈判和解,并且用户同意在数艺网认为必要的情况下参与共同维权。
9. 数艺网有权但无义务对用户发布的内容进行审核,有权根据相关证据结合《侵权责任法》、《信息网络传播权保护条例》等法律法规及数艺网社区管理规定对侵权信息进行处理。
侵权举报
1.处理原则
数艺网作为新媒体艺术领域的分享交流平台,高度重视自由表达和个人、机构正当权利的平衡。依照法律规定删除违法信息是数艺网社区的法定义务,数艺网社区亦未与任何中介机构合作开展此项业务。
2.受理范围
受理数艺网社区内侵犯机构或个人合法权益的侵权举报,包括但不限于涉及个人隐私、造谣与诽谤、商业侵权。
a.涉及个人隐私:发布内容中直接涉及身份信息,如个人姓名、家庭住址、身份证号码、工作单位、私人电话等详细个人隐私;
b.造谣、诽谤:发布内容中指名道姓(包括自然人和机构)的直接谩骂、侮辱、虚构中伤、恶意诽谤等;
c.商业侵权:泄露机构商业机密及其他根据保密协议不能公开讨论的内容。
3.举报条件
用户在数艺网发表的内容仅表明其个人的立场和观点,并不代表数艺网的立场或观点。如果个人或机构发现数艺网上存在侵犯自身合法权益的内容,可以先尝试与作者取得联系,通过沟通协商解决问题。如您无法联系到作者,或无法通过与作者沟通解决问题,您可通过点击内容下方的举报按钮来向数艺网平台进行投诉。为了保证问题能够及时有效地处理,请务必提交真实有效、完整清晰的材料,否则投诉将无法受理。您需要向数艺网提供的投诉材料包括:
a. 权利人对涉嫌侵权内容拥有商标权、著作权和/或其他依法可以行使权利的权属证明,权属证明通常是营业执照或组织机构代码证;
b. 完整填写的通知书;附供下载的:侵权投诉通知书;
c. 举报人的身份证明,身份证明可以是身份证或护照;
d. 如果举报人非权利人,请举报人提供代表权利人进行举报的书面授权证明。
e. 为确保投诉材料的真实性,在侵权举报中,您还需要签署以下法律声明:
(1) 我本人为所举报内容的合法权利人;
(2) 我举报的发布在数艺网社区中的内容侵犯了本人相应的合法权益;
(3) 如果本侵权举报内容不完全属实,本人将承担由此产生的一切法律责任,并承担和赔偿数艺网因根据投诉人的通知书对相关帐号的处理而造成的任何损失,包括但不限于知乎因向被投诉方赔偿而产生的损失及数艺网名誉、商誉损害等。
4.处理流程
出于网络平台的监督属性,并非所有申请都必须受理。数艺网自收到举报的七个工作日内处理完毕并给出回复。处理期间,不提供任何电话、邮件及其他方式的查询服务。 出现数艺网已经删除或处理的内容,但是百度、谷歌等搜索引擎依然可以搜索到的现象,是因为百度、谷歌等搜索引擎自带缓存,此类问题数艺网无权也无法处理,因此相关申请不予受理。您可以自行联系搜索引擎服务商进行处理。 此为数艺网社区唯一的官方侵权投诉渠道,暂不提供其他方式处理此业务。 用户在数艺网中的商业行为引发的法律纠纷,由交易双方自行处理,与数艺网无关。
免责申明
1.数艺网不能对用户发表的回答或评论的正确性进行保证。
2.用户在数艺网发表的内容仅表明其个人的立场和观点,并不代表数艺网的立场或观点。作为内容的发表者,需自行对所发表内容负责,因所发表内容引发的一切纠纷,由该内容的发表者承担全部法律及连带责任。数艺网不承担任何法律及连带责任。
3.数艺网不保证网络服务一定能满足用户的要求,也不保证网络服务不会中断,对网络服务的及时性、安全性、准确性也都不作保证。
4.对于因不可抗力或数艺网不能控制的原因造成的网络服务中断或其它缺陷,数艺网不承担任何责任,但将尽力减少因此而给用户造成的损失和影响。
协议修改
1.根据互联网的发展和有关法律、法规及规范性文件的变化,或者因业务发展需要,数艺网有权对本协议的条款作出修改或变更,一旦本协议的内容发生变动,数艺网将会直接在数艺网网站上公布修改之后的协议内容,该公布行为视为数艺网已经通知用户修改内容。数艺网也可采用电子邮件或私信的传送方式,提示用户协议条款的修改、服务变更、或其它重要事项。
2.如果不同意数艺网对本协议相关条款所做的修改,用户有权并应当停止使用数艺网。如果用户继续使用数艺网,则视为用户接受数艺网对本协议相关条款所做的修改。
阅读并同意此认领协议方可认领案例
*认领案例的操作记录无法自行删除,请务必确保您参与该案例身份的真实性











