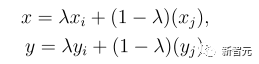【新智元导读】 浙江大学联手西湖大学发布全新数据混合策略AutoMix,具有更高的准确率和更低的计算需求,一同发布的还有一个all-in-one的数据混合仓库!数据增强一直是图像领域的基本操作,能够在数据量不变的情况下,增强神经网络的泛化性能,尤其是对Transformer等大参数量的模型来说,数据量不够很容易导致 欠拟合 。
数据混合增强 (data mixing augmentation)技术是一种新兴的增强方法,比如说需要对狗和猫的图像进行分类,图像混合的过程是对两幅图像进行简单的平均,然后再重新计算图像的标签值,可以为不同的类提供了 连续的数据样本 ,直观地扩展了给定训练集的分布,使得网络的泛化性能更强。 早期的混合增强技术主要依赖于 手工策略 ,比如Mixup通过对数据对进行线性组合的方式生成新样本;CutMix则是设计一套patch替换策略,随机从其他图像中替换patch。 而近期的一些研究方法则利用图像中的显著性(saliency)信息通过复杂的 离线优化 方式来混合样本和标签。尽管通过这种方法训练的模型准确率更高,但 计算的复杂度 也很高。 为了权衡准确率和复杂度,浙江大学和西湖大学的作者提出了一个新型自动混合策略(AutoMix)框架,实现了「参数化」,并且可以直接用于多个分类任务中。
论文链接: https://arxiv.org/pdf/2103.13027 同时,研究人员还将众多mixup相关的方法实现在开源框架OpenMixup中,支持多种主流网络架构(CNNs, ViTs, etc.)、各类实验设定和常用数据集 (CIFAR, ImageNet, CUB-200, etc.),并提供了常用数据集上mixup benchmark。
仓库链接:https://github.com/Westlake-AI/openmixup
OpenMixup能够支持主流自监督学习算法(对比学习和Masked Image Modeling)。
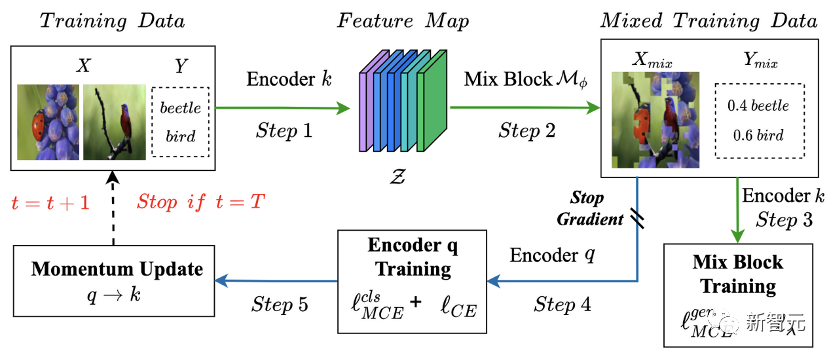
我们发表于ECCV2022 (Oral)的工作尝试并实现了一种具有「闭环自反馈」的学习框架(AutoMix)以解决「数据-模型」动态系统中的复杂度和准确性的权衡问题。 具体来讲这是一个数据随模型变化,模型随数据更新的双层优化问题。
不同于固定的数据增广策略的模式(独立于模型的优化),AutoMix将参数化后的mixup数据增广策略融入到判别模型中,形成一个完整的数据与模型相互学习的闭环系统,即同时学习mixup样本的(1)生成任务和 (2)判别任务。 (1)是根据判别模型的状态自适应的学习精确的数据生成策略;(2)则是基于所学习的增广策略来增强模型对数据中重要特征的判别能力。这两种子任务服务于一个相同的优化目标,具有自一致性。 大量实验也表明,判别式模型在AutoMix的闭环自学习系统(自一致性+闭环反馈)中具有更高效学习效率和明显的性能提升。 神经网络模型(DNNs)的泛化性能在机器学习领域一直受到广泛的关注和研究,DNNs能兼具高性能和泛化性通常需要满足两个条件:1)过参数化的模型。2)充足的训练样本。 但是,在数据量不足或DNNs模型复杂度过高的情况下,模型容易出现过拟合现象,导致性能和泛化能力明显下降。
数据增强(Data Augmentation, DA)算法作为一种DNNs正则化手段能够显著提升模型的泛化性能,而基于数据混合(Data Mixing)的一系列数据增强算法,兼顾了样本和标签。 基于混合的增广算法通过凸性组合(Convex Combination)来生成虚拟样本和标签,达到扩充样本量和提高数据分布多样性的目的。
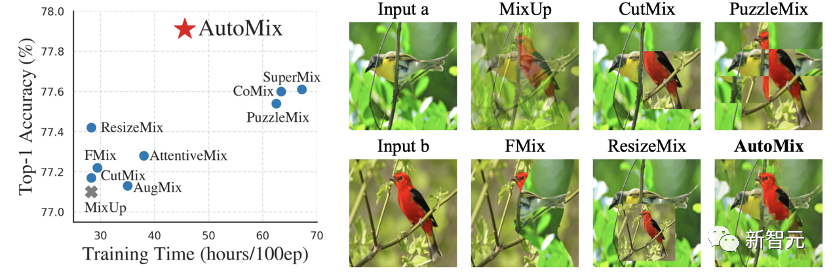
样本混合增强算法的核心问题是如何生成合理的混合样本以及对应的混合标签,在图像分类任务中,一般固定混合标签的生成方式,改进混合图像的生成算法。 如下图所示,CutMix将一张图像的局部区域随机替换为另一张图像的对应区域,并根据混合图像上不同像素的面积比例生成混合标签。 但是由于CutMix在原图上选取局部区域的位置和尺寸均是随机选择,可能出现被切割的区域不包含分类任务相关目标的现象,这将导致混合标签与混合图像中目标的语义不匹配而误导模型的优化。
为了解决该问题,PuzzleMix和Co-Mixup等基于图像显著性区域(Saliency Region)和组合优化算法设计了较为精确的样本混合策略,使得类别相关的区域在混合后的样本中保留下来。但是这种间接优化方式引入了大量的额外运算开销,这对于追求高效的数据增广方法而言是极为不利的。因此,该工作主要讨论了以下两个问题: 如何高效的解决mixup生成和分类的双层优化问题? 为了 解决这两个问题,我们先对mixup问题进行了重定义并提出了「闭环自反馈」框架: automatic mixup(AutoMix)。 如下图所示,AutoMix不仅可以精确定位目标区域并准确生成混合样本,而且在一定程度上减少了额外计算成本,提高了训练效率。 基于以上,我们进一步考虑mixup classification问题:给定样本混合函数样的 混合比例 们可以得到混合后的样本 通过 我们最终的目的是训练一个好的分类器,故mixup样本生成是服务于分类任务的辅助任务。一般情况下,我们会使用one-hot形式对标签进行编码,基于这种信息固定且无序的标签编码方式,标签混合函数 3.3 Offline mixup limits the power of mixup
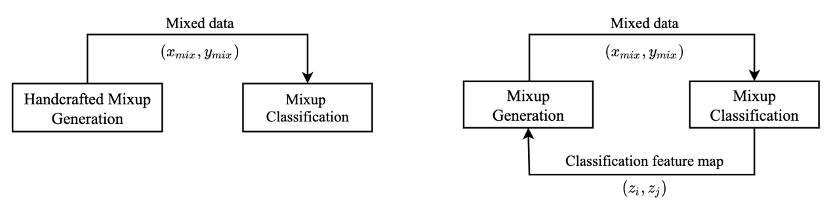
为了优化上述函数,现有的方法主要采用非参数化的方式将 如下图所示,左图中手工设计的mixup所对应对的混合样本生成是独立于混合样本分类任务的,所以他们所生成出的混合样本可能与最终优化目标无关因此存在冗余甚至降低训练效率。为了解决该问题,我们提出了具有闭环自学习性质的AutoMix,如右图所示,成功把这两个子任务动态得联系了起来。
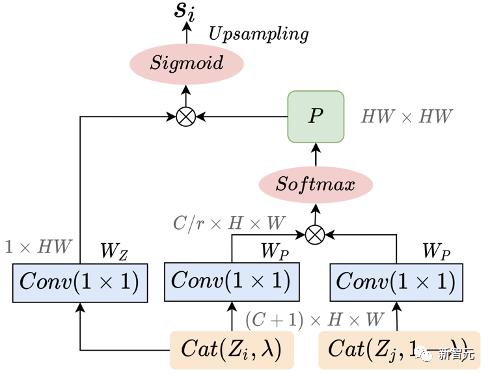
4.1 Parametric Mixup Generation 参数化的mixup policy 其中
4.2 Mix Block
的目标是生成一个像素级的掩码 为线性变换矩阵; 其中, 在Mix Block的端到端的训练方面,我们提出了一个辅助损失函数,用于帮助Mix Block在训练早期生成与 是一个随着训练渐变为0的损失权重,初始值为0.1。此外,我们在使用MCE loss的同时也加入了标准的CE loss,主要是为了加速主干网络的学习以提供稳定的特征给Mix Block生成新的混合样本。AutoMix的最终优化目标可以总结为: 但是我们发现,在一次梯度反传中同时更新
4.3 Momentum Pipeline
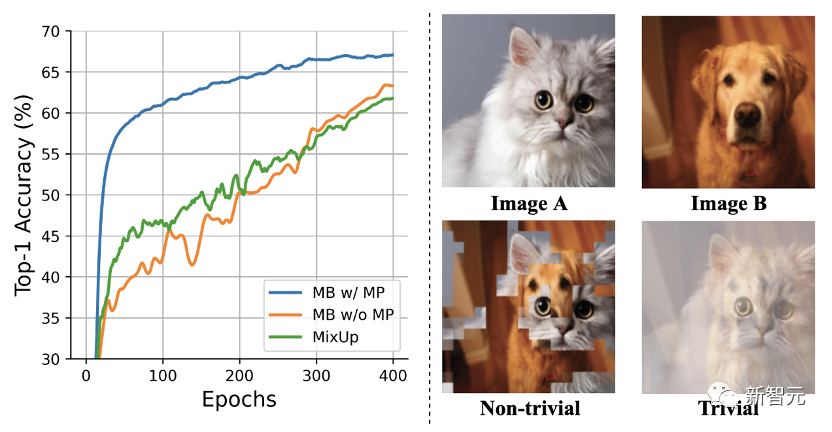
受自监督学习中解决特征塌缩(feature collapse)问题的启发,我们也尝试通过使用stop gradient操作和孪生网络(Siamese)来解决Mix Block塌缩点问题,从而稳定AutoMix训练。
如上图所示,绿色的计算流通过使用冻结的encoder 在MP的加持下,我们可以能看到最直接的效果就是Mix Block的训练变得稳定且收敛快速。如下图所示,Mix Block在前几个epoch就可以为主干网络提供高质量的混合样本。
我们对AutoMix做了全面的评估,主要分为以下三个方面: (1)多场景下的图像分类问题,(2)基于对抗样本的鲁棒性测试和(3)迁移到其他下游任务的性能表现。 AutoMix均表现突出,达到最佳性能。
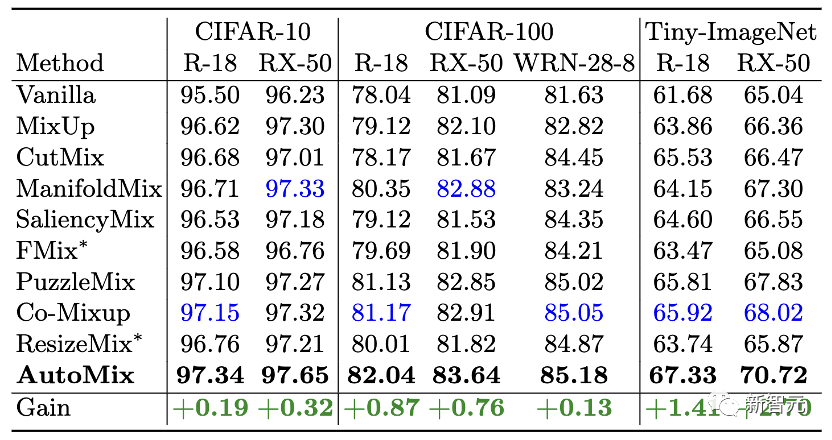
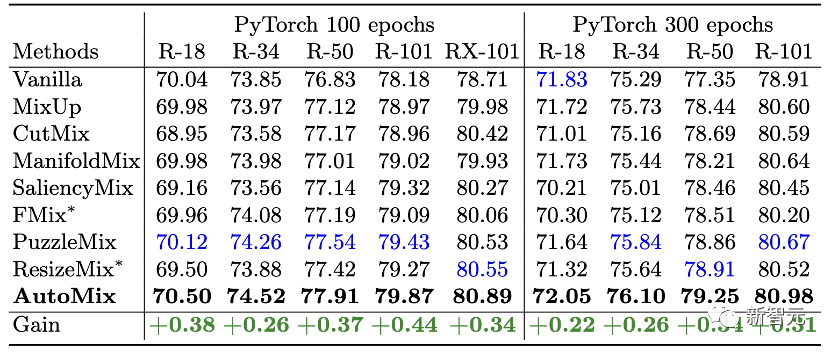
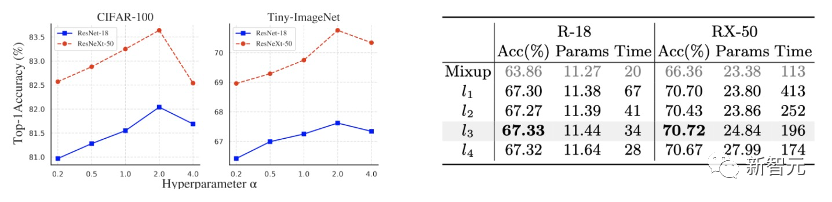
在图像分类的经典benchmark上进行大量测试,主要测试数据为CIFAR、Tiny ImageNet和ImageNet。 在小分辨率数据集上,我们基于ResNet、ResNeXt和Wide-ResNet对比了主流mixup算法。
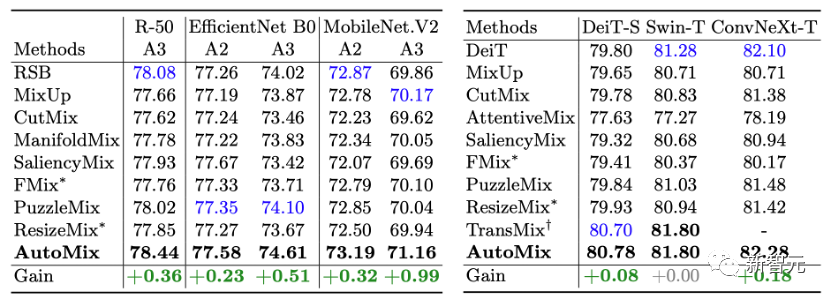
ImageNet: 在ImageNet上,我们基于不同参数量的ResNet和主流Transformer架构对比了更多实用的mixup算法。 有一个比较有趣的现象是其他mixup方法在基于ResNet-18网络在ImageNet上训练时都起到了负面效果,一个可能的解释是mixup方法所生成的混合样本过大的增加了学习难度。 而AutoMix生成的样本尽可能与语意保持一致,更贴切真实数据分布,适当增加了数据的丰富程度。
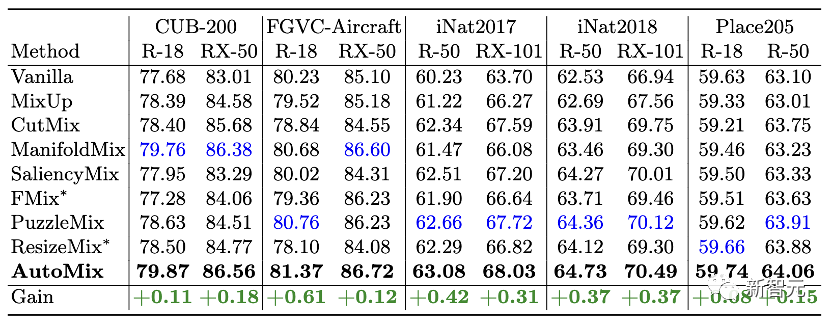
Fine-grained and Scene Classification: 此外,我们也做了全面的细粒度分类能力测试,包括经典的CUB-200和FGVC-Aircraft和更具有挑战性的大规模数据集iNaturalist17/18。 同时,我们在Place205上测试了场景分类性能。 在各类场景上,AutoMix均取得最佳性能。
Calibration: mixup方法可以对分类模型过度自信的(over-confident)预测起到矫正的作用,即分类准确度和置信度应该保持线性的对应关系,我们既不希望模型对预测错误的样本有过高的置信度,也不希望对预测正确的样本是低置信的。如下图所示,AutoMix更加贴近红色虚线,起到了最佳的矫正效果。
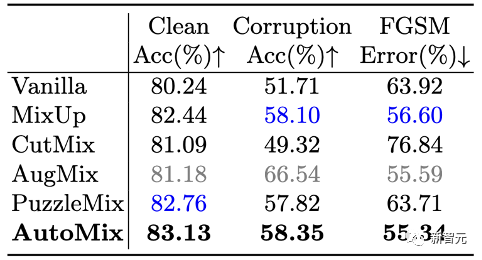
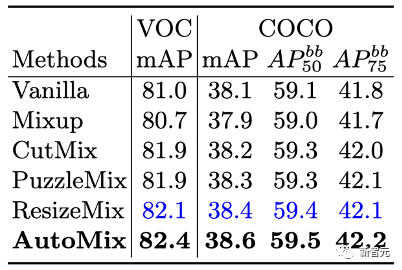
我们使用人造数据集CIFAR-C和对抗攻击手段FGSM来测试模型的鲁棒性。 与其他mixup方法一致,我们分别在CUB-200和COCO2017数据集上对弱监督目标定位和目标检测这两个常见的下游任务做了测试。效果如下:
Weakly supervised object localization
消融实验主要分析了三个问题:(1)Mix Block中所提出的模块是否有效?(2)如果去掉EMA和CE loss,模型性能会受多少影响?(3)AutoMix中的超参数应该如何选择? 上面的两个表格回答问题(1)和(2)。左边的表验证了cross attention模块、 下图回答了问题(3),AutoMix的超参数包括 https://zhuanlan.zhihu.com/p/550300558