
- 0
- 0
- 0
分享
- AIR学术|周谷越副教授谈“从仿真到现实:走进千家万户的智能机器人”
-
原创 2022-07-06
活动概况
6月29日下午,第23期AIR学术沙龙如期举行。本期活动荣幸地邀请到了AIR副教授周谷越为我们做题为《从仿真到现实:走进千家万户的智能机器人》的报告。

本次活动由AIR副院长、清华大学计算机科学与技术系长聘教授刘洋主持,AIR官方视频号和b站同步直播。
讲者介绍

报告内容
一、智能机器人的行业背景与难点解析
周谷越教授首先介绍了智能机器人的定义,即具有感知、决策及环境交互能力的自主机器人。目前,世界范围内市值过万亿美元的六家公司中已经有五家针对机器人行业进行了相应部署。其中具有代表性的项目包括苹果公司推出的自动驾驶汽车、亚马逊推出的无人机快递配送,以及特斯拉待发布的人形机器人等。

虽然如此多的国际顶尖企业都在机器人赛道开展了相应布局,但我们在日常生活中很难见到这些智能化机器人的应用,主要原因之一便是智能机器人开发的复杂性。
一般的智能机器人系统开发流程与强化学习步骤类似,主要包括五个方面,分别为:构建软硬件实体、搭建实验环境、设定奖励机制、制定初始策略和迭代改进策略。随着上述流程的执行,开发者需要开展机器人结构搭建、寻找实验场地、采集实验数据、仿真计算、迭代优化和保障实验安全等一系列昂贵且繁琐的工作,智能机器人的整个开发过程充满艰辛与挑战。
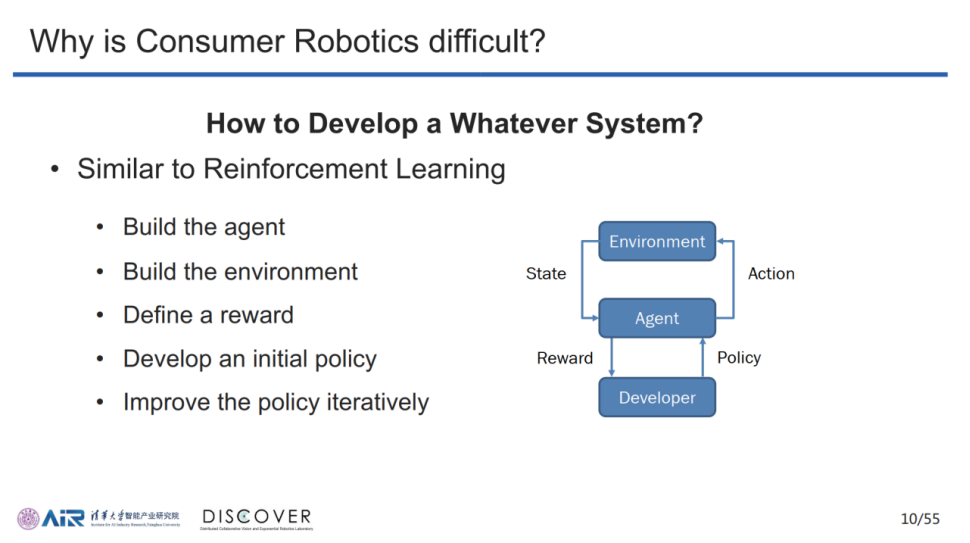
纵使研发团队成功完成了机器人功能的开发,但任何一款产品的发布势必要经历市场的考验,因此如何将“实验室原型机”转化为“消费级机器人”又是智能机器人产业化的一大难点。
在消费机器人的制造方面,除去原有的实验样机制作要求,整体生产流程又增加了新产品导入阶段和量产阶段两部分的影响因素,新内容的加入代表了原型机与量产机的差异化性质,造成了产品评价函数复杂化、价格约束严苛化以及系统体量明显增大的问题。
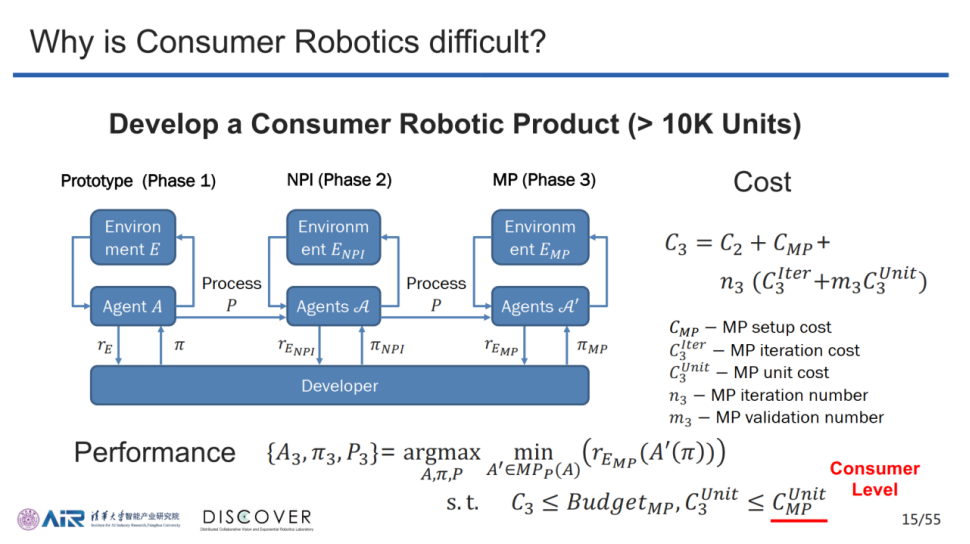
综上所述,由于消费级机器人产品技术难度较大、研发成本高昂、量产品控流程繁琐等因素,导致当前消费级机器人的实际售价与消费者的低成本期望冲突较为严重,最终形成了消费级机器人落地难度较大的基本现状。
二、Sim2Real的含义与技术路线
在机器人开发过程中,往往不会将软硬件直接集成在真实机器人上,而是先在仿真环境中进行技术验证。仿真具有收集数据迅速、成本低、可提供真值即准确标签、可轻松提供真实世界中的低概率场景、稳定可复现、安全不损伤人和机器人等优点。过去十年,深度学习催生了利用大数据产生智能的新模式,在计算机视觉、机器翻译等不同领域取得了诸多成果,数据驱动的相关技术也被应用于机器人行业中。然而在机器人领域,数据的获取成本很高,Sim2Real也因能在仿真中便捷产生大量数据训练深度学习算法而重获关注。
一般的Sim2Real方法是指在仿真环境中进行算法设计与调试,将仿真优化所得策略部署在真实物理平台,使其与真实环境进行交互。这种方法的弊端在于真实环境的反馈数据获取成本较大,且受到实际实验步骤的限制,无法进行大批量的重复性测试,导致实物实验效果普遍不佳。

对当前Sim2Real的发展现状总结来看,policy Sim2Real(传统Sim2Real)很难提升机器人的实际表现,close-loop Sim2Real(闭环Sim2Real)的研究热度正逐步提升,agent Sim2Real(智能体Sim2Real)仍处于发展的早期阶段。相较早期的Sim2Real,当下重新提出的Sim2Real思想主要新增了域随机优化和闭环Sim2Real两方面内容。
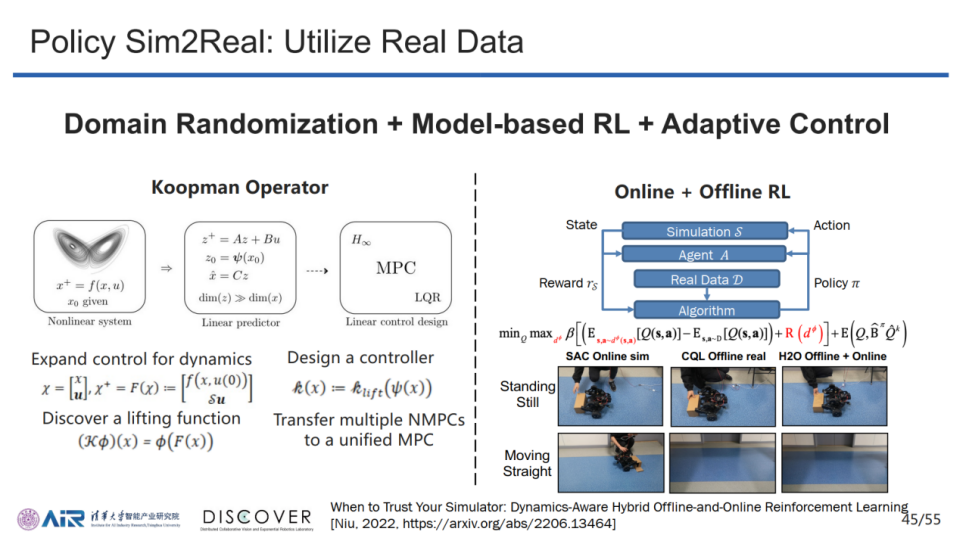
域随机优化扩大了仿真阶段的可行空间,能通过随机替换无关数据让agent标定的标签只与特定的特征相关。而具体操作中,通过随机置换一些特征在仿真中加入新的仿真数据,能够增强仿真训练数据的丰富程度,并提高仿真所得策略在正式环境中工作的有效性。
为了提高机器在真实环境中的表现,学界提出一种理想的闭环Sim2Real结构,该结构提供了两组控制策略。其中,与仿真相关的控制策略调节采用了真实交互数据作为信息来源,而与机器实体相关的控制策略则依据仿真结论进行优化,从而实现了一种理想的闭环结构。闭环Sim2Real的实操关键正是两组控制策略的联合优化问题。

以机械臂开抽屉的案例为例,闭环Sim2Real采用一定的真实数据采集方法获取实际机器人操作,并将所得反馈数据加入下图“D”所示步骤中,成功解决了系统辨识的相关问题。最后,该操作将相关计算参数送入访问器当中,实现了一个完整的闭环过程。

三、应用实例
在AIR近期举办的以close-loop Sim2Real为核心的系列挑战赛中,为降低close-loop Sim2Real对环境信息的交互需求,该赛事采用参赛者基于仿真环境调试算法和官方实测提供反馈数据的形式,完成了整体闭环。

在控制方面,AIR尝试将Domain Randomization(域随机化)、Model-based RL(基于模型的强化学习)和Adaptive Control(自适应控制)的内容相结合,采用Online+Offline RL(在线+离线强化学习)构建一种真实数据和仿真数据综合作用的控制方法,目前已完成了一些尝试。团队一致认为该研究方向具有较高的研究潜力,未来期望该方向能取得一些理论突破,从而更好地完成集群控制等方面的具体任务。
文稿撰写 / 李育峰
排版编辑 / 蒲睿熙
校对责编 / 黄 妍
关于 DISCOVER 实验室
DISCOVER实验室是AIR科研方向的横向支撑实验室之一,旨在利用机器学习、计算机视觉、计算机图形学、机器人学、运筹学、高性能计算与人机交互等前沿技术,围绕车路协同(V2I)、用户直连制造(C2M)、实验室自动化等各应用场景,构建以感知、规划、控制与决策为核心的智能算法平台体系,结合涵盖设计、工艺、计算与人因的智能系统架构体系,研究人-机-边-云四位一体的人在环路多智能体协同系统,开展具有创新性的算法理论与系统架构研究,紧贴以制造业为主的国家重点行业需求,攻克以人为中心的场景理解、人在环路机器学习、仿真到现实迁移与柔性制造工艺等关键技术瓶颈,与产业界深入合作探索自动驾驶与柔性制造的范式转移路径并实现关键技术验证与落地,推动我国在智慧交通和智能制造领域的产业升级。
关于AIR
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号清华大学智能产业研究院 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
-

-
北京
甲方 · 公立学校
未认证的机构号
recently released
-
2023-04-29
-
2023-04-28
提名奖")










