
- 0
- 0
- 0
分享
- B站UP主研究超写实虚拟人新玩法,如何实现“以假乱真”?幕后专访来了
-
原创 2022-05-05
五一大家都休息好,玩好了么?今天上班了,打起精神搬砖吧。
今天我们来聊聊AI与超写实数字人。
“假老黄”


还记得去年给大家解析的老黄在创房发布会上“造假”的技术么?
你以为是黄仁勋本人在录制视频?对,当时没有公布解析之前,大家都以为是老黄本人。

其实他只是3D数字人。就连视频中的背景都是合成制作的。这就是Ai的神奇魅力。
AI作为几年备受关注的话题,只要说起人工智能,我觉得没人会不想到去年英伟达黄仁勋的一场发布会,当时在“厨房里做主题演讲”、“以假乱真”这一话题直接迅速出圈,火爆全网。这种逼真、自然的效果让人不经好奇幕后的制作。那场“厨房演讲”中的厨房背景就是一个不小的制作,制作团队先是对真实的厨房的各个角度拍摄了数百张的照片,然后通过一个摄影测量软件创建了一个粗略的模型用来进行缩放等处理。其次厨房里的一切都是通过合成制作,场景中还有很多隐藏物体这些都是厨房的制造组件,一个场景中可能会有6000到8000个物体,以及数亿个多边形。
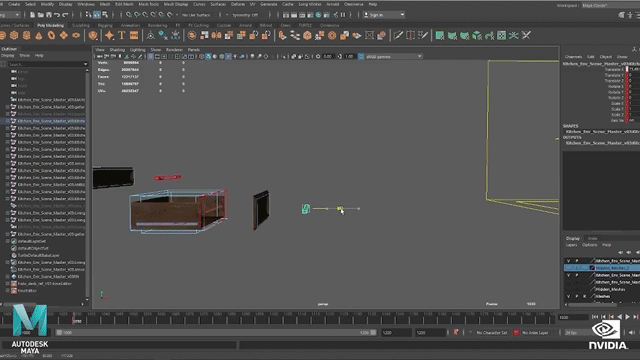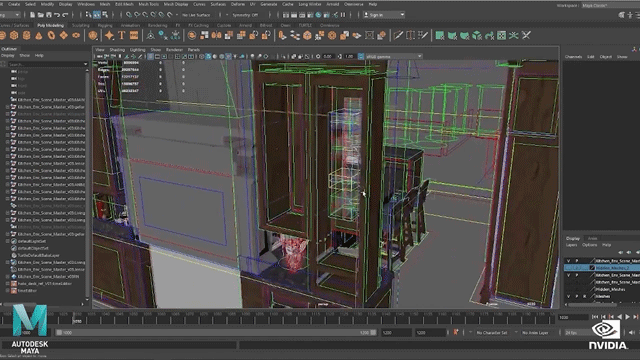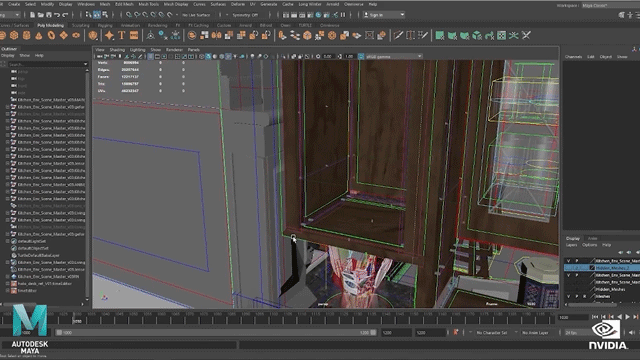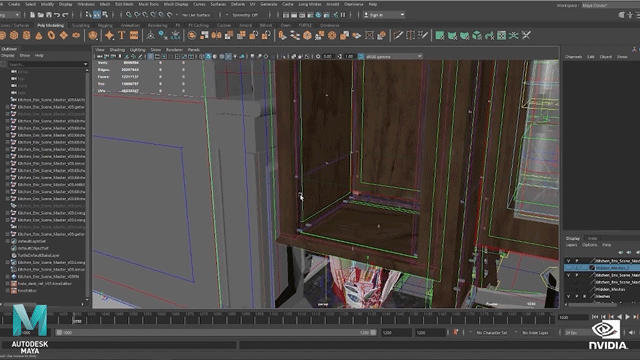
场景都如此复杂,更何况是3D数字替身。制作团队对黄仁勋的数据进行采集建模,然后就到了关键的部分让面部和身体“活”起来!黄仁勋的面部是NVIDIA的Audio2Face技术驱动完成的,并且还运用了一项名为Face Video to Video的技术。通过这项技术,还能够填补CG模型的带来的恐怖谷效应,从而就可以创建一个全屏拍摄的真实效果。
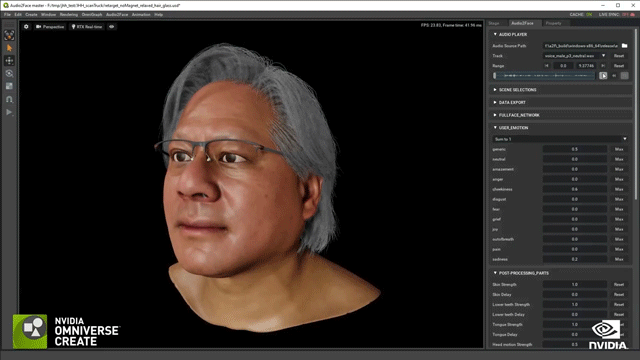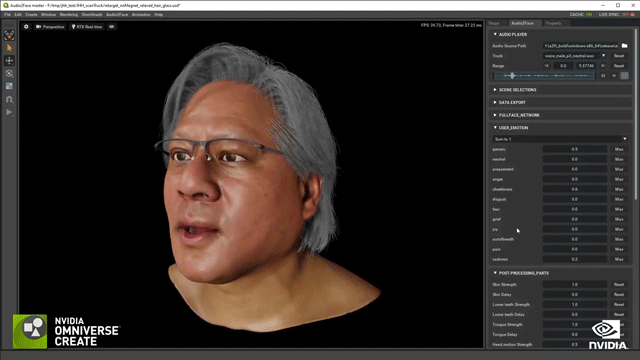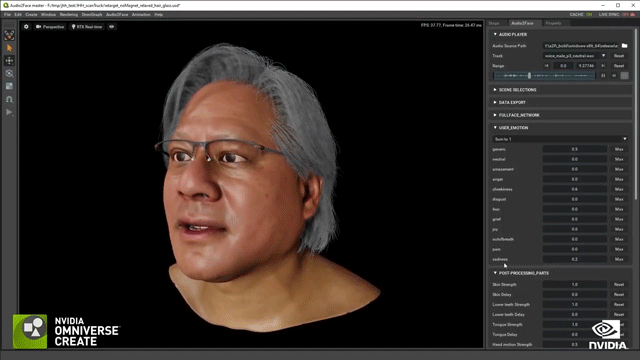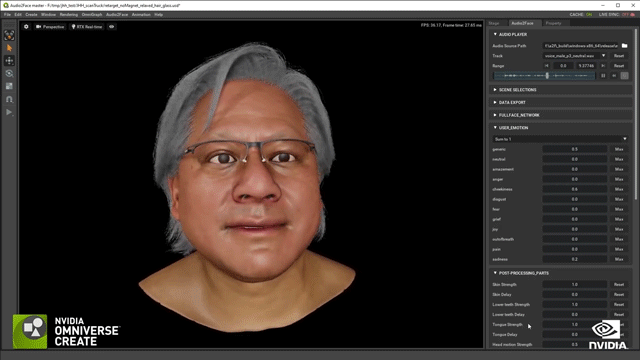
关于身体部分,有一项叫做Audio2Gesture的技术,通过它可以把音频输入和输出的行为特征体现在实际说话中。
超写实汤姆克鲁斯
AI技术的发展仿佛在创造一个又一个的奇迹,如果说英伟达这个“数字替身”发布会是去年的事情不够新颖,那么日本全能大神Hirokazu Yokohara
,在今年分享了他用DeepFaceLive+FACEGOOD和Maya控制器结合实现了实时的写实面部捕捉系统,效果让人震撼。当时在CG圈也引起了不小的轰动。
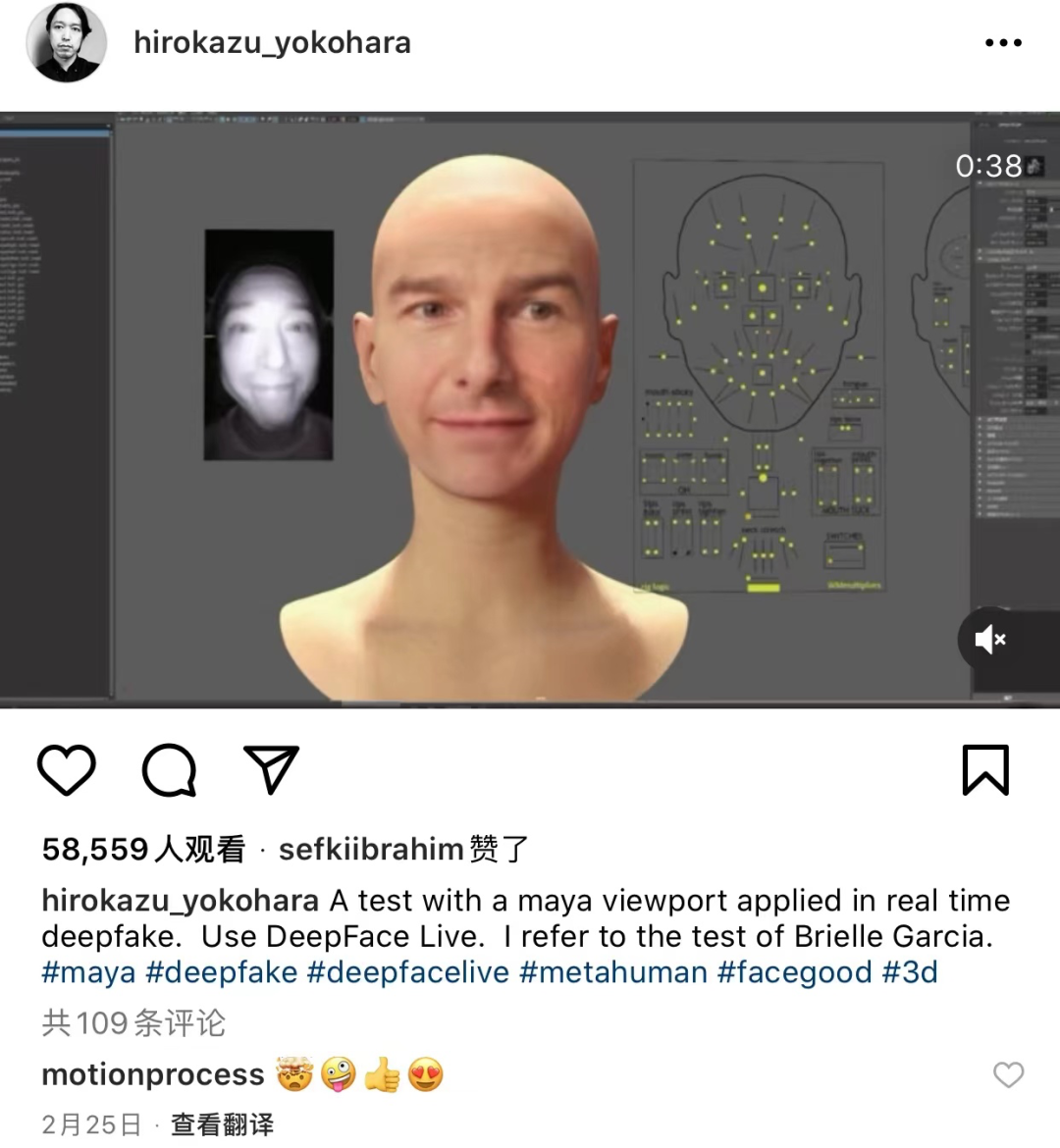
Hirokazu Yokohara展示了一张明星的面部,乍一看很容易被误认为是真人。根据Hirokazu描述,项目是对应用于实时场景中的Maya视口的测试。为了创建deepfake本身,作者使用了DeepFace Live。面部捕捉使用的是FACEGOOD。工作流程基于AR/VR软件开发人员Brielle Garcia的工作流程。
看了那么多的3D数字人,一次又一次的印证了Ai将会给我们的生活带来前所未有的变化和体验。让数字人“以假乱真”的话题也是当下行业内技术大佬们一直在关注的话题。
B站UP主新玩法制作虚拟人
前几天逛B站,又刷到了一位我们国内UP主测试软硬件结合做虚拟人的,题目叫《AI会取代我?》 满怀期待的点开,开头的弹幕最先吸引到我,UP小哥全程幽默的方式讲解技术干货,看完他们这期内容,这完全是我一直想找的主题!!!

来,请大家使劲戳开下面小程序,
看看UP主视频内容▼
视频经UP主授权
视频有点长哈,这里我简单给大家拆解下。
主要说的是UP主为了测试AI和深度学习技术对现代影视制作的应用和影响。但因为其中阿威的小伙迷恋上游戏,所以为了不拖更,主创打算做一个数字人来替代阿威。由此开始了漫长的制作过程。流程大家都懂,就是人物建模、动作捕捉,渲染输出。
他的第一个方案是Character Creater,这个软件我们很熟悉了,不用我再赘述了。直接把人物面部照片扔到软件里,调整人体比例大小形体就可以了。
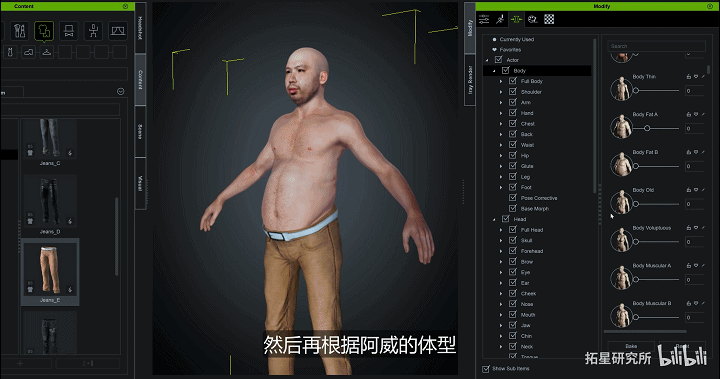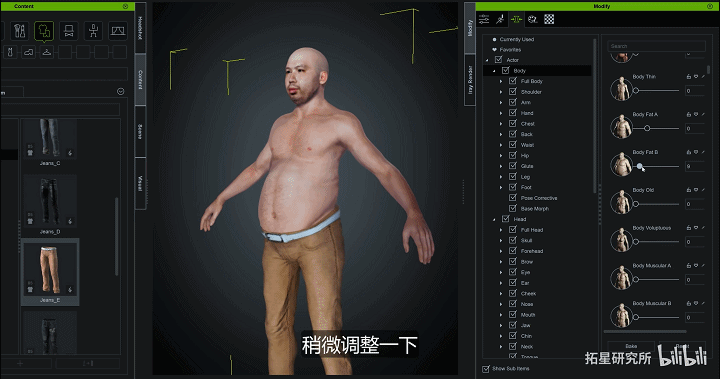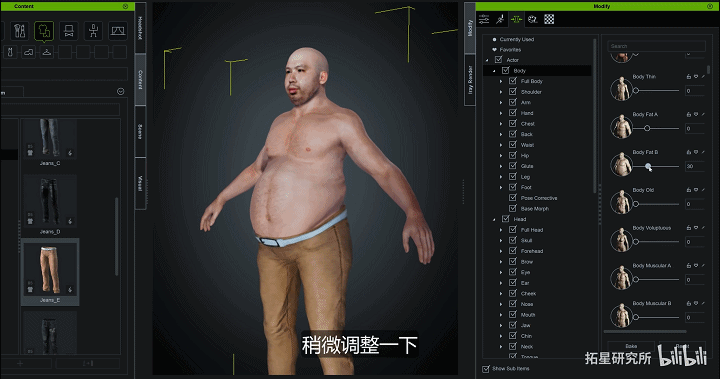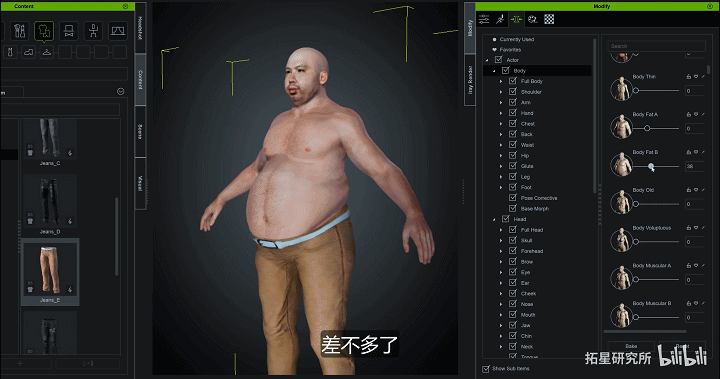
身体动捕设备是用的Rokoko
面部捕捉用的是手机Liveface直接把面部动作数据传输给iClone,然后,然后得到结果是这样的。

显然效果不行。
然后UP主转向Epic新出的MeteHuman。按照阿威照片开始捏脸,完事动捕,这里面部捕捉需要用Epic推出的那个Live Link Face,然后结果是这样的:

显然,在皮肤真实性和面部表情上还是僵硬,太假了。
看来面部表情捕捉上不能省,必须用专业的面部捕捉了。于是开始寻找专业设备,对比之后选择了国产品牌FACEGOOD。

经过Maya复杂的建模过程后,结合FACEGOOD,一顿操作,然后得到的结果是这样的:

这次效果上要比前两次好一些,但是UP小哥觉得离“以假乱真”这样的理想结果还是差点意思,很多眼尖的小伙伴仍然一眼看出是CG的。
视频最后UP小哥最终想到了一个办法,AI大法!于是尝试AI+FACEGOOD的混合试验,果然再AI的加持下,终于得到了一个以假乱真的虚拟数字人的效果。就是开头看到的效果。

至此,大家可以看见,效果确实非常惊艳。视频开头很多网友也都没看出,直到后面才发现开头视频里就是的阿威其实是“数字人阿威”。但整个视频中UP小哥还是给大家留了个悬念,就是最后这个流程是如何实现的,没有详细说。
视频发出后,一下就火了,在行业内也引起极大的关注度,视频从国内传到国外,行业大佬们也纷纷在讨论其背后的技术方法。
被YOUTUBE的海外行业大佬Jsfilmz点评到。
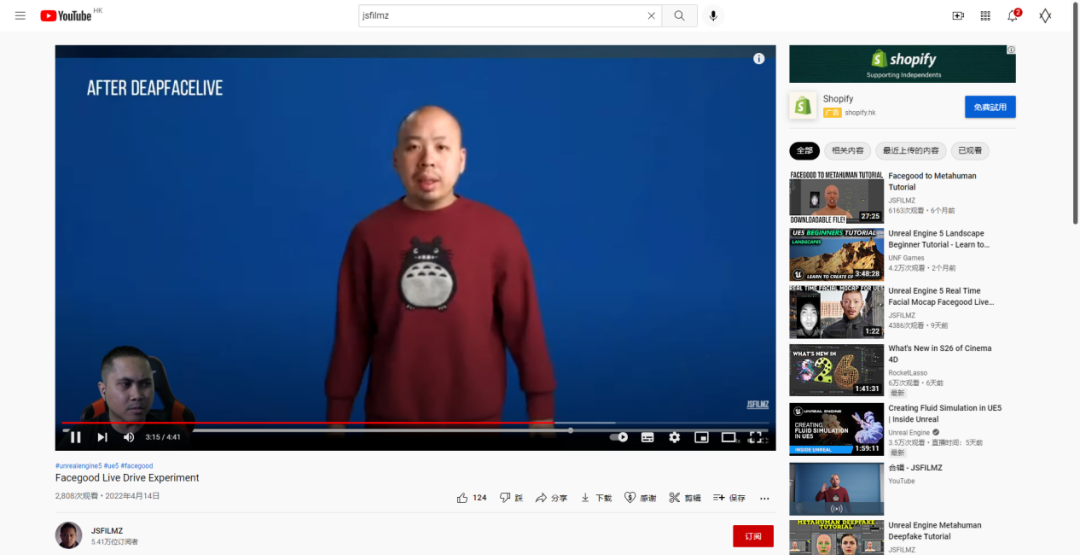
在收获大量称赞的同时,也又不少对其中那段“以假乱真”视频的质疑,怀疑就是人物的实拍。但对于我这个半专业的人,我关注的并不是是否实拍,而是最后的FACEGOOD+AI的流程到底是如何实现的呢?带着这个疑问,我们找到了UP主团队拓星研究所进行了专访。
来吧,一起走进专访。
专访拓星研究所
行业内的朋友都对你们团队挺好奇的,你们的作品涉及了非常多的技术,很想知道背后是个怎样的团队,可以给大家介绍下拓星研究所吗?
拓星研究所:我们是一家自媒体公司,会在B站更新我们的视频,一般会做一些新奇有趣的影视类经验分享,有好点子的时候也会出一些创意短片或者剧情向的故事短片。
公司目前有4个人,大家基本都是多面性的,身兼多职,每个人也都有自己侧重的部分,Sam侧重制片商务,达庆侧重摄影剪辑声音,达威和李叔侧重后期特效之类的。一般创意策划部分都是我们一起讨论。
通常硬核的技术分享比较小众、枯燥,所以我们想尽量做到如何将一些硬核且贴合当下时代的技术,用有趣的形式讲述出来,这个权重的倾斜,我们还在不断尝试中。如果在某一期中,观众对于详细的技术细节呼声比较高,我们也会专门出一期详细的经验分享专栏。
好玩、有趣、不断探索是我们做视频的出发点,在执行的过程中,我们在各种影视相关的软硬件技术加持下才得以实现我们的想法,所以这个过程是相辅相成的。
最近在行业内比较火的那段《Ai会取代我?》,这段视频在制作上各个环节花费了多久的时间?
拓星研究所:整段视频的制作时间大概在1个月左右(其中剧本创作大概一周,拍摄3天,剩余的时间的就是后期跟技术测试)
身体的动作捕捉都是用的Rokoko
CC模型+iphone+Iclone面部捕捉+Blender渲染 测试2天
Metahuman模型+iphone面部捕捉+UE渲染 测试4天
Metahuman模型+FACEGOOD面部捕捉+Blender渲染 测试4天
Deepfake学习用了2周(大部分时间用于测试与训练模型)
视频里其实从侧面对比了几个面部表情捕捉的方案,在创作实践中尝试的几种方案的优缺点是什么?最终选择的解决方案技术点体现在哪里?
拓星研究所:先说下,Rokoko的身体动捕我们不太满意,经常出各种各样的问题,例如:连接失灵,动作抽风,手指畸形。有些是无法修复的。
CC模型+iphone+Iclone面部捕捉:
优点:模型调节空间大,身体和头部可塑造程度较高,流程简单。
缺点:模型面部绑定精度不够,iphone面部捕捉的效果也不太好,特别是一些细微表情,几乎捕捉不到的,而大开大合的表情准确度也不好(为了得到相对好些的效果,只能在面部捕捉的时候,表演得特别夸张)。
Metahuman模型+iphone面部捕捉:
优点:模型面部绑定精度高了很多,一些动幅较大的表情捕捉的还不错。
缺点:模型可塑性不高,在还原人物样貌方面不如CC,面部的效果缺少微表情,不讲话只是做一些表情还好,如果正常讲话效果就很一般,有50%的情况嘴型与台词无法对上。
Metahuman模型+FACEGOOD面部捕捉:
优点:模型优点同上,面部捕捉方面好太多了,绝大细微表情都可以通过手动训练得到,正常说话的效果也非常好,嘴型与台词在95%的情况下都可以对的上。
并且也可以livelink到CC或者UE之中,效率上也很高,而且livelink的效果比Iphone要好
缺点:上手难度稍微高了一点点(懂三维的话应该适应1天2天就能会)
最终选择了Metahuman模型+FACEGOOD面部捕捉,要说技术点,就是手动训练了,在AI的辅助下手动训练的过程其实是挺容易的,而且效果很好。前提是必须模型面部捕捉的绑定要好。
最终那段以假乱真的阿威,技术流程是怎么实现的?
拓星研究所:用Metahuman调整一个大概和阿威类似的模型,导入Maya中。
用FACEGOOD进行面部捕捉,Rokoko进行动捕,这里要同步录音,为了后期制作衣服方便,我们最开始的动作会摆成T字型。
将面部捕捉数据在FACEGOOD的软件Avatary中进行训练再导入Maya中进一步训练。
将原本Maya中的Metahuman模型进行与HumanIK重定向。身体动补的数据也导入Maya,利用HumanIK重定向并且保存成Mocap。再将两者动作匹配,并优化动作。
做好动画后导出成ABC格式分别进到Blender和MD,Blender负责做毛发渲染,MD负责做衣服。
渲染好之后,就剩最后一步了,AI换脸,我们用的是DeepFaceLab。这里需要大量阿威头部的素材,让电脑进行学习训练,我们前前后后大概训练了2周吧。
将DeepFaceLab训练好的素材再导入AE进行最终的合成。
不过DeepFaceLab依然还是存在一些问题的,例如眼神和头的细微无规律缩放,这两个问题我们还没解决,应该是我给到电脑阿威原素材不够多的原因吧。
视频里比较重视表情捕捉的精准度,面部捕捉在整个流程实现上有起到什么作用?
拓星研究所:FACEGOOD的P1面部捕捉 作用可以说非常大,表情捕捉就好像是一个基础。因为我们想要做的是有台词,有表演的虚拟角色,所以只有在表情捕捉到位后,这段“表演”才算成立,如果没有好的面部捕捉,就好像是找了一个演技很差,一个话连都说不清楚的机器人来进行演绎,这样的效果可想而知。所以我们这次如果没有FACEGOOD这样高精度的面部捕捉设备,那么就做不出想要“以假乱真”的效果。
有行业内的朋友在社群看到这段视频后认为那段"以假乱真"的片段是实拍的,比如大家会质疑MHC建模出来的人像是没有头发的,可在后面头发侧面可以看到毛发,可以为质疑的朋友解惑一下?
拓星研究所:AI换脸不会凭空将表情变好,所以FACEGOOD驱动metahuman的表情是基础,因为这一部决了用AI换脸的表情是否自然。有些朋友质疑我们说以假乱真的片段是实拍的,像Metahuman的头是没头发的,但AI换脸后头发长出来了,对于这些评论,我们看到是欣慰的,因为这些都是很高的评价。AI换脸现在其实有半脸,脸,整脸,头这几种模式。其中头模式是可以将头发换掉的,不管是头发的颜色还是形状。
目前这样的技术应用所适用的领域,与于未来的可能性会有哪些?
拓星研究所:这个技术其实可以应用到很多领域,简单举例像虚拟偶像的制作,博物管里名人的展示,影视作品里演员变年轻,变老,乃至已经去世的演员再次出现。所以,在未来,如果电脑的性能再上一层楼,那样一个演员能演一整部戏都不是问题。
结语
好了,采访内容就这么多。大家应该对其中的流程有所了解了。从专访内容我们可以看到,在硬件和软件配合的流程中,每一个都有一定的优缺点,而拓星研究所这次尝试的“以假乱真”的虚拟数字人的新玩法,或许能带给大家在寻找数字人技术路线时候一些新的启发,提到拓星研究所在整个方案中提到的支撑强大面部表情驱动的FACEGOOD,之前我们有介绍过他们家的技术,行业内小伙伴应该也都知道,我们就不多作介绍了,点击下方跳转原文。
Maya自动绑定实时推流UE5,可捕捉舌头动作!面部捕捉都精细到这种程度了?
全文完
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号CG世界 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
-

-
北京
甲方 · 媒体平台
未认证的机构号
recently released
-
2024-02-21
-
2024-01-12











