- 0
- 0
- 0
分享
- 网易互娱AI Lab 陈康:基于AI的美术资源生产,普遍比传统方案提升5-10倍的制作效率
-
2022-04-20







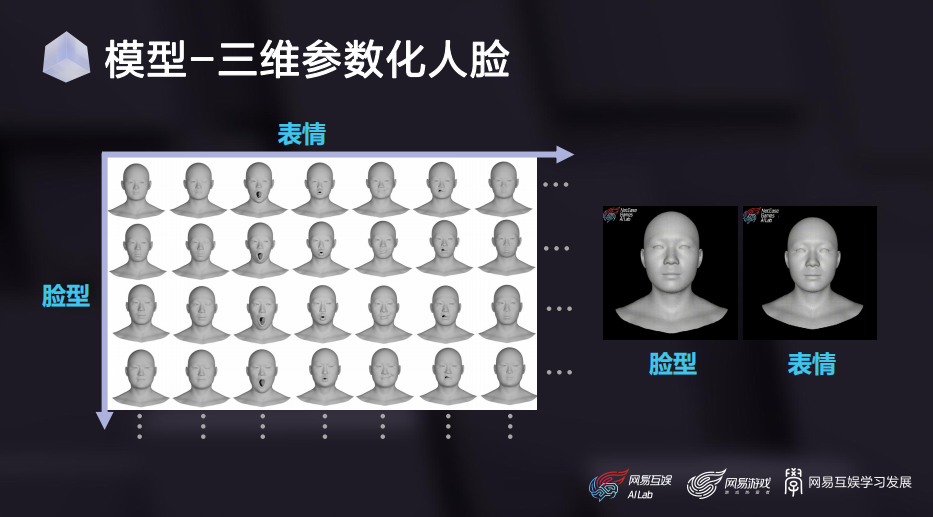

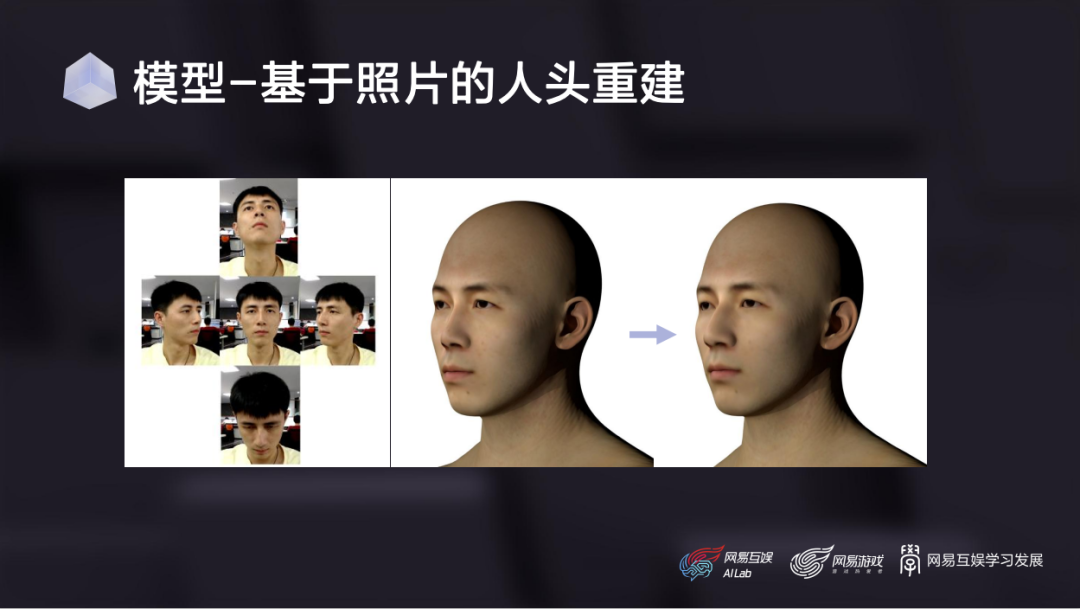
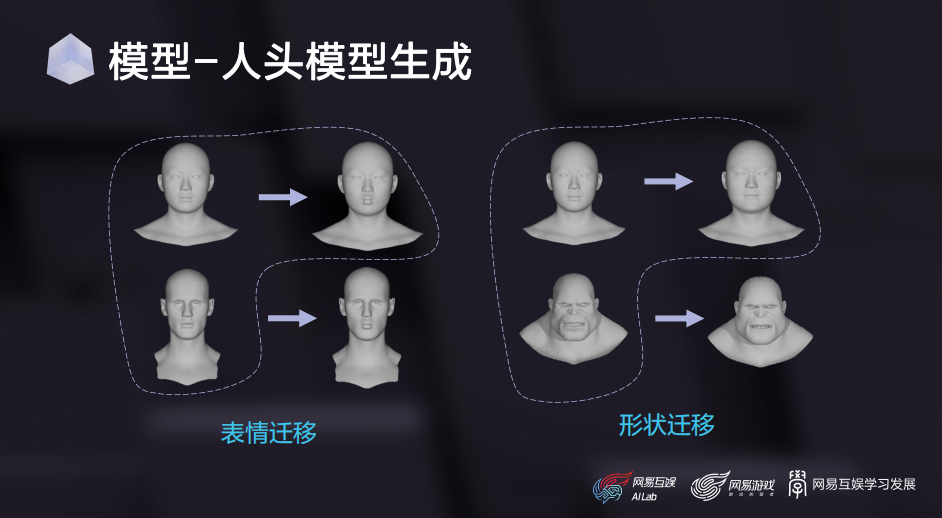



这是基于我们扫描流程制作的一组表情基的效果,可以看到,扫描模型对演员面部细节的还原程度是非常高的。
这套设备150组定制的LED灯光,也是我们花很高成本定做的。每一盏灯的开关和亮度可以独立控制,每一组灯光包含三个灯头,分别安装了一个普通无偏振的UV镜和两个偏振镜。这两个偏振镜相对于相机上安装的偏振镜方向一个是平行的,一个是垂直的。
了解摄影的同学应该很熟悉偏振镜的用法,这是一种很常用的UV镜,主要用于非金属物体表面一些不必要的反射光,可以还原物体本身的颜色。

偏振镜的原理大家在中学物理就学过——光既是粒子、也是一种电磁波,它的振动方向与传播方向是垂直的,这种类型的波叫横波,所有的横波都具有偏振现象。简单来讲,光的偏振方向与偏振镜方向平行,那么所有能量都会通过;如果是垂直的,那么所有能量都会被过滤。
基于这个原理,我们只要给扫描物体拍摄4组平行偏振光和4组交叉偏振光的灯光下照片,就可以算出物体表面的材质,也就是漫反射、高光和法线的信息。每组照片都要首先打开所有灯光,然后是按照灯光在三维空间的坐标值递减亮度,XYZ三个方向分别可以产生一组灯光。

目前这套设备我们刚刚搭建完成,在人脸材质扫描方面也是刚刚起步,后续我们会逐渐加大投入。
动画环节的AI技术:优化效率与成本,应用于批量动画生成、虚拟偶像与直播、营销等场景
最后是动画部分,这是我们这几年工作的重心。前面提到,游戏研发总成本的大头一般是美术资产,那么美术资产成本的大头一般就是动画。因为原画、模型虽然也很贵,但大部分属于一次性开销,而动画则需要配合剧情持续产出,且高质量动画一分钟的制作成本很轻松就可以过万。
在这方面,我们首先在光学动捕数据的清洗方面做了一些工作。光学动捕会在紧身动捕服表面设置很多标记点,通过多视角红外相机跟踪这些点的坐标,并算出人体骨骼的旋转、平移信息。当然,这些数据不可避免会有错误,所以会有专人负责清洗标记点。
资深的动捕美术直接看标记点的轨迹曲线,就能知道出现了什么错误、怎么修改,这也是目前动捕工作流中主要的人工工作量。
2018年,育碧提出了一种通过AI模型来取代这个过程的算法,发表在了SIGGRAPH上;2019年,网易投资了一家法国3A游戏工作室Quantic Dream,也就是《底特律:变人》的研发商。当时我们开始有一些技术合作,他们提出需求后,我们跟进了相关研究。一年多之后,我们找到了一种精度更高的解决方案,也发表在了SIGGRAPH上。
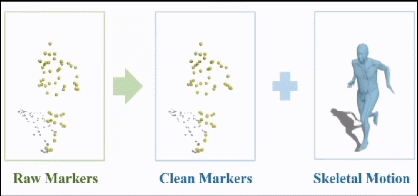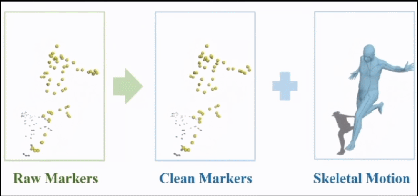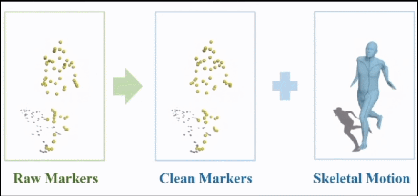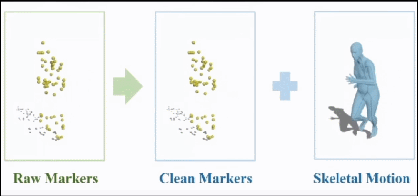
目前我们已经把这套算法,以vicon软件的插件形式部署在了网易互娱和Quantic Dream的动捕工作流中。这里是一个例子:这是原始含噪音的标记点,闪来闪去的就是局部噪音,留在原地的就是跟丢的那些点,这是暂时调用我们算法得到的清洗结果。
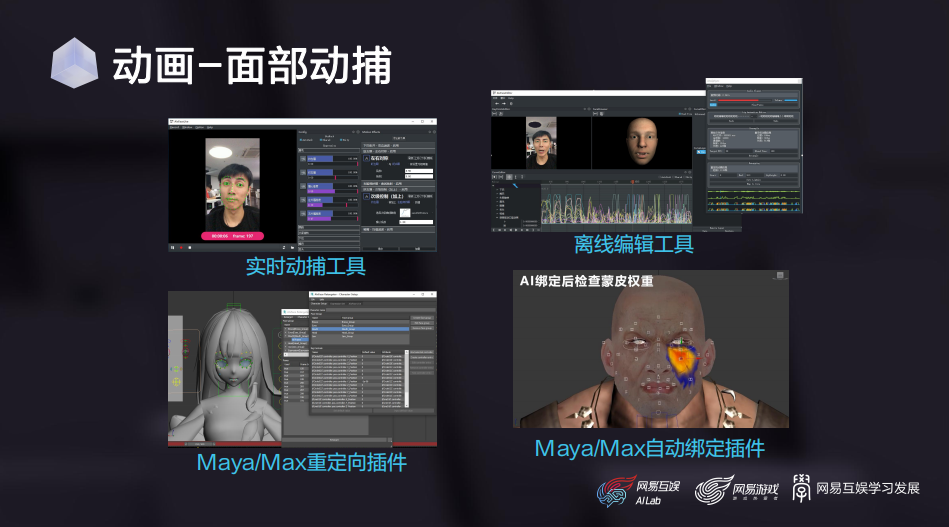
接下来介绍几个我们部门落地最多的项目:首先是一套基于普通单目摄像头的轻量级面部动捕系统,基本原理就是利用前面的三维参数化人脸模型,对视频中演员的脸型、表情头部姿态进行回归,把回归得到的系数重定向到游戏角色上。

当然,我们也会配合一些CV检测和识别模型,加强算法对眨眼、视线、舌头和整体情绪的捕捉精度。这个项目我们从2018年开始做,前前后后差不多有十位同事参与。其中所有算法模块都是我们自己开发,打磨到现在已经是一套非常成熟的in-house面部动捕解决方案。
围绕这套算法,我们还打造了一整套工具链,有实时的动捕预览工具,有针对动捕结果进行离线调整和编辑的工具,还有Maya/Max里的动捕数据重定向插件。另外为了方便项目组接入面部动捕系统,我们还开发了一套专门适配自家算法的面部自动绑定插件。此外,核心算法我们还打包了全平台的SDK,在iPhones 6s以上的机器,可以做到单核单线程实时。
这套系统在游戏里有非常多的应用场景,首先就是辅助动画师制作正式的游戏动画资源。相比于传统一帧一帧手key,采用动捕方案的制作效率有明显优势。而且只要演员表演到位,效果跟美术手key几乎看不出来区别;
其次,它可以给营销同学快速产出一些面部动画素材。营销场景的特点是精度要求没那么高,但时效性要求很高,因为慢了就跟不上实时热点了。我们这种轻量级方案非常适合这种场景,比如某段短视频火了,用这套工具可以快速产出面部动画素材;
另外,因为我们的算法会提供全平台SDK,所以也可以打包在游戏客户端里,给玩家提供一些UGC玩法。比如我们在《一梦江湖》里上线的颜艺系统,可以让玩家录制自己的表情动画。右上是我在B站上找到的一个视频——玩家录制的打哈欠动画;
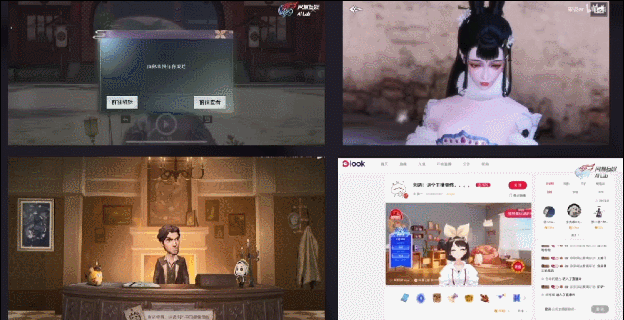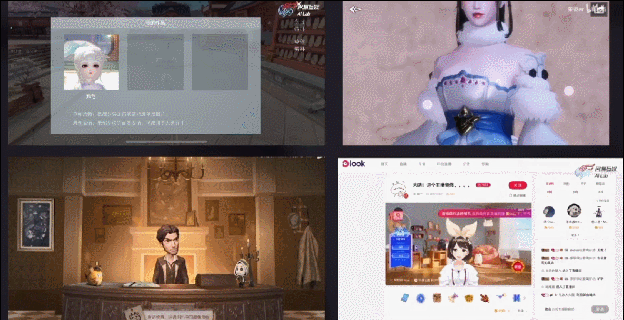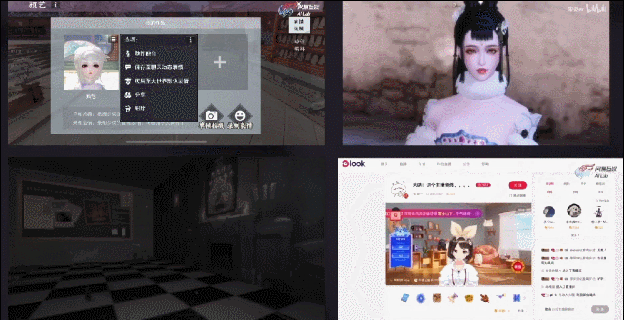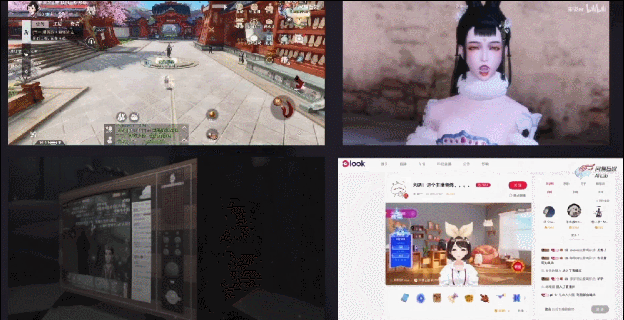
最后,这套算法还可以支持一些虚拟主播场景,比如《第五人格》秃秃杯电竞比赛的虚拟解说、云音乐look直播的虚拟主播,用的都是我们这套技术。
另外,我们还配合高精度三维扫描设备,测试了面部动捕算法在超写实模型上的效果。我们雇了一位国外模特扫描模型,用模特录制的视频来驱动他对应的角色,以便更好地对比表情还原度。

还有另外一组效果,这位模特是我们部门的一位同事。从效果上可以看到,不管是扫描重建还是面部捕捉,我们的技术都足够支持这种高精度场景。
跟面部动捕类似,我们也做了一套轻量级基于普通摄像头的身体动捕系统,支持单视角、多视角输入,原理类似于前面的面部捕捉,同样也会配合一些CV模型提升优化结果的合理性。这个项目我们打磨了两年时间,目前效果和稳定性都相当不错。
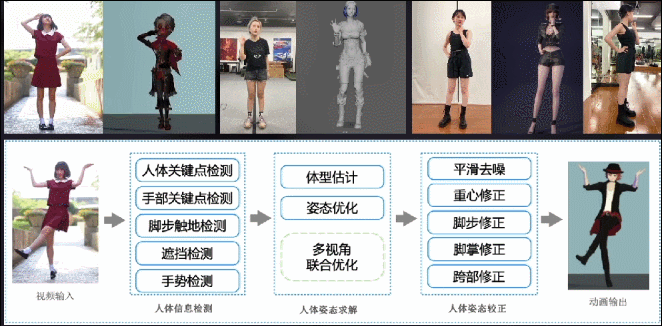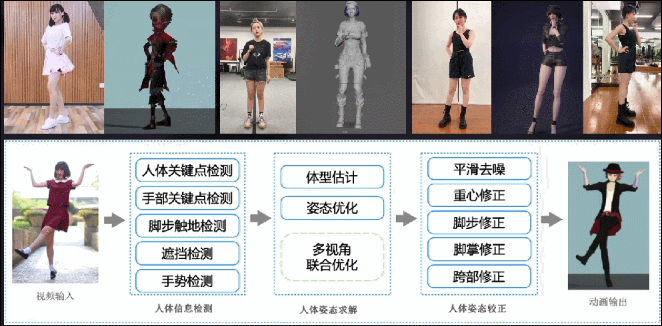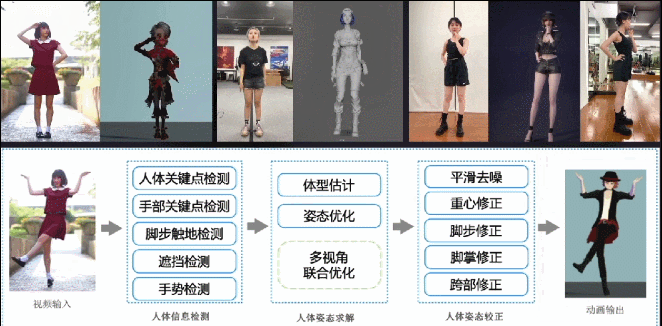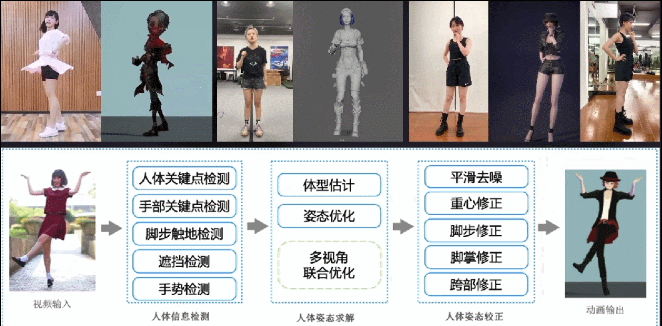
这是在冬奥结束之后,我们用这项技术为《哈利波特:魔法觉醒》项目制作的视频,当时很快就冲上了微博热搜。如果按传统制作方式,这种营销策划案是不太可能实现的,因为要找到能还原这套动作的演员,还要约演员和动捕棚的档期,一套下来没有六位数开销和一个多月制作周期的话,是很难完成的。但是用这套AI方案,成本就可以忽略不计。

这是更早时候,我们与《大话西游》项目组合作的一段视频。当时请了B站舞蹈区的一位知名Up主,用三部手机录了这套舞蹈动作,用我们的动捕算法得出数据,重定向到《大话西游》的角色上。

另外,我们还为《明日之后》项目组制作了一些动画素材,只用了一个单目摄像头捕捉身体和面部动作,并且只要拍得足够清晰,手指动作也可以准确捕捉。

除了基于视频输入以外,我们还做了基于音频输入生成动画的技术,比如从语音输入生成角色面部和肢体动画的工具链。这项技术我们在2018年就已经应用于不少游戏,当时做得还比较简单,只支持口型和几种简单的基础情绪。后来我们做了持续的基础升级和迭代,增加了语音驱动头动、眼动、手动、面部微表情,还有肢体动作等等。
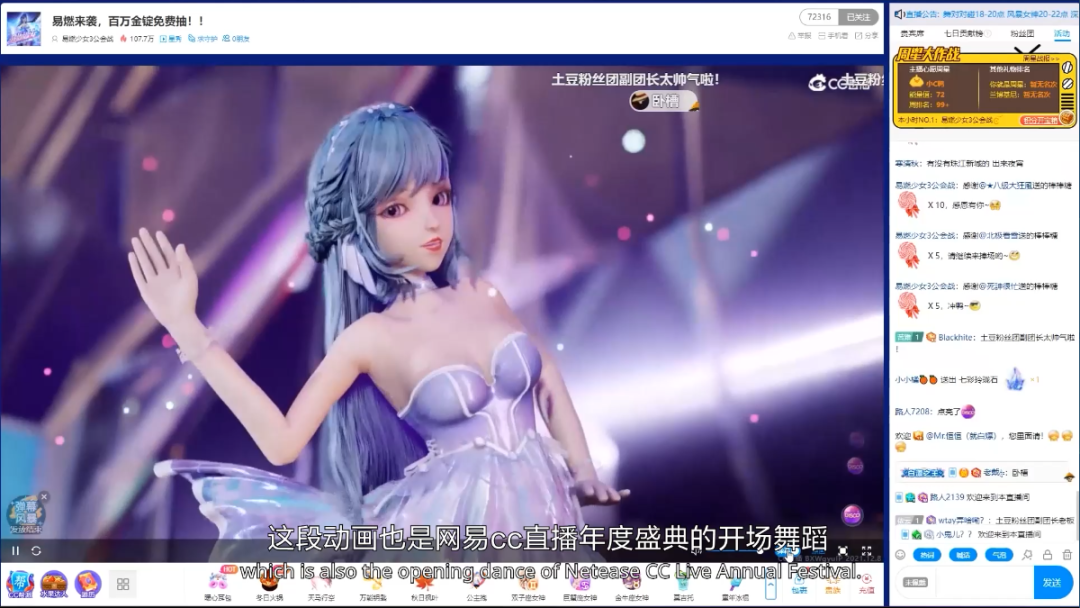
另一个从音频输入生成动画的工作,是基于音乐生成舞蹈动作。这项工作我们从2018年开始研究,经过几年迭代最终形成了一套方案,详细的技术方案在论文里有介绍,这里主要展示实际落地效果:首先是二次元女团舞;

这是一段韩舞的动画,也是网易CC直播年度盛典的开场舞蹈。
另外,我们也会用一些网络热门歌曲合成舞蹈。去年圣诞节时,我们用虚拟偶像I.F.制作的B站互动视频,其中所有动画都是通过AI技术生成的。目前这套AI动画的解决方案已经相当成熟,在内部经过了大量项目的验证,目前也在持续为网易的各个项目组输出动作资源。
数据是AI的核心
最后简单总结一下,从前面的介绍中大家可以发现,AI技术对程序化美术资源生成能产生明显的促进作用。而且根据我们的实践经验,在人脸、人体的模型和动画方面,它甚至可以在一定程度上取代一些初级执行向美术的工作。而且利用我们的AI方案,普遍可以比传统方案提升5-10倍的制作效率。
但目前想让AI从事一些更高级的工作还比较困难。主要难点是高质量数据比较稀缺,大家都知道数据是AI的核心,AI模型有多少能力,很大程度上取决于人给了模型多少有价值的数据。但是游戏资产的获取门槛还是很高的,这跟照片、语音、文字这种所有人日常都在生产的数据不太一样。
比如在某个景点看到一个很有特色的雕塑,绝大部分人的反应可能是掏出手机,拍一张照片记录一下,但几乎不会有人掏出电脑现场建个模。当然,随着技术进步,游戏资源的制作门槛肯定会越来越低,而且像元宇宙这样的热门应用场景,本身也要求游戏厂商让广大玩家参与到虚拟世界的内容创造过程中来。
所以我相信,随着数据的持续积累,未来AI技术也有可能从事一些更高级的工作,这也是我们的努力方向,谢谢大家。


-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号共同虚拟 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
-

-
上海
甲方 · 垂直媒体
未认证的机构号
最近发布
-
2024-01-11
-
2023-12-12








