
- 0
- 0
- 0
分享
- 英伟达连甩20枚AI核弹!800亿晶体管GPU、144核CPU来了
-
2022-03-26






▲格蕾丝·赫柏正在教学COBOL编程语言

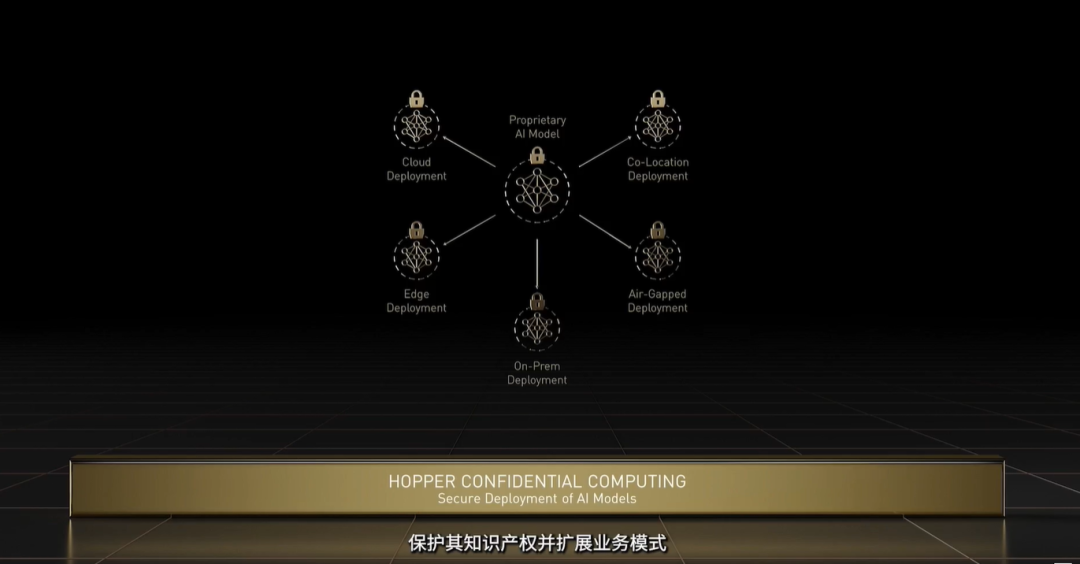
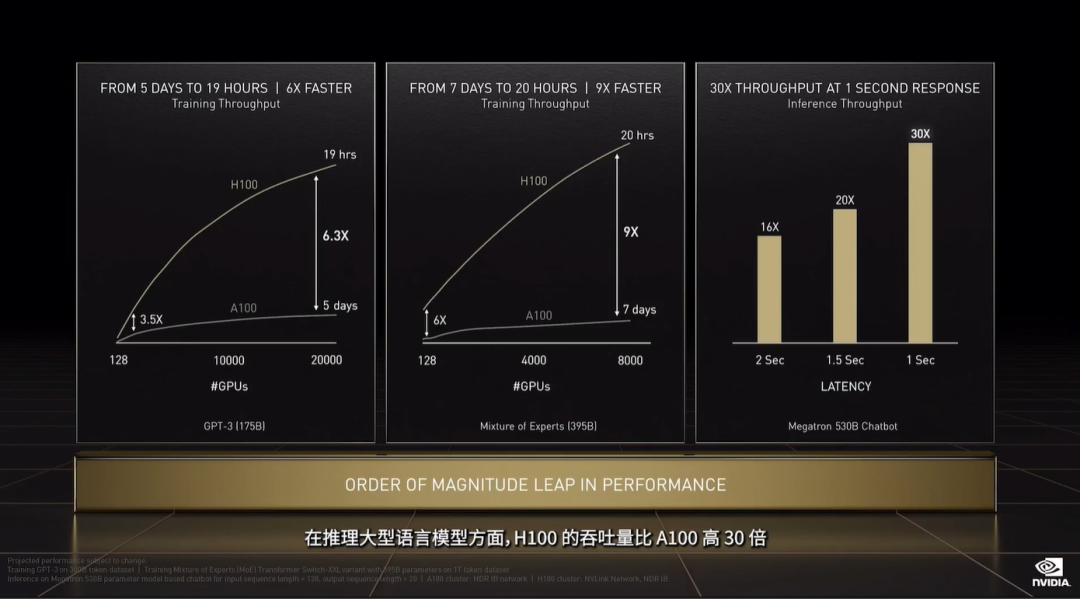










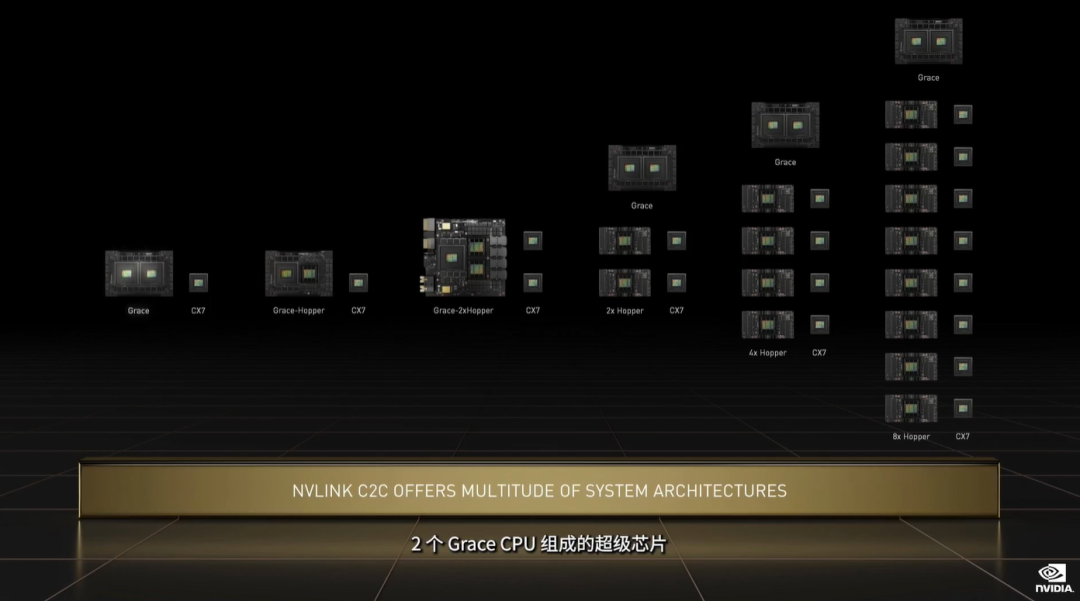
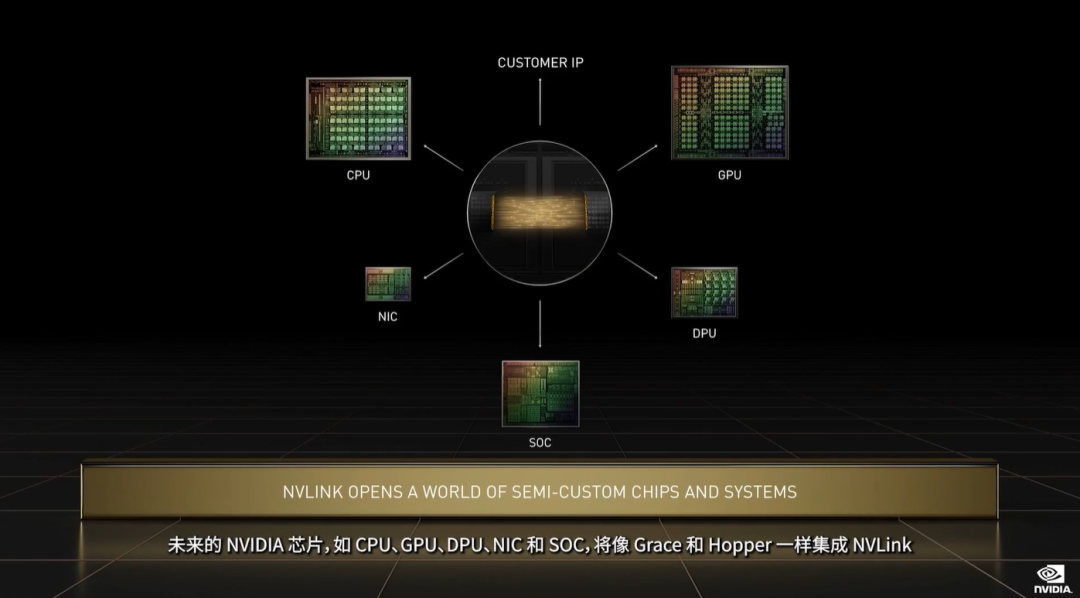
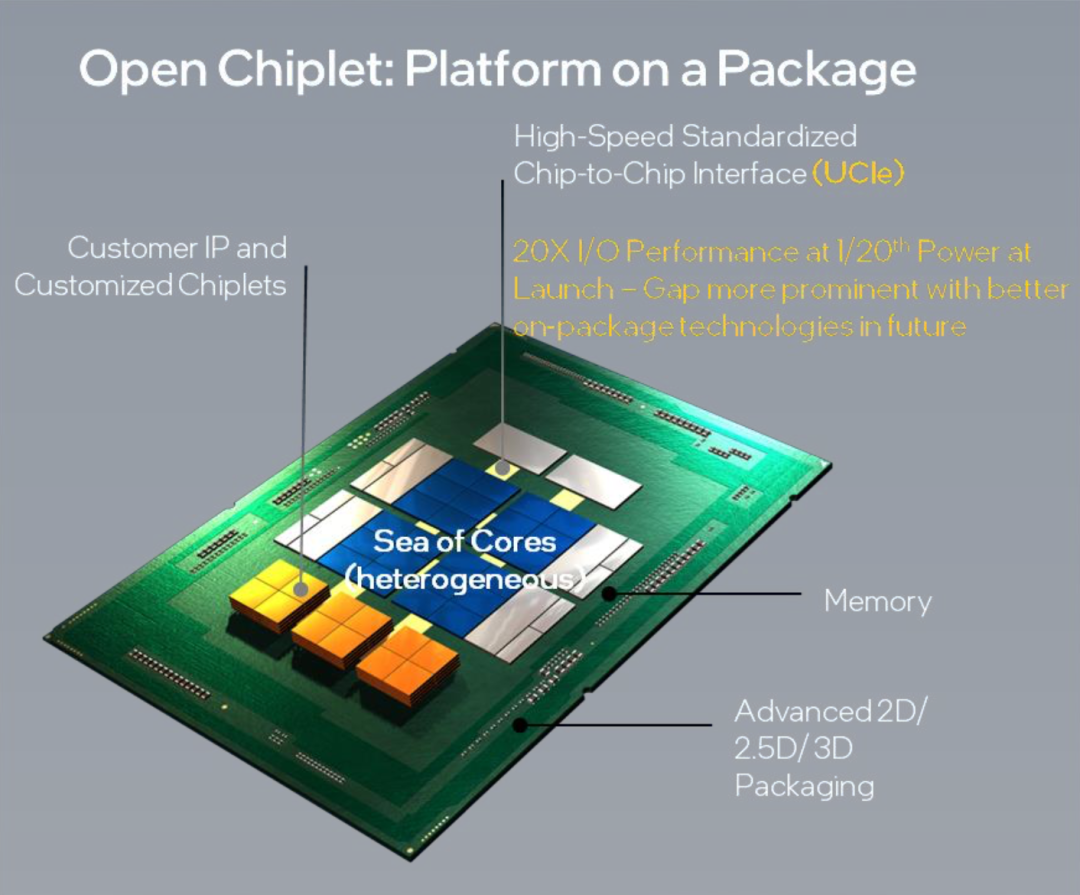
▲UCIe标准



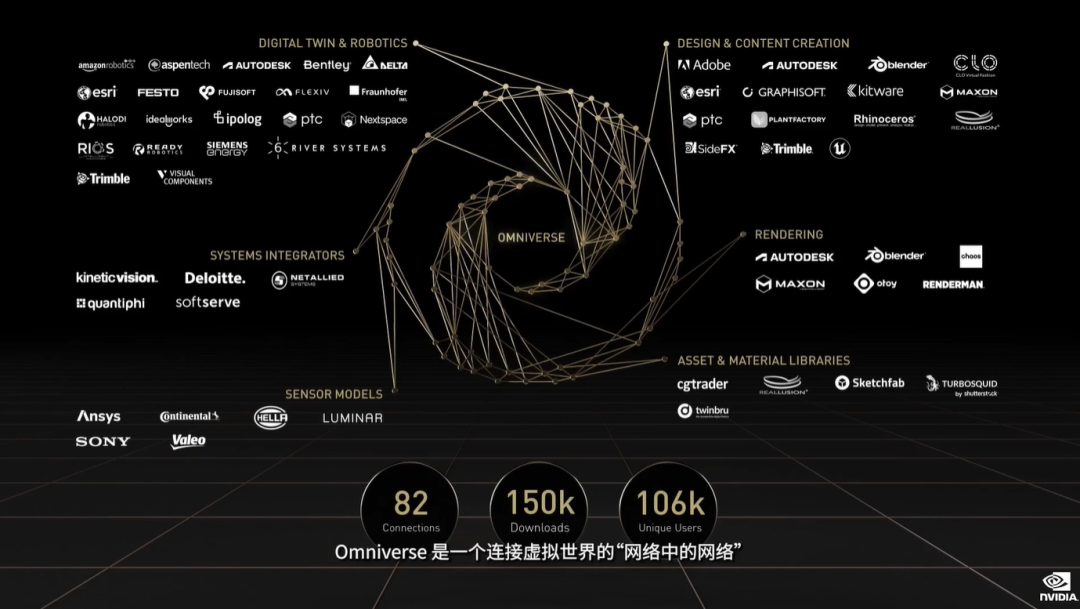




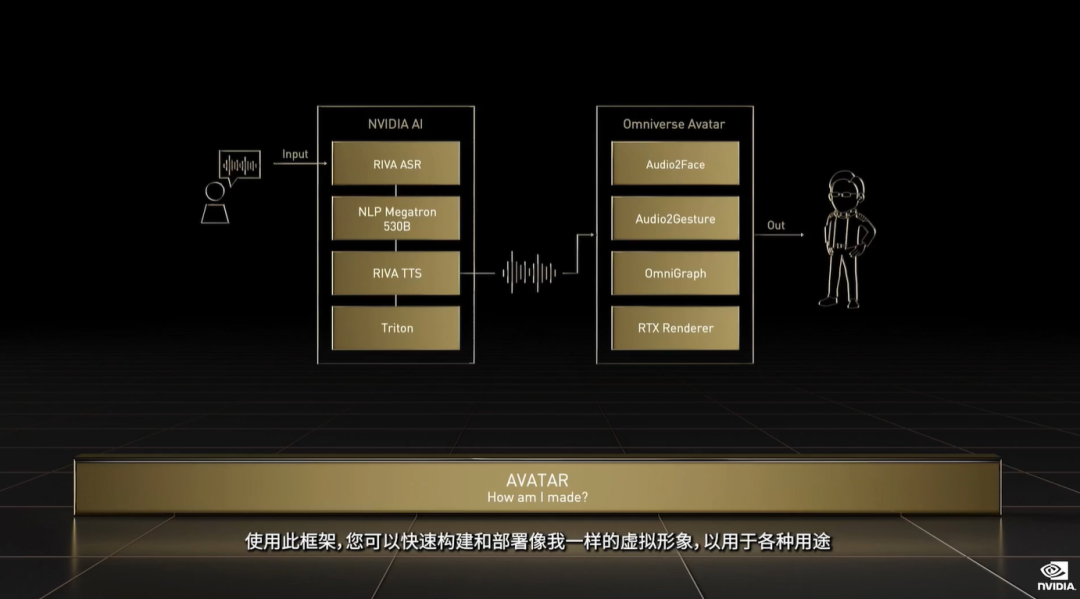



end
-
阅读原文
* 文章为作者独立观点,不代表数艺网立场转载须知
- 本文内容由数艺网收录采集自微信公众号CG世界 ,并经数艺网进行了排版优化。转载此文章请在文章开头和结尾标注“作者”、“来源:数艺网” 并附上本页链接: 如您不希望被数艺网所收录,感觉到侵犯到了您的权益,请及时告知数艺网,我们表示诚挚的歉意,并及时处理或删除。
16555
举报
0
-

-
北京
甲方 · 媒体平台
未认证的机构号
recently released
-
2024-02-21
-
2024-01-12











