虚拟邓丽君 - 数字王国
2022年江苏卫视跨年晚会上,一身优雅深蓝色旗袍的邓丽君与周深一起演绎了《小城故事》,《漫步人生路》,《大鱼》3首歌,让不少观众直呼感动。不得不说,无论是形象还是声音,还原程度都非常之高,更是有不少人惊叹,如今数字人技术已经到了如此高的地步。然而,有眼尖的网友注意到,制作片花里某个角落,提到了邓丽君是由陈佳配音的,这引来了网友一片吐槽,那么现在我们是否可以做到模拟真人唱歌呢?
想要数字人自己可以唱歌的话,就不得不说一下歌声合成技术了
歌声合成技术就是指使用机器模拟人类唱歌的技术,这项技术历经几百年的发展,经历了数个阶段,大致可以分为三种类型:# 拼接合成

拼接合成很好理解,也是最为直观的方法,事先录制好一个采样声库,然后合成时在声库中寻找对应的采样最终拼接为一首完整的歌声。这里面主要有三个技术难点- 采样的处理:
合成时,要对采样进行一些处理,比如最常见的变调,拉伸等,还有一些更细致的调教参数,如气息度等。
- 声库的设计:
如何设计声库,可以使用尽量少的数据应对合成过程中的各种复杂组合,还要保持很高的自然度。
- 拼接的处理:
采样拼接时,如何处理可以最大化的做到平滑无缝感
说到拼接合成就不得不说一下VOCALOID和Utau,VOCALOID是第一个将这项技术代入公众视野的软件,其中也产生了目前最著名的虚拟偶像:初音未来。VOCALOID是日本YAMAHA公司自主开发的一款电子歌声合成软件,输入音调和歌词,就可以合成贴近人类声音的歌声。
UTAU,正式名称为歌声合成工具UTAU(歌声合成ツールUTAU),是一款由饴屋/菖蒲氏开发制作的音声合成软件。
而Utau是使用范围最广的免费软件,由于这款软件诞生了B站鬼畜区,也产出了不少经典的作品。由于拼接合成的原理,导致它也存在一些局限性,比如声库制作的复杂性,需要大量的结构化数据以及合成后歌声自然度不足,非常依赖后期调教等。# 参数合成
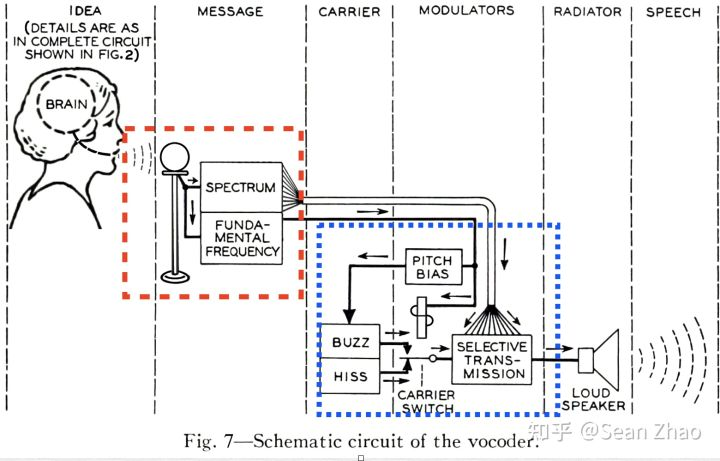
与通过拼接直接产生音频不同,参数合成的思想是先产生一些合成音频必要的声学参数,然后再利用这些参数最终合成音频,从参数到音频这一步通常是由声码器(vocoder)来完成的。目前应用最广泛的基于算法的声码器就是WORLD了,它是基于source-filter模型的,即把发声过程抽象成了声源和滤波器两个部分,我们在唱歌时,声源即声带,而滤波器是我们的口腔,鼻腔等,我们通过改变声带振动频率来唱出不同的音高,再通过改变嘴型来唱出不同的歌词。所以WORLD所需要的声学参数就是基频(f0)和频谱包络了,其中基频作为声源,而频谱包络担当滤波器的角色。事实上,WORLD合成声音时还需要一些非周期信息,它们代表了我们声音里非周期部分的占比,而非周期部分说人话就是白噪声,比如呼吸声就是白噪声。
在歌声合成过程中,声学参数通过乐谱和歌词来产生,直白一点来讲,乐谱最终会产生基频(f0),频谱包络还需要歌词信息,产生的过程分为了两个时期,前期一般采用统计模型来计算,比如隐马尔科夫模型(HMM),后期由于深度神经网络的发展,大部分采用DNN或者RNN的方式生成。
# 深度神经网络
随着深度神经网络在图像以及tts方面取得了巨大的成功,不少研究也尝试使用深度神经网络来进行歌声合成。它并不是一个单独的方法,而是根据前述的一些思想将某些步骤替换为使用深度神经网络来完成。比如前述的基于深度神经网络的声学参数生成。当然,我们也可以全部步骤都使用深度神经网络,或者将一些步骤进行合并,甚至可以达到端到端的歌声合成。使用深度神经网络合成的歌声到底效果如何呢,先来看一个视频吧不知道各位听了以后是什么想法,这样的歌声效果完全是通过深度神经网络模型合成而来的,感兴趣的朋友可以自己下载app体验。为了达到这样的效果,我们并没有采用端到端的合成技术,而是将参数合成的思想与深度神经网络结合,将歌声合成分成了几个关键步骤,每个步骤训练一个深度神经网络模型,最终获得歌声音频。采用这种方式,不仅可以获得神经网络的效果,而且还可以支持很多维度的参数调节,从而获得更多有趣的可能性。
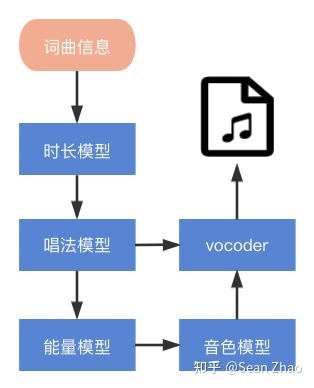
这里先说几个概念,汉语中一个字的发音对应一个音节,而一个音节可以分为多个音素,音素是语音学上划分的最小单位,我们汉语中总共有400多个音节,而音素只有几十个,为了让模型更快的学到发音的规律,使用音素作为输入是最佳的选择,所以当我们要把一段曲谱变为歌声时,需要先把歌词转换为音节,然后再把音节转换为音素信息。曲谱中一个音节的时长已经规定好了,但是音节分为音素时,时长怎么决定呢?这个时候就需要时长模型来确定了,音素分为元音和辅音,时长模型会根据不同音素的类型,以及上下文来规划每个音素占用音节的时长。唱法模型主要用于决定如何演绎一段音符,比如有的歌手会习惯性在长音的结尾出加一点点颤音等,唱法模型最终的产物也是基频(f0)能量模型主要关注音量的变化,其实也可以认为是唱法的一部分。音色模型会从前面的模型获取输入,最终产生音频的频谱信息,比如mel谱。这个模型也是决定是否可以生成足够拟真的歌声的最重要的一个模型。与前面介绍的WORLD不同,我们这里使用了基于深度神经网络的vocoder基于mel谱生成音频,从而摆脱了WORLD合成音频后的那种过度平滑的感觉,而且由于歌声对于音高的准确度要求极高,所以我们还额外给了vocoder基频信息,这样可以保证生成的音频不会因为模型”随意发挥“而走调。到这里,我相信对于机器是否可以模拟真人唱歌,大家心中已经有了答案。随着科技的进步,越来越多以前不敢想象的事情成为了可能,或许未来的某一天,每个人都可以拥有一个自己的虚拟化身,在虚拟的世界替自己完成儿时的梦想。专栏作者
Sean Zhao
AI算法工程师/游戏开发工程师/全栈
知乎:www.zhihu.com/people/sean-zhao-11
学到了!欢迎大家加入我们的社群#算法作曲,探索AI音乐方向。